[Spring] Spring In Action - 데이터로 작업하기 (3장)
데이터로 작업하기
관련 개념 정리하기
domain 과 entity 의 차이
- domain : 핵심 비즈니스 개념을 추상화한 객체, 비즈니스 로직과 규칙을 표현
- entity : 데이터베이스 테이블에 대응하는 클래스
각 entity 인스턴스는 테이블 row 와 연결된다.
도메인 객체는 반드시 데이터베이스와 매핑될 필요는 없다. 도메인 객체는 엔티티일 수도 있고 아닐 수도 있다.
객체 영속성 (Object Persistence)
영속성 永續性 Persistence : (명사) 영원히 계속되는 성질이나 능력.
개별 객체가 애플리케이션 프로세스보다 오래 유지될 수 있음을 의미한다. 각 객체는 데이터 저장소에 저장했다가 나중에 특정 시점에서 다시 생성할 수 있다. 일반적으로 SQL을 사용해 데이터베이스의 객체 인스턴스를 매핑하고 데이터베이스에 저장하는 것을 의미한다.
Repository 와 DAO
repository 와 dao 는 거의 같다.
좀 더 깊이있게 차이를 설명하면, repository는 엔티티 객체를 보관하고 관리하는 저장소이고, dao는 데이터에 접근하도록 DB접근 관련 로직을 모아둔 객체이다.
둘은 개념의 차이일 뿐 실제로 개발할 때는 비슷하게 사용된다.
https://www.inflearn.com/community/questions/111159/domain%EA%B3%BC-repository-%EC%A7%88%EB%AC%B8
자바 개발자가 관계형 데이터를 사용하는 대표적인 방법
- JDBC 기반 : SQL을 직접 제어
- JPA 기반 : 객체 지향적인 방식, ORM (Object-Relational Mapping) 방식 사용.
- 자동으로 SQL이 생성되어 편리하나, 최적화하는데 어려움이 있다.
두 가지를 상황과 필요에 따라 잘 사용하는 것이 좋다.
JDBC
https://en.wikipedia.org/wiki/Java_Database_Connectivity
JDBC(Java DataBase Connectivity)는 클라이언트가 데이터베이스에 액세스하는 방법을 정의하는 Java API 이다.
JDBC Driver
JDBC 드라이버는 JDBC API를 기반으로 구현된 소프트웨어이다. 애플리케이션이 개별 데이터베이스와 상호 작용할 수 있도록 돕는다. 각 데이터베이스에 맞는 전용 드라이버가 필요하다. JDBC 드라이버에는 데이터베이스에 대한 연결 관리 기능과 클라이언트와 데이터베이스 간에 쿼리 및 결과를 전송하기 위한 프로토콜이 구현되어 있다.
순수 JDBC 를 이용해서 데이터 읽어오기 (코드 예시)
아래 코드는 JDBC를 이용하여 데이터를 읽어오는 코드의 예시이다.
@Override
public Optional<Ingredient> findById(String id) {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
connection = dataSource.getConnection();
statement = connection.prepareStatement(
"select id, name, type from Ingredient where id=?");
statement.setString(1, id);
resultSet = statement.executeQuery();
Ingredient ingredient = null;
if(resultSet.next()) {
ingredient = new Ingredient(
resultSet.getString("id"),
resultSet.getString("name"),
Ingredient.Type.valueOf(resultSet.getString("type")));
}
return Optional.of(ingredient);
} catch (SQLException e) {
// ??? What should be done here ???
} finally {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {}
}
}
return Optional.empty();
}
select id, name, type from Ingredient where id=? 한 줄을 수행하기 위해 굉장히 많은 코드가 사용되었다는 것을 볼 수 있다.
Spring 에서는 JDBC를 좀 더 쉽게 사용할 수 있는 방법을 제시한다.
Spring JDBC
https://spring.io/projects/spring-data-jdbc
Spring JDBC는 Spring Data의 일부로 JDBC 기반의 레포지토리를 쉽게 구현할 수 있도록 돕는다.
JdbcTemplate를 사용해서 데이터베이스 쿼리하기
Spring JDBC의 JdbcTemplate 을 사용하면 상용구(boilerplate) 코드가 확 줄일 수 있다.
private JdbcTemplate jdbcTemplate;
public Optional<Ingredient> findById(String id) {
List<Ingredient> results = jdbcTemplate.query(
"select id, name, type from Ingredient where id=?",
this::mapRowToIngredient,
id);
return results.size() == 0 ?
Optional.empty() :
Optional.of(results.get(0));
}
JdbcTemplate을 사용하는 Repository 만들기
JdbcTemplate을 사용하는 Repository는 다음과 같이 구현할 수 있다.
- Repository Interface 정의
- JdbcTemplate을 사용하는 Repository 구현
1. Repository Interface 정의
필요한 인터페이스를 정의한다.
public interface IngredientRepository {
Iterable<Ingredient> findAll();
Optional<Ingredient> findById(String id);
Ingredient save(Ingredient ingredient);
}
2. JdbcTemplate을 사용하는 Repository 구현
이전 단계에서 정의한 인터페이스를 구현한다.
@Repository
public class JdbcIngredientRepository implements IngredientRepository {
private JdbcTemplate jdbcTemplate;
public JdbcIngredientRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public Iterable<Ingredient> findAll() {
return jdbcTemplate.query(
"select id, name, type from Ingredient",
this::mapRowToIngredient);
}
@Override
public Optional<Ingredient> findById(String id) {
List<Ingredient> results = jdbcTemplate.query(
"select id, name, type from Ingredient where id=?",
this::mapRowToIngredient,
id);
return results.size() == 0 ?
Optional.empty() :
Optional.of(results.get(0));
}
@Override
public Ingredient save(Ingredient ingredient) {
jdbcTemplate.update(
"insert into Ingredient (id, name, type) values (?, ?, ?)",
ingredient.getId(),
ingredient.getName(),
ingredient.getType().toString());
return ingredient;
}
private Ingredient mapRowToIngredient(ResultSet row, int rowNum) throws SQLException {
return new Ingredient(
row.getString("id"),
row.getString("name"),
Ingredient.Type.valueOf(row.getString("type")));
}
}
@Repository 어노테이션을 달면 Component Scan 시 자동으로 검색되어 Spring Appliaction Context에서 빈으로 등록된다.
(질문) 왜 굳이 인터페이스와 실제 구현클래스를 나눠뒀을까?
- Repository의 인터페이스를 통해 의존성을 주입받음으로써, 실제 구현체의 변경이 클라이언트 코드에 영향을 미치지 않도록 할 수 있다.
- 다른 구현체로도 변경하기 용이하다.
- 테스트에 용이하다.
- 인터페이스를 Mocking 하면 실제 Object를 사용하는것보다 세부 구현에 대한 의존성을 줄일 수 있다.
또 다른 findById 구현 방법
queryForObject 를 사용하는 것도 한가지 방법이다.
@Override
public Ingredient findById(String id) {
return jdbcTemplate.queryForObject(
"select id, name, type from Ingredient where id=?",
this::mapRowToIngredient,
id);
}
이 코드는 좀 더 간결하긴 하지만 값이 없거나, 단일 row가 아닐 경우 예외가 발생될 수 있다.
INSERT 시 Generated Key 받아오기 (KeyHolder)
우리는 데이터 스키마를 작성할 때 DB에서 생성된 값을 사용하기도 한다. DB 에서 생성된 값을 자바 어플리케이션으로 받아오려면 어떻게 해야할까?
그럴 때 사용하는 것이 Keyholder 이다.
예시 코드는 다음과 같다.
PreparedStatementCreatorFactory pscf =
new PreparedStatementCreatorFactory(
"insert into Taco_Order "
+ "(delivery_name, delivery_street, delivery_city, "
+ "delivery_state, delivery_zip, cc_number, "
+ "cc_expiration, cc_cvv, placed_at) "
+ "values (?,?,?,?,?,?,?,?,?)",
Types.VARCHAR, Types.VARCHAR, Types.VARCHAR,
Types.VARCHAR, Types.VARCHAR, Types.VARCHAR,
Types.VARCHAR, Types.VARCHAR, Types.TIMESTAMP
);
pscf.setReturnGeneratedKeys(true);
order.setPlacedAt(new Date());
PreparedStatementCreator psc =
pscf.newPreparedStatementCreator(
Arrays.asList(
order.getDeliveryName(),
order.getDeliveryStreet(),
order.getDeliveryCity(),
order.getDeliveryState(),
order.getDeliveryZip(),
order.getCcNumber(),
order.getCcExpiration(),
order.getCcCVV(),
order.getPlacedAt()));
GeneratedKeyHolder keyHolder = new GeneratedKeyHolder();
jdbcOperations.update(psc, keyHolder);
long orderId = keyHolder.getKey().longValue();
order.setId(orderId);
PreparedStatementCreator 와 KeyHolder 를 사용하여 update를 하면 key 값을 받아올 수 있다.
해당 기능의 동작 방식은 분석하여 별도의 글로 정리해본다. [spring] jdbctemplate - keyholder 동작 분석
좀 더 편리하게 Insert 하기 (SimpleJdbcInsert)
Insert 과정을 좀 더 편리하게 할 수 있다.
SimpleJdbcInsert orderInsert = new SimpleJdbcInsert(jdbcTemplate)
.withTableName("order")
.usingGeneratedKeyColumns("id");
Map<String, Object> values = convertValueToMap(order);
long orderId =
orderInserter
.executeAndReturnKey(values)
.longValue();
테이블과 자동 생성 key 컬럼을 지정하고 paramMap 을 이용하여 insert와 동시에 id 값을 받아올 수 있다. 물론 그냥 execute만 하는것도 가능하다.
데이터베이스 초기화 및 버전 관리하기
spring doc - Database Initialization
- Spring boot 자체 제공 기능 사용
- classpath (src/main/resources) 에 schema.sql, data.sql 이 있을 경우, Spring boot 실행시 SQL 문을 수행함.
- 단 Embedded Database일 경우에만 자동으로 실행되며, spring.sql.init.mode 값을 변경하여 다른 데이터베이스에서도 사용할 수 있음.
- 전문 도구를 활용하여 Database를 버저닝 하여 관리할 수도 있음.
- Flyway
- Liquibase
JdbcClient
Spring 6.1 에서 새로 나온 방식이다.
Document 에서는 다음과 같이 소개하고 있다.
NOTE: As of 6.1, there is a unified JDBC access facade available in the form of JdbcClient. JdbcClient provides a fluent API style for common JDBC queries/updates with flexible use of indexed or named parameters. It delegates to a JdbcTemplate/NamedParameterJdbcTemplate for actual execution.
통일된 방식으로 다양한 쿼리들을 수행할 수 있는 것이 특징이다. 또한 method chaining 방식을 채용하였다.
사용 예시들은 다음과 같다.
참고 : A Guide to Spring JdbcClient API
List<Student> getStudentsOfGradeStateAndGenderWithPositionalParams(int grade, String state, String gender) {
String sql = "select student_id, student_name, age, grade, gender, state from student"
+ " where grade = ? and state = ? and gender = ?";
return jdbcClient.sql(sql)
.param(grade)
.param(state)
.param(gender)
.query(new StudentRowMapper()).list();
}
int getCountOfStudentsOfGradeStateAndGenderWithNamedParam(int grade, String state, String gender) {
String sql = "select student_id, student_name, age, grade, gender, state from student"
+ " where grade = :grade and state = :state and gender = :gender";
RowCountCallbackHandler countCallbackHandler = new RowCountCallbackHandler();
jdbcClient.sql(sql)
.param("grade", grade)
.param("state", state)
.param("gender", gender)
.query(countCallbackHandler);
return countCallbackHandler.getRowCount();
}
Integer insertWithSetParamWithNamedParamAndSqlType(Student student) {
String sql = "INSERT INTO student (student_name, age, grade, gender, state)"
+ "VALUES (:name, :age, :grade, :gender, :state)";
Integer noOfrowsAffected = this.jdbcClient.sql(sql)
.param("name", student.getStudentName(), Types.VARCHAR)
.param("age", student.getAge(), Types.INTEGER)
.param("grade", student.getGrade(), Types.INTEGER)
.param("gender", student.getStudentGender(), Types.VARCHAR)
.param("state", student.getState(), Types.VARCHAR)
.update();
return noOfrowsAffected;
}
앞으로 이 방식이 많이 소개되고, 사용되지 않을까 생각된다.
JPA
이 책에서는 다루지 않지만 짧게 다루고 넘어가보자면 다음과 같다.
JPA는 Java Persistence API 의 약자이다. JDBC와 마찬가지로 인터페이스이며, 동작은 구현에 따른다. 영속성을 관리하는데 사용된다.
다음과 같이 엔티티를 정의한다.
@Entity
public class MyEntity {
@Id
private Long id;
private String name;
private int age;
// Getters and setters
}
다음과 같이 레포지토리를 구현한다.
엔티티 매니저는 엔티티를 관리하고 영속성을 처리하는 역할을 담당한다.
@PersistenceContext
private EntityManager entityManager;
public MyEntity findById(Long id) {
return entityManager.find(MyEntity.class, id);
}
public void save(String name, int age) {
MyEntity entity = new MyEntity();
entity.setName(name);
entity.setAge(age);
entityManager.persist(entity);
}
Spring Data JPA
Spring Data JPA 는 인터페이스를 통해 데이터 작업을 쉽게 처리할 수 있도록 돕는다.
대표적으로 아래와 같은 기능을 제공한다.
- 기본 인터페이스를 통한 기능 제공
- 쿼리 메소드 기능 제공
- 메소드 이름으로 쿼리 생성
- @Query 어노테이션으로 SQL 직접 정의
기본 인터페이스
JPA Repository는 자주 사용되는 데이터 접근 기능(예: CRUD, 페이징, 정렬 등)을 기본적으로 제공한다. 기본 제공 인터페이스는 다음과 같다.
public interface JpaRepository<T, ID>
extends ListCrudRepository<T, ID>,
ListPagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
void flush();
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
void deleteAllInBatch();
T getReferenceById(ID id);
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
개발자가 별도로 구현하지 않고도 바로 사용할 수 있다. 실제 구현은 JPA의 구현체(Hibernate, EclipseLink 등)에 의해 이루어진다.
메소드 이름으로 쿼리 생성
Spring 공식 문서 - JPA Query Methods
기본 인터페이스 외에도 간단하게 필요한 쿼리가 있을 때 이 방법을 사용하면 좋다. 인터페이스에 정해진 규칙에 따라 메소드의 이름을 지어주면 그에 따라 쿼리가 생성된다.
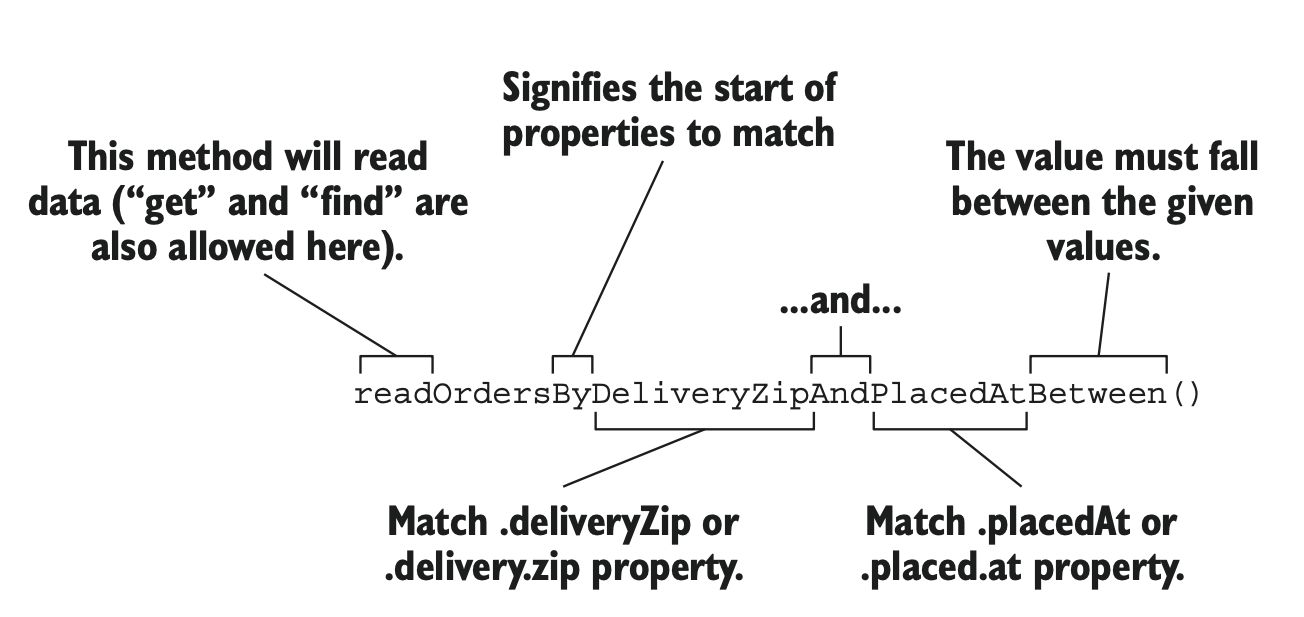
예를 들면 아래와 같이 메소드를 만들 수 있다.
List<TacoOrder> findByDeliveryNameAndDeliveryCityAllIgnoresCase(
String deliveryName, String deliveryCity);
List<TacoOrder> findByDeliveryCityOrderByDeliveryName(String city);
이 메소드는 다음과 같은 느낌으로 쿼리가 생성될 것이다.
SELECT *
FROM taco_order
WHERE LOWER(delivery_name) = LOWER(:deliveryName)
AND LOWER(delivery_city) = LOWER(:deliveryCity);
SELECT *
FROM taco_order
WHERE delivery_city = :city
ORDER BY delivery_name;
이외에도 다양한 문법들을 제공한다.
- IsAfter, After, IsGreaterThan, GreaterThan
- IsGreaterThanEqual, GreaterThanEqual
- IsBefore, Before, IsLessThan, LessThan
- IsLessThanEqual, LessThanEqual
- IsBetween, Between
- IsNull, Null
- IsNotNull, NotNull
- IsIn, In
- IsNotIn, NotIn
- IsStartingWith, StartingWith, StartsWith
- IsEndingWith, EndingWith, EndsWith
- IsContaining, Containing, Contains
- IsLike, Like
- IsNotLike, NotLike
- IsTrue, True
- IsFalse, False
- Is, Equals
- IsNot, Not
- IgnoringCase, IgnoresCase
@Query 어노테이션으로 SQL 직접 정의
이름 기반으로 작성하기 어려울 경우나, 최적화가 필요하다든지, 다양한 이유로 직접 쿼리를 정의해야 할 때 사용할 수 있다.
@Query("SELECT o FROM Order o WHERE o.deliveryCity = :city")
List<TacoOrder> readOrdersDeliveredInCity(@Param("city") String city);
마무리
이 책에서는 JDBC에 대한 설명이 더 많은 편이다. 추후 스터디에서 JPA 책을 집중적으로 분석해볼 예정이니 그 때 더 자세히 알아볼 수 있도록 한다.