[MySQL] INSERT, UPDATE, DELETE 쿼리 작성 및 최적화 - Real MySQL 스터디 7회차 (끝)
INSERT, UPDATE, DELETE 쿼리 작성 및 최적화
INSERT IGNORE
이미 존재하는 경우 넘어가고 다음 레코드를 처리할 수 있게 해준다.
INSERT IGNORE INTO salaries (emp_no, salary, from_date, to_date)
VALUES (10001, 60117, '1986-06-26', '1988-06-25'),
(10001, 62102, '1987-06-26', '1988-06-25'),
(10001, 66074, '1988-06-25', '1989-06-25'),
(10001, 66596, '1989-06-25', '1990-06-25'),
(10001, 66961, '1990-06-25', '1991-06-25');
여기서 emp_no 는 primary key 로 설정되어 있다고 가정해보자. 그러면 당연히 key가 중복되게 insert를 수행하려고 하기 때문에 에러가 발생해야 하겠지만 INSERT IGNORE 를 사용하면 error 를 warning 으로 낮춰주기 때문에 에러 없이 SQL 실행이 완료된다.
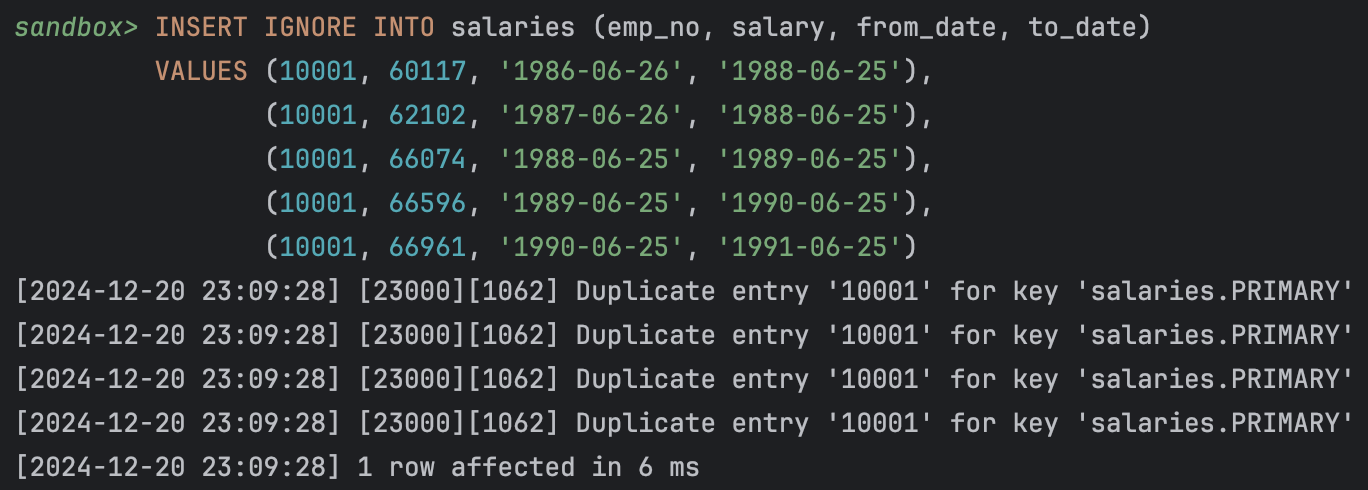
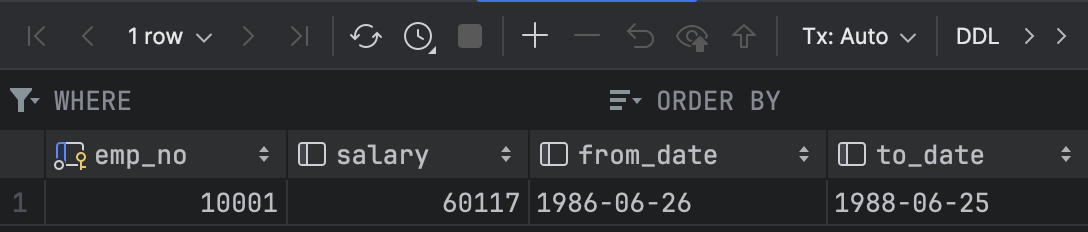
5 건의 insert를 시도하였고, 처음 1건이 성공 한 후 이후의 4건을 warning 처리되고 완료되었다. 테이블을 조회해보면 처음 첫 건만 들어간 것을 확인할 수 있다.
INSERT … ON DUPLICATE KEY UPDATE
INSERT 하고자 하는 데이터의 KEY가 이미 테이블에 존재할 경우 기존에 테이블에 있는 데이터를 업데이트 시도한다.
CREATE TABLE daily_statistic (
target_date DATE NOT NULL,
stat_name VARCHAR(10) NOT NULL,
stat_value BIGINT NOT NULL DEFAULT 0,
PRIMARY KEY(target_date, stat_name)
);
이러한 테이블을 이용하여 통계 정보를 관리한다고 하였을 때 아래와 같이 SQL 문을 구성하여 카운터를 관리할 수 있다.
INSERT INTO daily_statistic (target_date, stat_name, stat_value)
VALUES(DATE(NOW()), 'VISIT', 1)
ON DUPLICATE KEY UPDATE stat_value = stat_value + 1;
해당 날짜에 첫 입력이라면, insert가 진행되고 그 이후로는 update가 진행될 것이다.
BULK INSERT
애플리케이션을 개발하다보면 대량의 insert가 필요한 경우가 있다. 이 때 단일 INSERT로 모든 데이터를 처리한다면 매우 오랜 시간이 걸리게 된다.
데이터를 INSERT 처리할 때 필요한 시간
데이터를 INSERT 처리할 때 필요한 시간은 대략 다음과 같이 나타낼 수 있다.
- Connecting: (3)
- Sending query to server: (2)
- Parsing query: (2)
- Inserting row: (1 × size of row)
- Inserting indexes: (1 × number of indexes)
- Closing: (1)
단일 INSERT
단일 INSERT는 위의 작업이 각 INSERT 마다 반복적으로 수행된다.
예를 들어 1000 개의 행을 잡입한다고 한다면 총 코스트는 다음과 같이 계산할 수 있을 것이다.
COST = (3 + 2 + 2 + 1 + 1 + 1) * 1,000 = 10,000
INSERT INTO … VALUES (…), …
이 명령문은 한 번의 쿼리로 여러 레코드를 삽입할 수 있다. 단일 INSERT로 처리하는 것보다 상당히 빠르다.
Connecting, Sending query to server, Parsing query, Closing 에 반복적으로 드는 비용을 줄일 수 있다. INSERT 하고자 하는 Record 수가 증가함에 따라 Inserting row, Inserting indexes 에 대한 코스트만 늘어나게 된다.
예를 들어 1000 개의 행을 잡입한다고 한다면 총 코스트는 다음과 같이 계산할 수 있을 것이다.
COST = 3 + 2 + 2 + (1 * 1,000) + (1 * 1000) + 1 = 1,009
* 위의 계산은 개념적 비교를 한 것이며, 실제 성능 차이는 상황에 따라 다르다는 것에 주의
LOAD DATA
외부 파일에서 대량의 데이터를 가져와 insert 를 해야하는 상황이라면 load data 를 사용해 볼 수 있다.
INSERT를 쓰는것보다 약 20배 빠르다고 한다.
When loading a table from a text file, use LOAD DATA. This is usually 20 times faster than using INSERT statements
LOAD DATA INFILE 'data.csv'
INTO TABLE salaries
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'DELETE FROM employees
LOAD DATA 와 관련된 추가적인 팁
- 파일 위치를 잘 잡아줘야 한다.
- 단일 스레드로 동작하기 때문에 파일을 여러개로 나눠서 병렬로 진행하면 더 빠르게 작업할 수 있다.
- 파일에서 이미 정렬이 되어있다면 더 좋다.
PRIMARY KEY 산정하기
- InnoDB의 특성상 클러스터링을 사용하는 쿼리가 세컨더리 인덱스를 이용하는 쿼리보다 더 빠르다.
- 프라이머리키를 정할 때는 Insert 가 빨라야 하는지, Select 가 빨라야 하는지 고려해야 한다.
- 읽기 비율이 높은 경우에는 SELECT에 유리한 컬럼을 프라이머리 키로 선정해야 한다
- 키가 랜덤하게 저장된다면 MySQL 서버는 레코드를 INSERT 할 때마다 저장될 위치를 찾아야 한다.
- 테이블의 크기가 커지면 커질수록 더 많은 메모리를 필요로 하게 된다. 메모리 범위를 넘어서면 저장될 위치를 찾기 위해 디스크 읽기가 필요할 수도 있다.
고유 식별자 생성 전략
- auto increment
- uuid
- snowflake id
auto increment
- 가장 빠른 INSERT를 보장한다.
- 내부 ID로 사용하기 좋다.
- 자동 증가 값의 채번을 위해 AUTO-INC Lock 이 발생된다.
UUID
universally unique identifier
- 중복이 되지 않는 고유 값을 생성할 수 있다.
- 유추하기 어려운 값을 생성할 수 있다.
- 주로 1, 4 버전이 사용된다.
- 최근에 6-8 버전이 정식으로 정의되었다.
버전별 한 줄 설명: UUID versions 1-5
- version 1 : MAC 주소 및 시간 기반
- version 2 : DCE Security version
- version 3 : MD5 처리한 문자열 기반
- version 4 : 랜덤 기반
- version 5 : sha-1 처리한 문자열 기반
버전별 한 줄 설명: UUID versions 6-8
rfc9562 (May 2024 published)
- version 6 : version 1 에서 timestamp 부분을 순차적으로 오를 수 있도록 개선
- version 7 : 타임스탬프와 랜덤 기반
- version 8 : 커스텀
MySQL 에서의 UUID
MySQL에서는 UUID v1 을 기본 지원한다. 다른 버전이 필요할 경우 함수로 등록하여 사용할 수 있다.
* 번외 : Java 에서는 UUID v4 를 기본 지원한다. 마찬가지로 외부 라이브러리를 통해 다른 버전을 사용할 수 있다.
UUID version 1
timestamp 와 mac 주소를 사용한다.
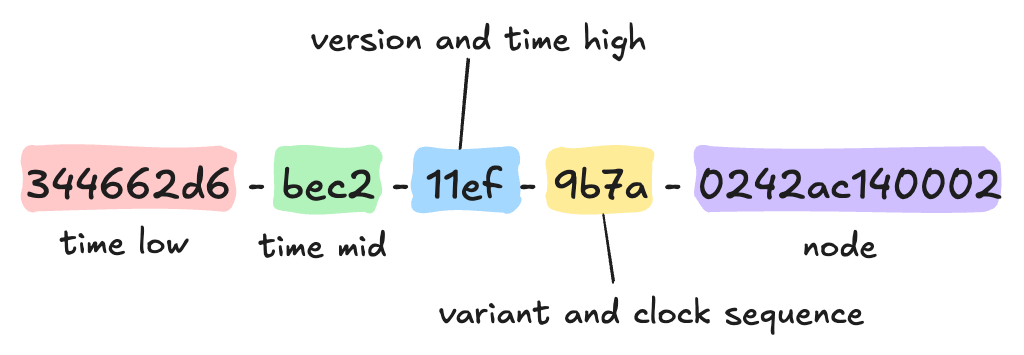
timestamp의 비트 순서가 바뀌어서 배치된다. node 영역이 mac 주소를 사용한다.
- 3번째 영역의 첫번째 숫자는 UUID 버전을 나타낸다. (여기서는 버전 1 이기때문에 1이다.)
- 4번째 영역의 앞부분은 variant 값을 나타낸다. 일반적인 경우 2진법 기준으로 10 으로 시작한다. (9는 2진법으로 1001 이다)
- 사용 목적에 따라 variant 를 변경시키기도 하지만, 일반적인 경우는 10으로 고정해둔다고 생각해두면 편할것이다. 관련 내용 링크
여기서 Clock Sequence 는 뭔가 이름만 들으면 흘러갈 것 같지만 고정된 값에 가깝다. 아래의 경우에 변경이 발생된다.
- 동일한 millisecond 내에서 너무 많은 uuid를 생성된 경우
- 너무 많다 의 정의는 구현에 따라 다르다.
- 시스템 시간에 변경이 있을 경우
UUID version 4
랜덤 값을 사용한다.

이미지 출처 : Understanding UUID: Purpose and Benefits of a Universal Unique Identifier
UUID version 영역과 variant 부분을 제외하고는 모두 랜덤한 값을 사용한다. (여기서도 variant는 10 으로 세팅되어 있는것을 볼 수 있다. 1011)
UUID version 4 충돌 가능성
UUID version 4 의 충돌 가능성은 굉장히 낮다.

수학적으로 계산해 보았을 때 103조 개의 UUID 중에서 중복을 찾을 확률이 10억 분의 1 수준이며

초당 10억 개의 UUID를 86년 동안 연속해서 만들었을 때 중복 UUID가 1개 생길 확룔이 50% 라고 한다.
UUID version 4의 단점
완전 램덤하기 때문에 키가 순차적이지 않다. 이는 Primary Key 로 사용했을 경우 인덱스 성능을 내기 어렵하게 하는 원인이 된다.
UUID version 6
timestamp 와 mac 주소를 사용한다.
uuid v1 과 비슷하지만 timestamp의 순서를 그대로 유지한다.
UUID v1 과 UUID v6 비교
uuid v1 값을 uuid v6 로 변경해보면 다음과 같다.
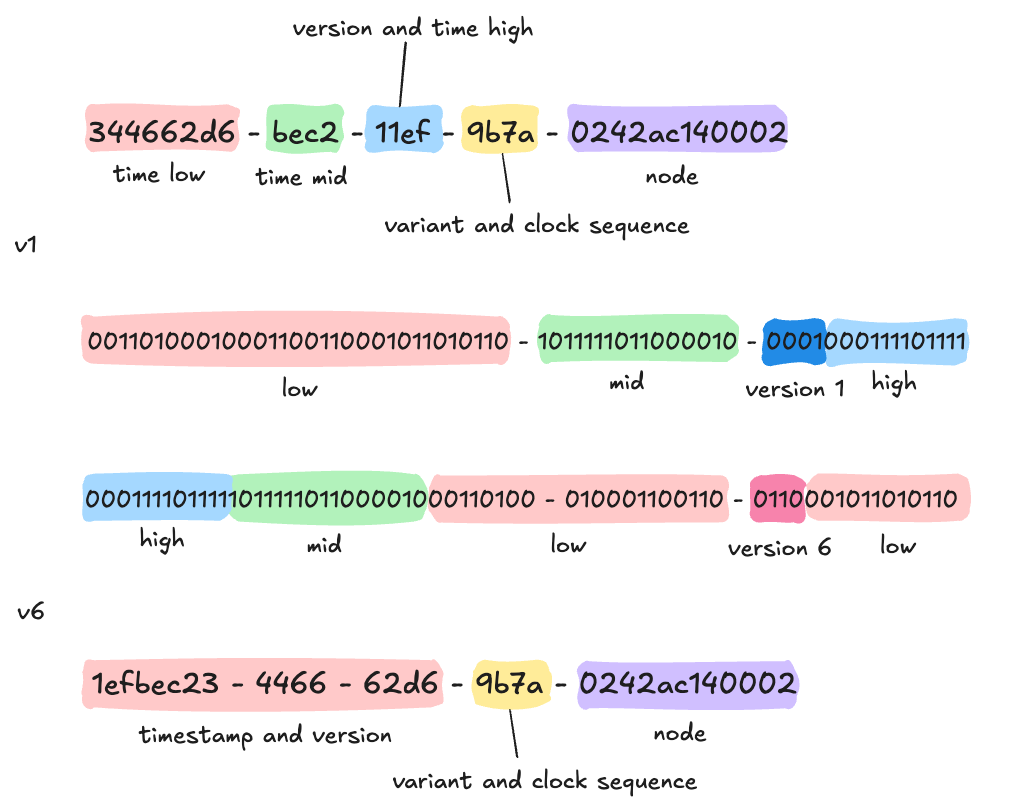
UUID version 6 의 장점
생성된 UUID가 시간에 따라 순차적으로 정렬된다.
UUID version 7
timestamp 와 random 값을 사용한다.
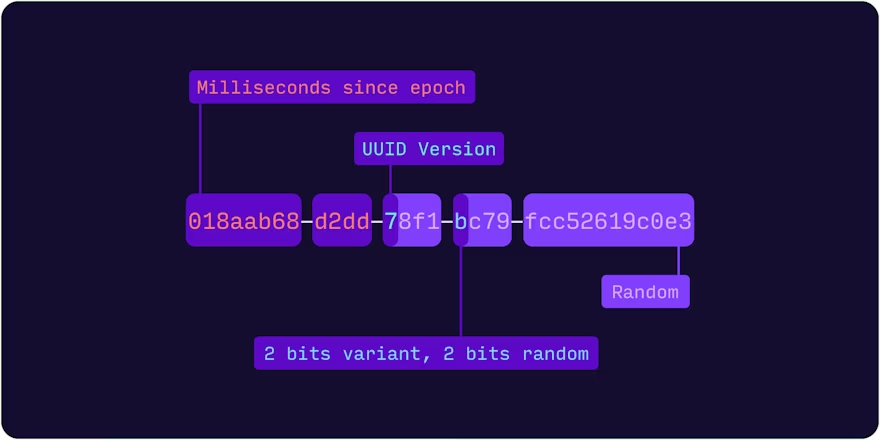
이미지 출처: Goodbye integers. Hello UUIDv7!
MySQL UUID with Swap Flag
앞서 설명한 것처럼 MySQL 은 기본적으로 uuid v1 을 지원하고 있다. uuid v1은 timestamp 를 swap 해서 사용하기 때문에 순차적으로 증가하지 않는다. 이는 좋지 않은 인덱스 성능으로 연결될 수 있다.
이러한 문제를 해결하고자 MySQL 8.0 부터는 uuid를 swap 할 수 있도록 flag 를 제공한다. (UUID_TO_BIN, BIN_TO_UUID)
uuid v1 과 swap flag 를 이용한 결과물을 비교해보면 다음과 같다.

참고로 uuid v6 과 비슷하지만 완전 같지는 않다. uuid v6 는 uuid 정의에 따라 version 위치는 움직이지 않는다. 하지만 swap flag 의 경우에는 변경된다.
사용 예시
다음과 같이 테이블을 생성한 후 데이터를 입력한다.
-- 테이블 생성 : UUID_TO_BIN(UUID(),1)
create table tb_test3 (
uuid binary(16) default (UUID_TO_BIN(UUID(),1)) primary key,
first_name varchar(15),
emp_no int unsigned
)
engine=innodb default charset=utf8mb4 collate=utf8mb4_general_ci;
-- 데이터 입력
insert into tb_test3(first_name,emp_no) values ('Georgi',10001);
insert into tb_test3(first_name,emp_no) values ('Mary',10002);
insert into tb_test3(first_name,emp_no) values ('Saniya',10003);
insert into tb_test3(first_name,emp_no) values ('Sumant',10004);
insert into tb_test3(first_name,emp_no) values ('Duangkaew',10005);
insert into tb_test3(first_name,emp_no) values ('Patricio',10006);
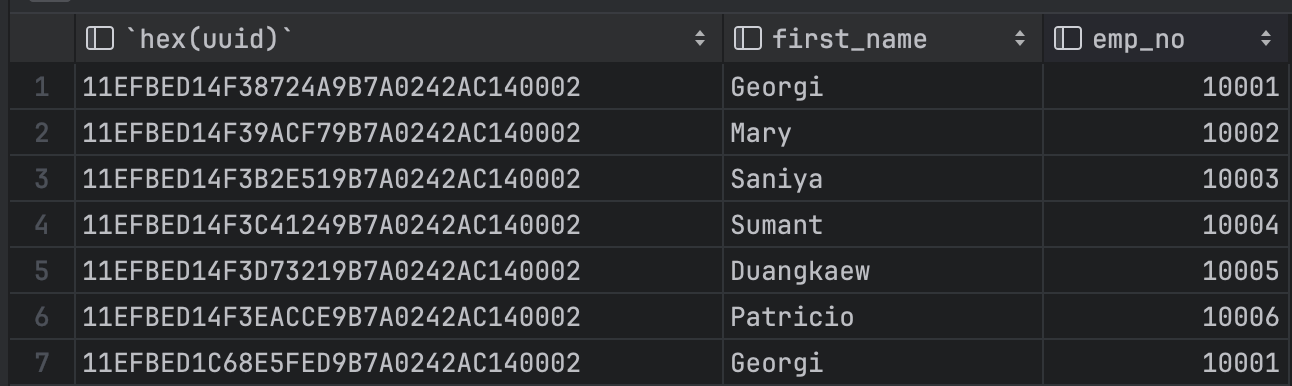
이후 아래와 같이 테이블을 조회하면 순서가 정렬된 primary key 를 가진것을 볼 수 있다.
select hex(uuid),first_name,emp_no from tb_test3;
MySQL 에서 UUID는 어떤 타입으로 저장해야 할까?
- 읽기/쓰기 성능과 저장 공간이 중요할 경우: BINARY(16) 권장.
- 읽기/쓰기 시에 형변환 필요.
- 사람이 쉽게 읽을 수 있는 형태가 중요할 경우: VARCHAR(36) 권장.
SNOWFLAKE ID
UUID의 아쉬운 점 중 하나는 16바이트라는 비교적 큰 크기를 차지한다는 것이다.
Snowflake ID는 유일한(unique) 값을 생성하면서도 64비트(bigint)를 사용하며, 생성 시각에 따라 순차적으로 정렬이 가능하다. 또한 분산 환경에서도 쓸 수 있도록 설계되어 있어, 여러 서버에서 동시에 ID를 생성해도 충돌 없이 유니크한 값을 보장할 수 있다.

- 타임스탬프(timestamp): 기원 시간 이후 몇 밀리초(millisecond)가 경과했는지를 나타내는 값
- 데이터센터 ID: 5비트를 할당한다. 따라서 32개의 데이터 센터를 지원할 수 있다.
- 서버 ID: 5비트를 할당한다. 따라서 데이터 센터당 32개의 서버를 지원할 수 있다.
- 일련번호: 12비트를 할당한다. 각 서버에서 ID를 생성할 때마다 이 일련 번호를 1만큼 증가시킨다. 이 값은 1밀리초가 경과할 때마다 0으로 초기화 한다.
* timestamp 를 그대로 쓰는것이 아니라 기원 시간을 정의하여 제한된 공간에 더 많은 시간을 담을 수 있도록 한다.
대체키 활용하기 (Hybrid)
각 고유 식별자 별로 장단점이 있다는 것을 확인하였다. 각각의 장단점을 보완하기 위해 다음과 같이 사용하는 전략을 고려할 수도 있다.
내부적으로는 Auto Increment 또는 타임스템프 기반의 프라이머리키를 사용하고 외부적으로는 UUID 기반의 유니크 세컨더리 인덱스를 사용한다.
UPDATE (DELETE) … ORDER BY … LIMIT …
한 번에 너무 많은 레코드를 변경 및 삭제하는 작업은 MySQL 서버에 과부하를 유발하거나 다른 커넥션의 쿼리 처리를 방해할 수 있다. 이 때 LIMIT을 통해 조금씩 잘라서 변경하거나 삭제하는 방식을 사용할 수 있다.
SELECT 뿐 아니라 UPDATE 와 DELETE 에도 LIMIT을 사용할 수 있다. ORDER BY 를 사용하지 않으면 정렬 순서를 보장하지 않기 때문에 함께 사용한다.
e.g. 오래된 주문 archived 처리하기
UPDATE orders
SET status = 'archived'
WHERE status = 'completed'
ORDER BY completed_at ASC
LIMIT 50;
e.g. 오래된 에러로그 삭제하기
DELETE FROM logs
WHERE log_type = 'error'
ORDER BY created_at ASC
LIMIT 100;
JOIN UPDATE
특정 테이블의 컬럼값을 다른 테이블의 컬럼에 업데이트 해야할 때 사용할 수 있다.
사용 예시는 다음과 같다.
CREATE TABLE tb_test1 (
emp_no INT,
first_name VARCHAR(14),
PRIMARY KEY(emp_no)
);
INSERT INTO tb_test1
VALUES
(10001, NULL),
(10002, NULL),
(10003, NULL),
(10004, NULL);
UPDATE tb_test1 t1, employees e,
SET t1.first_name = e.first_name
WHERE e.emp_no=t1.emp_no
여러 레코드 한 번에 업데이트
* 이 기능은 MySQL 8.0.19 에 나온 기능이다.
기존에는 UPDATE 문은 위에서 설명한 INSERT 문처럼 한번에 처리하는 방법이 존재하지 않았다. 레코드 생성 문법(row_constructor_list)을 활용하여 하나의 쿼리로 레코드 별로 서로 다른 값을 업데이트 할 수 있다.
사용 예시 1
CREATE TABLE user_level (
user_id BIGINT NOT NULL,
user_lv INT NOT NULL,
created_at DATETIME NOT NULL,
PRIMARY KEY (user_id)
);
UPDATE user_level ul
INNER JOIN (VALUES ROW(1, 1), ROW(2,4)) new_user_level (user_id, user_lv)
ON new_user_level.user_id = ul.user_id
SET ul.user_lv = ul.user_lv + new_user_level.user_lv;
사용 예시 2
원래는 아래와 같이 단일 UPDATE로 처리하던 것을
UPDATE user_coupon SET expired_at='2022-09-30' WHERE coupon_id=1;
UPDATE user_coupon SET expired_at='2022-12-31' WHERE coupon_id=2;
UPDATE user_coupon SET expired_at='2022-11-30' WHERE coupon_id=3;
...
이 방식을 사용하면 하나의 쿼리로 처리할 수 있다.
UPDATE userc_coupon uc
INNER JOIN (VALUES ROW(1, '2022-09-30')
ROW(2, '2022-09-30')
ROW(3, '2022-09-30')
...
) change_coupon (coupon_id, expired_at)
ON change_coupon.coupon_id=uc.coupon_id
SET uc.expired_at = change_coupon.expired_at;
JOIN DELETE
JOIN을 사용하여 여러 테이블에서 동시에 레코드를 삭제할 수 있다. 삭제할 테이블을 DELETE 와 FROM 사이에 적는다.
DELETE e, de
FROM employees e, dept_emp de, departments d
WHERE e.emp_no=de.emp_no
AND de.dept_no=d.dept_no
AND d.dept_no = 'd001';
프로세스 조회 및 종료
SHOW PROCESSLIST -- 현재 접속중인 커넥션 정보를 보여준다.
KILL QUERY {id} -- 커넥션은 유지하고 실행중인 쿼리만 종료시킨다.
KILL {id} -- 커넥션을 종료시킨다.
참고
UUID version 4 의 충돌 가능성 vs 로또 당첨 확률
재미로 ChatGPT 에게 물어보았다. UUID v4 중복을 걱정하느니 로또에 당첨될 걱정을 하는 게 훨씬 현실적이라 한다. 🤣
mysql uuid swap flag
- 이와 관련해서 MySQL - UUID 활용 - PK 로 사용 글에 잘 정리되어 있다.
분산 시스템에서 유일 ID 생성기 설계하기
가상 면접 사례로 배우는 대규모 시스템 설계 기초의 7장도 읽어보면 좋을 것 같다.