[Spring] Spring 에서 Kafka를 통한 비동기 통신 구현해보기
Spring 에서 Kafka를 통한 비동기 통신 구현해보기
비동기 통신
애플리케이션 간 비동기 메시지 큐를 이용한 통신 방식은 간접 계층을 제공하여 애플리케이션 간의 결합도는 낮추면서 확장성을 높힌다. 비동기 통신은 시스템 간 독립성을 높이고, 처리 속도를 개선하며, 확장성을 확보할 수 있다는 점에서 현대 분산 시스템에서 중요한 설계 패턴으로 자리 잡고 있다.
Kafka 소개
Kafka 는 비동기 통신을 할 수 있는 방법 중 하나이다. Kafka는 LinkedIn에서 개발된 분산 메시징 시스템이다. 대량의 데이터를 높은 처리량과 낮은 대기 시간으로 안정적으로 처리하기 위해 설계되었다고 한다. Kafka는 실시간 스트리밍 데이터 처리와 이벤트 중심 아키텍처에 적합하며, 로그 집계, 메트릭 수집, 데이터 파이프라인 등 다양한 데이터 중심 애플리케이션에서 널리 사용되고 있다. Kafka는 메시지를 토픽(topic)으로 구성하고, 이를 Producer가 게시하고 Consumer가 구독하는 모델을 채택하였다. 데이터는 로그 형태로 유지되며, 데이터의 영구 보관 및 재처리가 가능하다는 점이 다른 메시지 큐와의 차별점이다.
Kafka 주요 개념 정리
spring 에서 kafka를 구현하기 전에 먼저 kafka 를 구현할 때 알아야 할 주요 개념들을 간단하게 정리해본다.
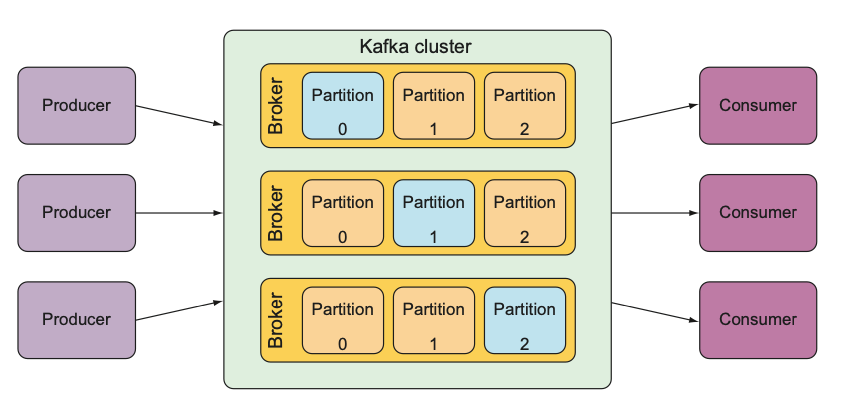
위 그림은 Kafka의 주요 구성 요소 간 관계를 보여준다.
- Producer : 카프카에서 데이터를 발행하는 클라이언트
- Consumer : 카프카에서 메시지를 읽는 클라이언트
- Consumer Group : 데이터를 병렬로 처리하기 위해 사용하며, 동일 그룹의 Consumer는 서로 다른 Partition 데이터를 읽는다.
- Broker : 카프카 서버의 개별 인스턴스
- Producer는 Broker로 데이터를 전송하며, Consumer는 Broker로부터 데이터를 가져옵니다.
- Cluster : 브로커들로 구성된 카프카 인스턴스 집합
- Topic : 데이터의 카테고리 (메시지/이벤트 를 구분하는 단위)
- 카프카의 토픽들은 1개 이상의 파티션으로 구성된다.
- Partition : 메시지를 저장하는 물리적인 파일
- 파티션 수가 늘어나면 더 많은 컨슈머를 병렬로 연결할 수 있다.
- 각 파티션은 독립적으로 메시지를 저장한다. 데이터들은 파티션에 분산되어 저장된다.
- 파티션 내에서 메시지의 순서는 보장되지만, 다수의 파티션에 분산된 데이터 간에는 순서가 보장되지 않는다.
- bootstrap server : 클라이언트가 Kafka 클러스터에 처음 접속하기 위해 사용할 브로커 주소
Topic 쉽게 이해하기
아파트에 있는 우편함을 떠올려보자.
- 집배원(Producer): 아파트의 각 호수에 따라 우편함에 우편물(Message)을 배달한다.
- 입주민(Consumer): 자신의 주소에 해당하는 우편함에서 우편물을 가져간다.
- 우편함(Topic): 각 호수는 특정한 데이터 카테고리(Topic)에 해당한다.
RabbitMQ 와 Kafka 비교
RabbitMQ 와 Kafka 는 메시징 큐를 이용한 시스템이기 때문에 쉽게 비교의 대상이 된다.
하지만 둘은 서로 경쟁하는 관계는 아니다. 상황에 따라 써야 한다.
둘의 차이를 이해하기 위해 여러 자료들을 읽어보았고, 그 중 aws doc : Kafka와 RabbitMQ의 차이점은 무엇인가요? 라는 글이 가장 큰 도움이 되었다.
RabbitMQ 와 Kafka에 를 간단하게 정리해보면 다음과 같다.
- RabbitMQ (push 방식)
- 설계 철학: 실시간 메시지 전달.
- 작업 큐(Task Queue)로 주로 사용되며, 특정 작업이 완료되면 메시지를 삭제.
- 메시지를 빠르게 컨슈머에게 전달하는 데 중점.
- Kafka (polling 방식)
- 설계 철학: 이벤트 스트림 프로세싱.
- 대량 데이터 처리에 최적화, 메시지 처리가 느린 경우에도 데이터를 손실 없이 유지.
- 컨슈머는 처리 속도를 조정할 수 있음.
둘의 차이점에 대해서는 위에서 소개한 문서에 다음과 같이 적혀있는데, 정말 잘 적은 설명같아서 가져와본다.
RabbitMQ의 생산자는 메시지를 보내고 메시지가 의도한 소비자에게 도착하는지 모니터링합니다. 반면 Kafka의 생산자는 소비자가 메시지를 검색했는지 여부에 관계없이 메시지를 대기열에 게시합니다. RabbitMQ는 우편물을 받아서 수취인에게 배달하는 우체국이라고 생각하시면 됩니다. 반면 Kafka는 생산자가 게시하는 다양한 장르의 메시지를 진열대에 정리하는 도서관과 비슷합니다. 그 후 소비자는 각 진열대에 진열된 메시지를 읽고 읽은 내용을 기억합니다.
요약하자면, RabbitMQ 는 실시간 메시지 전달이 필요한 경우에 적합하고, Kafka 는 대량 데이터를 처리하며 이벤트 스트림에 적합하다.
Spring 에서 Kafka를 통한 통신 구현해보기
Kafka 를 통해 통신할 때는 Producer와 Consumer 가 있게된다. 따라서 아래 예제에서는 Producer와 Consumer 로 나눠서 설명한다.
다음과 같은 예시를 생각해보았다.
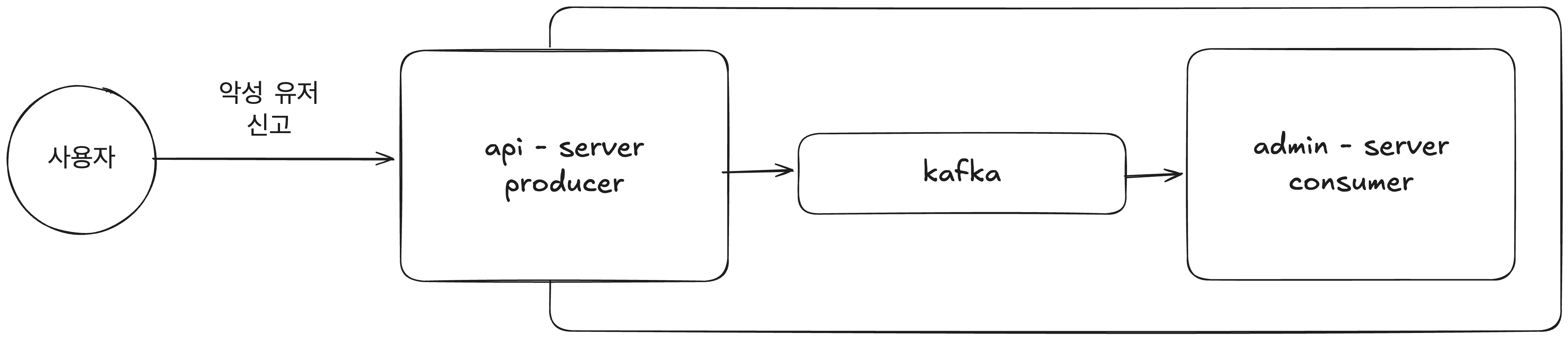
- 사용자는 api server 를 통해 악성 유저를 신고한다.
- api server 는 kafka 로 event 를 produce 한다.
- admin server 는 kafka 로 부터 event 를 consume 하여 관리자에게 알림을 보낸다.
kafka 로 통신할 때는 key와 value의 serializer 와 deserializer 를 적절히 선택해주는것이 중요하다. 여기서는 간단하게만 구현할 예정이기 떄문에 key 는 string을 value는 json을 사용하는것으로 하겠다.
Docker 로 Kafka 실행하기
본격적으로 Spring 에서 Kafka 통신을 구현하기 위해 먼저 kafka 를 실행시킨다.
docker run -d -p 9092:9092 --name broker apache/kafka:latest
이벤트를 위해 사용할 객체
@Getter
@Setter
@ToString
public class Report {
private String reporterUuid;
private String targetUuid;
private String reason;
}
producer 구현
application.yaml 설정
spring:
kafka:
producer:
bootstrap-servers: localhost:9092 # Kafka 브로커 주소
kafka produce config
@EnableKafka
@Configuration
public class KafkaProducerConfig {
private final String bootstrapServers;
public KafkaProducerConfig(Environment environment) {
this.bootstrapServers = environment.getProperty("spring.kafka.producer.bootstrap-servers");
}
private Map<String, Object> getDefaultConfig() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return config;
}
@Bean
public ProducerFactory<String, Report> reportProducerFactory() {
return new DefaultKafkaProducerFactory<>(getDefaultConfig());
}
@Bean
public KafkaTemplate<String, Report> reportKafkaTemplate() {
return new KafkaTemplate<>(reportProducerFactory());
}
}
report service (kafka template 사용)
@Slf4j
@Service
@AllArgsConstructor
public class ReportService {
private final KafkaTemplate<String, Report> reportKafkaTemplate;
public void sendReport(Report report) {
reportKafkaTemplate.send("user.report", report);
log.debug("Report message sent: {}", report);
}
}
reportKafkaTemplate.send 를 통해 메시지를 kafka 로 전달한다.
consumer 구현
application.yaml 설정
spring:
kafka:
consumer:
group-id: admin
bootstrap-servers: localhost:9092
server:
port: 0 # application 실행시 spring 기본 포트 8080 이 중복되는걸 방지하고자 random port를 사용하도록 0으로 설정 하였다.
consumer 에서는 group-id 를 기본적으로 지정 해줘야 한다. 여기서 consumer 는 admin 서버이기 때문에 admin 으로 설정하였다.
kafka consumer config
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
private final String bootstrapServers;
private final String groupId;
public KafkaConsumerConfig(Environment environment) {
this.bootstrapServers = environment.getProperty("spring.kafka.consumer.bootstrap-servers");
this.groupId = environment.getProperty("spring.kafka.consumer.group-id");
}
private Map<String, Object> getDefaultConfig() {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
config.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
config.put("spring.json.trusted.packages", "*");
return config;
}
@Bean
public ConsumerFactory<String, Report> userReportConsumerFactory() {
Map<String, Object> config = getDefaultConfig();
config.put("spring.json.value.default.type", Report.class.getName());
return new DefaultKafkaConsumerFactory<>(config);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Report> userReportKafkaListener() {
ConcurrentKafkaListenerContainerFactory<String, Report> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(userReportConsumerFactory());
return factory;
}
}
kafka listener
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics="user.report", containerFactory = "userReportKafkaListener")
public void handleUserReport(Report userReport) {
log.debug("report: {}", userReport);
sendNotificationToAdmin(userReport);
}
}
결과 확인
api server 에서 ReportService.sendReport 를 실행하여 admin server 의 KafkaConsumer.handleUserReport 가 수행된 것을 확인하면 정상적으로 통신이 진행된 것이다.
마무리
이 글에서는 기본적인 구현 예제를 다뤘지만, 실시간 스트리밍 데이터 처리나 복잡한 토픽 구성 등 다양한 시나리오로 확장할 수 있다.
우선은 이번 내용을 정리하면서 RabbitMQ 와 Kafka 의 차이에 대해서 좀 더 알게되어서 좋았다. 잘 기억해둬야겠다.
현재 회사에서도 kafka를 사용중에 있는데 다른사람이 이미 구현해둔 것을 기반으로 하여 구현하는 것과 처음부터 구현해보는 것은 또 다른 경험이였던것 같다.