[MySQL, Java] Java 에서 MySQL Streaming 사용하기
MySQL Streaming
Real MySQL 9장에서는 아래와 같은 내용이 나온다.
9.2.3.3.4.1 스트리밍 방식
서버 쪽에서 처리할 데이터가 얼마인지에 관계 없이 조건에 일치 하는 레코드가 검색될 때마다 바로 바로 클라이언트로 전송해주는 방식을 의미한다. 이 방식으로 쿼리를 처리할 경우 클라이언트는 쿼리를 요청하고 곧바로 원했던 첫 번째 레코드를 전달받는다. 물론 가장 마지막 레코드는 언제 받을지 알 수 없지만, 이는 그다지 중요하지 않다.
이 내용을 읽으면서 든 생각은 ‘MySQL 이 스트리밍 방식으로도 동작할 수 있다니 완전 처음 들어본다’ 였다.
‘그럼 실제 개발시에 스트리밍 방식을 사용할 수 있을까?’ 라는 생각을 하면서 계속 읽어나가보니 아래와 같은 내용과 마주했다.
스트리밍 처리는 어떤 클라이언트 도구나 API를 사용하느냐에 따라 그 방식에 차이가 있을 수도 있다. 대표적으로 JDBC 라이브러리를 이용해
SELECT * FROM bigtable같은 쿼리를 실행하면 MySQL 서버는 레코드를 읽자 마자 클라이언트로 그 결과를 전달할 것이다. 하지만 JDBC는 MySQL 서버로부터 받는 레코드를 일단 내부 버퍼에 모두 담아둔다. 그리고 마지막 레코드가 전달될 때까지 기다렸다가 모든 결과를 전달받으면 그때서야 비로소 클라이언트의 애플리케이션에 반환한다. 즉, MySQL 서버는 스트리밍 방식으로 처리해서 반환하지만 클라이언트의 JDBC 라이브러리가 버퍼링 하는 것이다.
위 내용을 읽으니 왜 스트리밍 방식을 처음 들어본 것인지 이해하였다.
그러면 자바에서 스트리밍 방식을 사용할 수 있는 방법은 없을까?
Java에서 MySQL Streaming 방식으로 데이터 처리하기
찾아본 결과 JPA 에서는 해당 기능을 지원하지 않는것으로 보인다. 하지만 MySQL JDBC Driver 를 직접 사용하면 가능한 것으로 보인다.
MySQL 의 JDBC API 구현 문서를 보면 streaming 방식을 사용할 수 있는 방법에 대해서 설명 해두었다.
ResultSet
By default, ResultSets are completely retrieved and stored in memory. In most cases this is the most efficient way to operate and, due to the design of the MySQL network protocol, is easier to implement. If you are working with ResultSets that have a large number of rows or large values and cannot allocate heap space in your JVM for the memory required, you can tell the driver to stream the results back one row at a time.
To enable this functionality, create a Statement instance in the following manner:
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY, java.sql.ResultSet.CONCUR_READ_ONLY); stmt.setFetchSize(Integer.MIN_VALUE);
요약하면 TYPE_FORWARD_ONLY, CONCUR_READ_ONLY, FETCH_SIZE = Integer.MIN_VALUE 상태의 statement 를 사용하면 streaming 모드로 동작을 한다고 한다.
MySQL Streaming 방식을 사용했을 때 메모리 사용량 비교
MySQL Streaming 방식을 사용했을 때 메모리 사용량 비교를 하기 위해 테스트를 구성하여보았다. 이를 확인하기 위해 intellij profiler 를 사용해서 코드를 실행시켜 비교해보았다. 데이터는 30만건을 사용하였으며 5회 반복하였다.
테스트 세팅 설명
각 테스트 메소드 별 세팅은 다음과 같다.
- testStreamingResultSet : MySQL Streaming 를 통해 데이터를 받아와 사용하도록 처리
- testFindAll : JDBC API를 통해 받아온 데이터를 버퍼에 쌓고 해당 데이터를 일괄 처리 (더 많은 메모리 차지)
- testStreamAll : JDBC API를 통해 데이터를 버퍼에 쌓고 해당 데이터를 일괄 처리 (더 많은 메모리 차지) (Java Stream 이용)
참고로 3번 케이스는 다음과 같은 이유에서 추가하였다.
MySQL Streaming 처리 관련해서 정보를 찾다 보니 일부 글들에서 jpa repository 인터페이스를 구현할 때 Stream 객체를 통해 데이터를 받아와 처리하면 대용량 처리에 도움이 된다는 느낌으로 작성된 것을 볼 수 있었다. (영어로 된 글도 있고, 번역글도 있었다.) 하지만 생각해보면 MySQL Streaming 이 활성화 된 상태가 아니라면 결국 MySQL JDBC API 구현상 모든 쿼리가 종료되어 버퍼에 모인 후에 처리를 진행하게 될 것 이기 때문에 대용량 처리와는 크게 관련이 없을 것이라고 생각하였다. 생각이 맞을지 함께 테스트 해보기로 하였다.
testStreamingResultSet : jdbc 설정을 통해 mysql streaming 을 사용했을 경우
코드는 다음과 같다.
@Test
void testStreamingResultSet() {
String query = "SELECT * FROM user";
try (Connection connection = DriverManager.getConnection(url, user, password);
Statement statement = connection.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)){
statement.setFetchSize(Integer.MIN_VALUE);
try (ResultSet rs = statement.executeQuery(query)) {
while(rs.next()) {
System.out.printf("%s, %s\n", rs.getString("id"), rs.getString("name"));
}
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
testFindAll : JPA Repository 에서 findAll 을 사용했을 경우
코드는 다음과 같다.
@Test
void testFindAll() {
userRepository.findAll().forEach((user -> {
System.out.printf("%s, %s\n", user.getId(), user.getName());
}));
}
testStreamAll : JPA Repository 에서 Stream 객체로 결과 값을 받아올 경우
코드는 다음과 같다.
@Test
@Transactional
void testFindStream() {
userTestRepository.streamAll().forEach((user -> {
System.out.printf("%s, %s\n", user.getId(), user.getName());
}));
}
streamAll 은 다음과 같이 구현하였다.
@Query("select u from User u")
Stream<User> streamAll()
참고로 JPA에서 Stream을 사용한 쿼리는 기본적으로 트랜잭션을 필요로 하기 때문에 이 테스트에는 Transactional 어노테이션이 추가되었다.
결과
아래 이미지와 같이 intellij profiler를 통해 메소드에서 얼만큼의 메모리를 할당해야 했는지를 확인할 수 있었다.
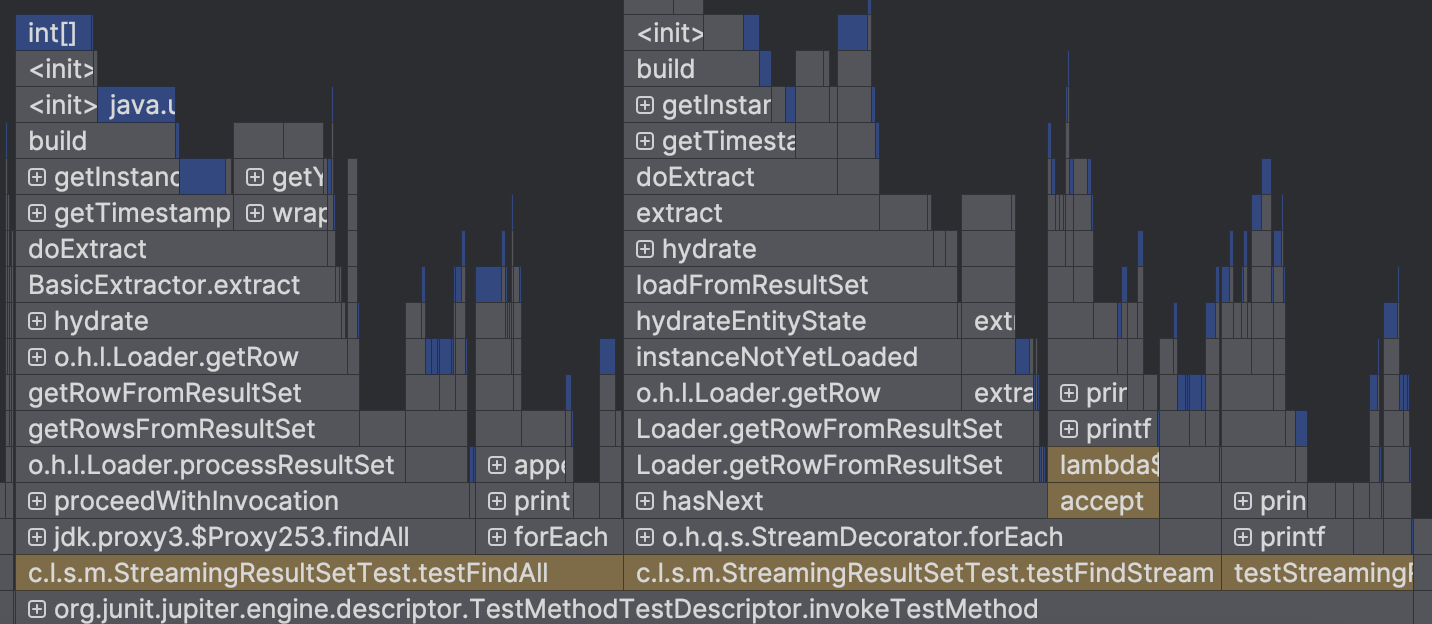
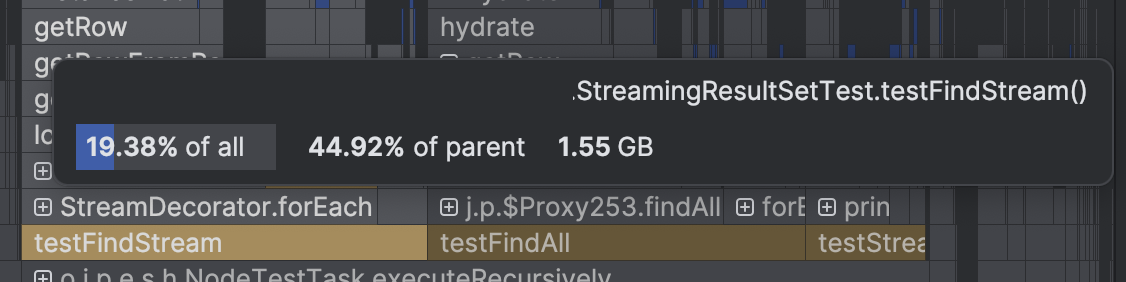
메소드별 할당된 메모리는 다음과 같다.
| 회차 | testStreamingResultSet | testFindAll | testStreamAll |
|---|---|---|---|
| 1 | 456.49MB | 1.45GB | 1.43GB |
| 2 | 452.73MB | 1.46GB | 1.47GB |
| 3 | 457.07MB | 1.44GB | 1.55GB |
| 4 | 449.77MB | 1.48GB | 1.51GB |
| 5 | 450.43MB | 1.45GB | 1.54GB |
| 평균 | 453.30MB | 1.46GB | 1.48GB |
예상했던대로 testFindAll 와 testStreamAll 는 데이터를 버퍼를 통해 쌓인 데이터들을 java 에서 list 로 처리할 것인지 stream 으로 처리할 것인지의 차이이기 때문에 큰 차이가 없는 것을 확인할 수 있었다.
testStreamingResultSet은 MySQL의 streaming 방식을 사용하였기 때문에 전체 데이터가 메모리에 올라가지 않아 메모리를 적게 사용한 것을 확인할 수 있었다. 대략 1기가 정도 차이가 발생되었다.