[MySQL] SELECT 쿼리 작성 및 최적화 - Real MySQL 스터디 6회차
SELECT 쿼리 작성 및 최적화
SELECT 문의 구조
SELECT s.emp_no, COUNT(DISTINCT e.first_name) AS cnt
FROM salaries s
INNER JOIN employees e ON e.emp_no=s.emp_no
WHERE s.emp_no IN (100001, 100002)
GROUP BY s.emp_no
HAVING AVG(s.salary) › 1000
ORDER BY AVG(s.salary)
LIMIT 10;
SELECT 문은 여러 가지 절(키워드 + 그 뒤에 기술된 표현식)로 구정되어 있다. SELECT 절, FROM 절, WHERE 절, GROUP BY절, HAVING 절, ORDER BY 절, LIMIT 절 이 이에 해당한다.
SELECT 문의 처리 순서
일반적인 상황에서의 쿼리 실행 순서는 다음과 같다.

만약 이 실행 순서를 벗어나는 쿼리가 필요하다면, 서브쿼리로 작성된 인라인 뷰를 고려하자.
SELECT 문에서 WHERE 절 작성시 주의 사항
- 조건식은 데이터 타입이 일치하도록 작성한다.
- 데이터 타입이 일치하지 않으면 index를 사용하지 못한다.
- 데이터 베이스의 컬럼이 변형되지 않도록 주의한다. 컬럼이 변형되면 index를 설정하더라도 index를 사용하지 못한다. 필요시 입력값을 변형한다.
- 예시
SELECT * FROM employees WHERE first_name = 10001;- 데이터베이스의 문자열 컬럼이 숫자로 변경된 다음 비교를 진행하게 된다.
- 예시
COUNT 함수
- COUNT 함수에
*을 사용하면, 모든 ROW를 계산합니다. - COUNT 함수에 컬럼을 지정했을 경우, 그 컬럼이 NULL 일경우 제외하여 계산합니다.
COUNT 함수에 대해 쉽게 오해하는 것
COUNT는 그냥 데이터를 가져오는 것에 비해 빠를 것이다 기대하지만 그렇지 않다. 네트워크 사용량은 적을 수 있겠지만 일반적인 SELECT와 접근 방식은 동일하다.
일반적으로 SELECT * 은 LIMIT 과 동시에 사용되지만, SELECT COUNT(*) 는 LIMIT 없이 사용된다. COUNT에는 LIMIT이 적용되지 않는다.
전체 건수 조회하기
아래 쿼리는 모두 동일한 결과를 반환한다.
COUNT(1),COUNT(pk_col),COUNT(*),SUM(1),COUNT(not_null_col)
하지만 그럼에도 전체 컬럼을 가져올때는 COUNT(*) 을 쓰는것이 좋다.
- 일부 상황에서 성능이 달라질 수 있음.
- 혼용될 경우 쿼리의 가독성이 떨어짐
COUNT (DISTINCT COLUMN)
COUNT (DISTINCT COLUMN)은 인덱스가 없을 경우 임시 테이블로 중복 제거후 건수를 확인한다. (부하가 심할 수 있으므로 주의한다.)
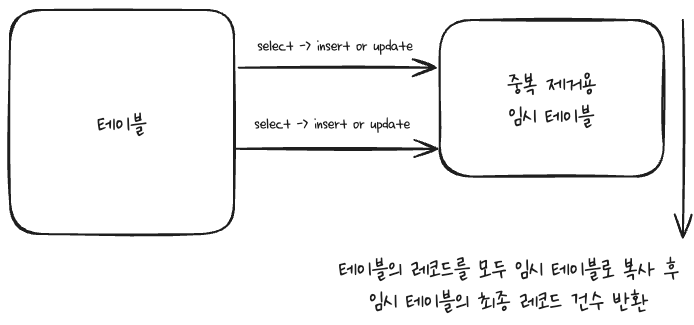
COUNT(*) 튜닝
- 최고의 튜닝은 쿼리 자체를 제거하는 것.
- 전체 결과 건수 확인 쿼리 제거
- 쿼리를 제거할 수 없다면, 대략적 건수 활용
- 대부분 조회되는 데이터는 앞쪽에 있다.
- 부분 레코드 건수 조회
SELECT COUNT(*) FROM (SELECT 1 FROM table LIMIT 200) z;
- 임의의 페이지 번호 표기 (구글 검색이 이 방식을 활용한다.)
- 첫 페이지에서 10개 페이지 표시 후, 실제 해당 페이지로 이동하면서 페이지 번호 보정
- 페이지 보정이 발생되었을 경우,
COUNT(*)을 수행하긴 하지만, 기존보다 호출 횟수를 줄일 수 있음.
- 통계 정보 활용
- 쿼리 조건이 없는 경우, 테이블 통계 활용
- 쿼리 조건이 있는 경우, 실행 계획 활용
DISTINCT
DISTINCT는 특정 칼럼의 유니크한 값만 조회한다. SELECT 절에서 사용할 수 있다. NULL도 결과에 포함될 수 있다.
DISTINCT 사용시 주의 사항
아래의 두 쿼리의 차이는 무엇일까?
SELECT DISTINCT first_name, last_name FROM employees
SELECT (DISTINCT first_name), last_name FROM employees
정답은 없다.
DISTINCT 는 SELECT 하는 레코드(튜플)을 유니크하게 SELECT 하는 것이지, 특정 칼럼만 유니크 하게 조회하는 것이 아니다. MySQL 서버는 DISTINCT 뒤의 괄호를 그냥 의미 없이 사용된 괄호로 해석하고 제거해버린다. (DISTINCT 는 함수가 아니다. 괄호가 의미가 없다.)
책에서는 아래와 같은 문제도 제시하고 있다. 세가지 쿼리문이 각각 어떠한 차이가 있을까?
SELECT DISTINCT first_name, last_name
FROM employees WHERE emp_no BETWEEN 10001 AND 10200;
SELECT COUNT(DISTINCT first_name), COUNT(DISTINCT last_name)
FROM employees WHERE emp_no BETWEEN 10001 AND 10200;
SELECT COUNT(DISTINCT first_name, last_name)
FROM employees WHERE emp_no BETWEEN 10001 AND 10200;
첫번째 쿼리는 유니크한 튜플 조합을 SELECT 한다. 두번째 쿼리는 first_name의 유니크한 값을 카운트 한 것과, last_name의 유니크한 값을 카운트 한 것을 SELECT 한다. 여기서 주의할 것은 COUNT는 NULL인 레코드는 계산에 포함하지 않는다. 세번째 쿼리는 유니크한 튜플 조합을 카운트 한 것을 반환한다. 여기서 주의할 것은 두 컬럼 중 하나라도 NULL 이 포함되어 있다면 계산에 포함하지 않는다.
DISTINCT 와 GROUP BY 의 차이는?
- DISTINCT 는 중복 제거가 주 목적이다.
- GROUP BY 는 집계 및 요약 작업이 주 목적이다.
LIMIT 과 함께 사용할 때
DISTINCT는 LIMIT 까지 수행되면 그 순간 쿼리를 멈춘다. 반면에 GROUP BY는 일단 GROUP BY가 완료 된 후에 LIMIT을 수행한다.
외래키가 설정되어 있으면 성능에 도움이 될까?
근본적으로 봤을 때 외래키는 무결성을 지키게 하는 제약조건일 뿐이다. 따라서 성능이 개선되거나 하지는 않는다. 하지만 MySQL은 외래키를 설정할 때 자동으로 index를 설정한다. 따라서 성능이 올라가는 것처럼 보일 수 있다.
WHERE 와 HAVING의 비교
- 공통점 : WHERE 와 HAVING은 모두 조건을 지정하는데 사용된다.
- 차이점
- WHERE 는 레코드에 대한 조건을 지정한다.
- HAVING 은 그룹에 대한 조건을 지정한다. 즉, GROUP BY 가 적용된 데이터에 대해 필터링을 진행한다.
- 처리 순서
- WHERE 는 GROUP BY 이전에 적용합니다.
- HAVING 은 GROUP BY 이후에 적용됩니다.
index 활용하기
WHERE 절의 인덱스 사용
WHERE 절에서 조건들의 실행 순서는 작성 순서와 다를 수 있다.
옵티마이저는 인덱스를 사용할 수 있는 조건들을 뽑아서 먼저 진행한다. 나머지는 순차적으로 진행된다.
GROUP BY 절의 인덱스 사용
- GROUP BY 절에 명시된 칼럼이 인덱스 칼럼의 순서와 위치가 같아야 한다.
- 인덱스를 구성하는 칼럼중에서 뒤쪽에 있는 칼럼은 GROUP BY절에 명시되지 않아도 인덱스를 사용할 수 있지만 인덱스의 앞 쪽에 있는 칼럼이 GROUP BY 절에 명시되지 않으면 인덱스를 사용할 수 없다.
- WHERE 조건절과는 달리 GROUP BY 절에 명시된 칼럼이 하나라도 인덱스에 없으면 GROUP BY절은 전혀 인덱스를 이용하지 못한다.
GROUP BY 절에서 인덱스를 사용하지 못하는 예시
index는 COL_1, COL_2, COL_3, COL_4 순으로 모두 ASC로 걸려있다 가정
... GROUP BY COL_2, COL_1
... GROUP BY COL_1, COL_3, COL_2
... GROUP BY COL_1, COL_3
... GROUP BY COL_1, COL_2, COL_3, COL_4, COL_5
GROUP BY 절에서 인덱스를 사용하는 예시
index는 COL_1, COL_2, COL_3, COL_4 순으로 모두 ASC로 걸려있다 가정
... GROUP BY COL_1
... GROUP BY COL_1, COL_2
... GROUP BY COL_1, COL_2, COL_3
... GROUP BY COL_1, COL_2, COL_3, COL_4
ORDER BY 절의 인덱스 사용
GROUP BY 와 비슷하나 한가지 추가적인 조건이 있다.
- ORDER BY 절에 명시된 칼럼이 인덱스 칼럼의 순서와 위치가 같아야 한다.
- 인덱스를 구성하는 칼럼중에서 뒤쪽에 있는 칼럼은 ORDER BY절에 명시되지 않아도 인덱스를 사용할 수 있지만 인덱스의 앞 쪽에 있는 칼럼이 6ROUP BY 절에 명시되지 않으면 인덱스를 사용할 수 없다.
- WHERE 조건절과는 달리 ORDER BY 절에 명시된 칼럼이 하나라도 인덱스에 없으면 ORDER BY절은 전혀 인덱스를 이용하지 못한다.
- ORDER BY 절의 컬럼 순서와 방향이 인덱스의 정의와 일치하거나 반대인 경우에만 인덱스를 활용할 수 있다.
ORDER BY 절에서 인덱스를 사용하지 못하는 예시
index는 COL_1, COL_2, COL_3, COL_4 순으로 모두 ASC로 걸려있다 가정
... ORDER BY COL_2, COL_1
... ORDER BY COL_1, COL_2 DESC, COL_3
... ORDER BY COL_1, COL_3, COL_2
... ORDER BY COL_1, COL_3
... ORDER BY COL_1, COL_2, COL_3, COL_4, COL_5
복합 사례
아래의 쿼리는 index를 활용할 수 있을까?
SELECT *
FROM tb_test
WHERE COL_1=10
ORDER BY COL_2, COL_3;
얼핏 보기에는 ORDER BY 에 COL_1 이 빠졌기 때문에 되지 않을것으로 보인다. 하지만 COL_1 의 경우에는 이미 WHERE 절에서 필터링이 되었기 때문에 이 경우에는 index를 활용할 수 있다.
LIMIT 절
LIMIT은 1개 또는 2개의 인자를 사용할 수 있다.
1개 인자 사용 : 상위 n 개의 레코드를 가져온다. 2개 인자 사용 : 첫 번째 인자에 지정된 위치부터 두 번째 인자에 명시된 개수 만큼의 레코드를 가져온다
아래의 SELECT 문들은 같은 결과를 반환한다.
SELECT * FROM employees LIMIT 10;
SELECT * FROM employees LIMIT 0, 10;
SELECT * FROM employees OFFSET 0 LIMIT 10;
LIMIT 사용시 유의 사항
DBMS에서 순차적으로 레코드를 읽지 않고 지정된 OFFSET 이후 데이터만 바로 가져올 수는 없다. 따라서 OFFSET이 커질수록 쿼리 실행을 위해 읽는 데이터가 많아진다.
SELECT * FROM employees LIMIT 0, 10;
SELECT * FROM employees LIMIT 10, 10;
첫번째 SQL 문을 수행하기 위해서는 10개의 데이터만 읽으면 되지만 두번째 SQL 문을 수행하기 위해서는 20개의 데이터를 읽어야 한다.
페이징 쿼리 작성법
위에서 LIMIT 으로 발생할 수 있는 성능 문제에 대해서 알아보았다.
LIMIT 만으로 페이징 처리를 하는것은 성능 문제를 발생 할 수 있다. 그러면 어떻게 페이징 쿼리를 하면 좋을지에 대해서 알아본다.
범위 기반 방식 과 데이터 개수 기반 방식 을 정리한다.
범위 기반 방식 예시
- 날짜 기간이나 숫자 범위로 나눠서 데이터를 조회하는 방식.
- 배치 작업에서 주로 사용한다.
숫자인 id 값을 바탕으로 범위를 나눠 데이터 조회 (5000 단위 조회)
SELECT *
FROM users
WHERE id > 0 AND id <= 5000
날짜 기준으로 나눠서 조회 (일 단위 조회)
SELECT *
FROM payments
WHERE finished_at >= '2024-12-07' AND finished_at < '2022-12-07'
데이터 개수 기반 방식
- 지정된 데이터 건수만큼 결과 데이터를 반환하는 방식.
- 서비스 단에서 주로 사용한다.
- ORDER BY & LIMIT 절을 사용한다.
- 처음 쿼리를 실행할 때(1회차)와 그 이후 쿼리를 실행할 때(N회차) 쿼리 형태가 달라진다.
아래 쿼리를 페이징 처리를 한다면
SELECT *
FROM payments
WHERE user_id = ?
다음과 같이 쿼리를 만들어 볼 수 있다.
1회차 쿼리
SELECT *
FROM payments
WHERE user_id = ?
ORDER BY id
LIMIT 30
N회차 쿼리
SELECT *
FROM payments
WHERE user_id = ?
AND id > {이전 데이터의 마지막 id 값}
ORDER BY id
LIMIT 30
ORDER BY
DBMS는 ORDER BY로 명시하지 않을 경우 정렬이 되어있는것을 보장하지는 않는다. 따라서 순서가 중요할 경우는 반드시 ORDER BY를 사용해 줘야 한다.
잠금
잠금 파트를 공부할 때 SELECT ... FOR UPDATE 에 대해서 배웠었다.
SELECT ... FOR UPDATE 를 사용할 경우 MySQL 은 Record 락을 수행한다.
관련 글 : [MySQL] 잠금 과 트랜잭션 (Lock and Transacdtion)
추가적으로 NO WAIT 와 SKIP LOCK 에 대해서 알아보도록 한다.
NOWAIT & SKIP LOCK
NOWAIT : LOCK 이 걸려있을 경우 중지(Abort) 시킨다. SKIP LOCK : LOCK 이 걸려있는 레코드는 무시하고 반환한다.
이 두가지를 어떤 상황에서 활용할 수 있는지 간단한 예시와 함께 알아보자.
NOWAIT 사용 예시
예시 시나리오
- 사용자가 티켓을 예매하려고 한다.
- 여러 좌석 중에 앉을 좌석을 선택하고 결제 진행 한다.
- 사용자가 선택한 좌석이 다른 사용자들에게는 사용불가능한 좌석으로 표시되어야 한다.
이러한 상황에서 Lock 이 걸려있단 것은 누군가 먼저 좌석 예매를 진행하고 있다는 뜻일 것이다. 따라서 NOWAIT를 사용한다면 LOCK이 걸려있다면 사용자에게 빠르게 피드백을 줄 수 있을 것이다.
SELECT * FROM seats WHERE id=100 FOR UPDATE NOWAIT;
ERROR 3572 (HY000) : Statement aborted
because lock(s) could not be acquired immediately and NOWAIT is set.
SKIP LOCK 사용 예시
예시 시나리오
- 선착순으로 쿠폰을 발급함.
이러한 상황에서 Lock 이 걸려있단 것은 누군가 먼저 쿠폰을 발급 받고 있다는 것일 것이다. 따라서 SKIP LOCK를 사용한다면 LOCK이 걸려있는 레코드는 건너뛰어 사용자에게 빠르게 응답을 줄 수 있을 것이다.
SELECT id, code FROM coupons
WHERE status = 'available'
FOR UPDATE SKIP LOCKED LIMIT 1;
LIMIT을 통해 내가 사용할 쿠폰만 LOCK 을 사용한다.
CTE (Common Table Expression)
MySQL 에서는 8.0 부터 추가되었다고 한다.
쿼리 내에서 일시적인 결과 집합을 정의할 수 있는 기능으로, 복잡한 쿼리에서 가독성을 높이고 반복적인 쿼리 로직을 재사용하는 데 유용하다.
뷰와 비슷하면서, 재귀를 사용할 수 있다는 차이도 있다.
예시 1.
WITH revenue0(supplier_no, total_revenue) AS (
SELECT l_suppkey, SUM(l_extendedprice * (1 - l_discount))
FROM lineitem
WHERE l_shipdate >= '1996-07-01'
AND l_shipdate < DATE_ADD('1996-07-01', INTERVAL '90' DAY)
GROUP BY l_suppkey)
SELECT s_suppkey, s_name, s_address, s_phone, total_revenue
FROM supplier, revenue0
WHERE s_suppkey = supplier_no
AND total_revenue = (SELECT MAX(total_revenue) FROM revenue0)
ORDER BY s_suppkey;
출처 : MySQL 8.0: Improved performance with CTE
예시 2.
WITH RECURSIVE EmployeeHierarchy AS (
-- Anchor member: 최상위 상사 (상사가 없는 CEO)
SELECT employee_id, employee_name, manager_id
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- Recursive member: 각 직원에 대해 상사를 찾아가며 하위 직원들 나열
SELECT e.employee_id, e.employee_name, e.manager_id
FROM employees e
INNER JOIN EmployeeHierarchy eh ON e.manager_id = eh.employee_id
)
SELECT * FROM EmployeeHierarchy;
번외 : 코드 어떻게 실행되는지 시각적으로 보는법
CTE 에 대한 글을 찾아보다가 MySQL 공식 블로그에서 다음과 같은 이미지를 볼 수 있었다.
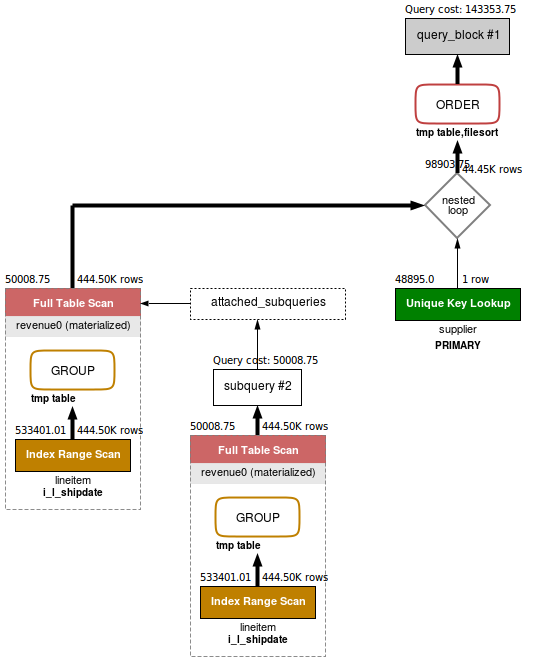
이미지 출처 : MySQL 8.0: Improved performance with CTE
관련해서 찾아보니 MySQL Workbench 제공해주는 VISUAL EXPLAIN 기능이라는 것을 확인하였다.
잘 사용하면 성능 개선 분석을 할 때 유용하게 사용할 수 있을 것으로 보인다.