[MySQL] 아키텍처 - Real MySQL 스터디 1회차
아키텍처 - Real MySQL 스터디 1회차
책 소개
1회차였기 때문에 본격적인 진행에 앞서 먼저 책의 구성을 확인하고 진행하였다. Real MySQL 8.0 은 1, 2권으로 구성되어 있고 다음과 같은 챕터로 구성되어 있다.
1권
▣ 01장: 소개 ▣ 02장: 설치와 설정 ▣ 03장: 사용자 및 권한 ▣ 04장: 아키텍처 ▣ 05장: 트랜잭션과 잠금 ▣ 06장: 데이터 압축 ▣ 07장: 데이터 암호화 ▣ 08장: 인덱스 ▣ 09장: 옵티마이저와 힌트 ▣ 10장: 실행 계획
2권
▣ 11장: 쿼리 작성 및 최적화 ▣ 12장: 확장 검색 ▣ 13장: 파티션 ▣ 14장: 스토어드 프로그램 ▣ 15장: 데이터 타입 ▣ 16장: 복제 ▣ 17장: InnoDB 클러스터 ▣ 18장: Performance 스키마 & Sys 스키마
MySQL 아키텍처
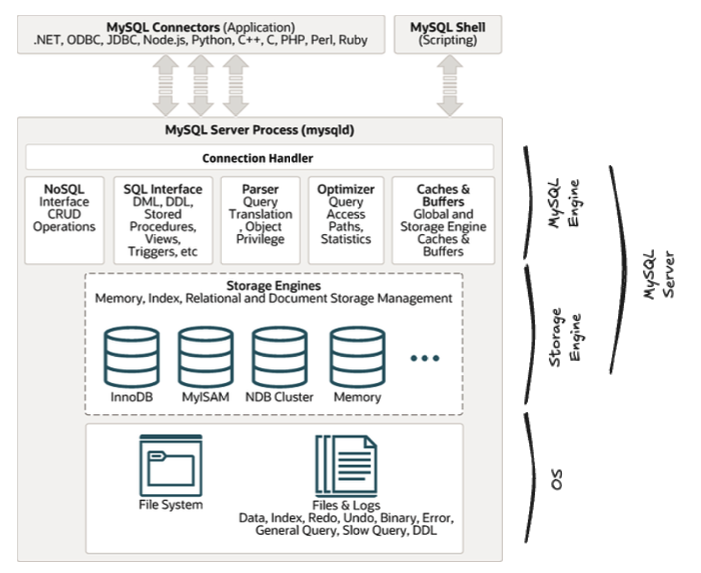
책에서는 Connection Handler 까지 묶어서 Mysql Engine으로 그림을 구성하였기에 공식 자료를 조금 수정하여 추가해보았다.
Mysql Engine
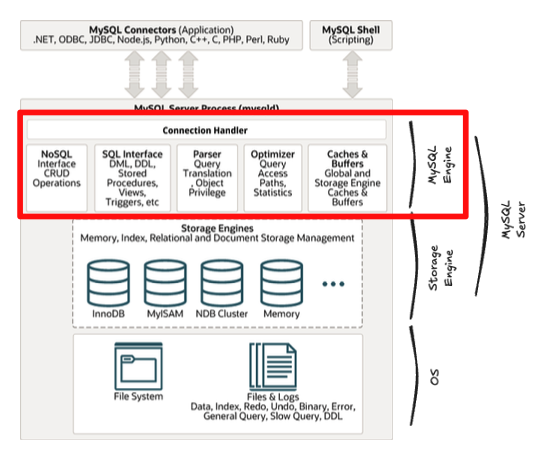
- 요청된 SQL 문장을 분석 및 최적화 함. (뇌에 해당)
- 주요 구성
- 커넥션 핸들러
- 클라이언트로부터의 접속 및 쿼리 요청을 처리
- SQL 파서 및 전처리기
- 옵티마이저
- 쿼리 최적화
- 쿼리 실행기
- 커넥션 핸들러
Storage Engine
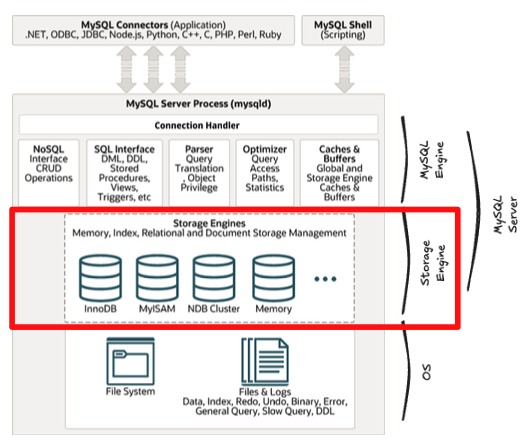
- 실제 데이터를 디스크 스토리지에 저장하거나 디스크 스토리지로부터 데이터를 읽어옴.
- 여러 유형은 엔진을 사용할 수 있음.
- 기본 값으로는 InnoDB 가 사용됨.
Handler API
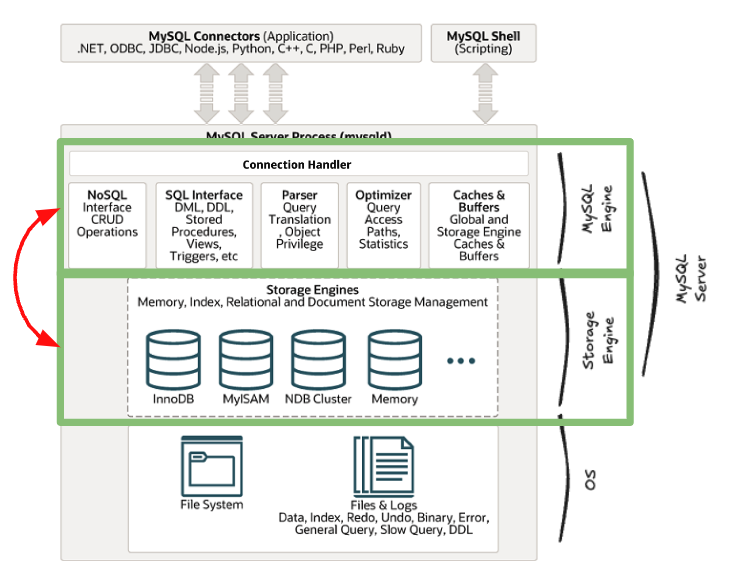
- MySQL 엔진의 쿼리 실행기에서 데이터를 쓰거나 읽어야 할 때 각 스토리지 엔진에 쓰기 또는 읽기를 요청할 때 사용되는 API
MySQL 스레딩 구조
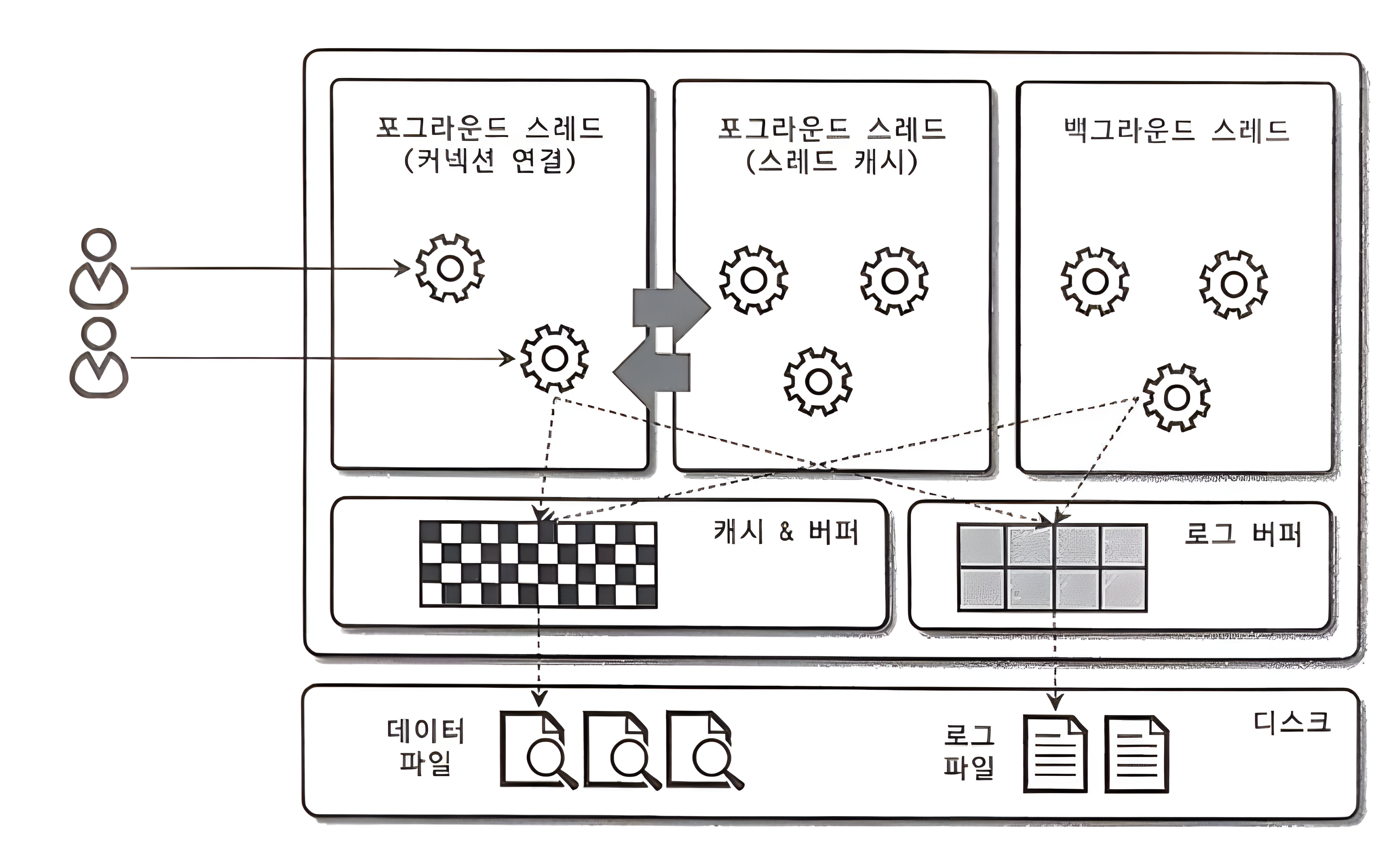
MySQL 은 스레드 기반으로 작동한다. 스레드는 크게 Foreground Thread 와 Background Thread 로 구분할 수 있다.
Foreground Thread
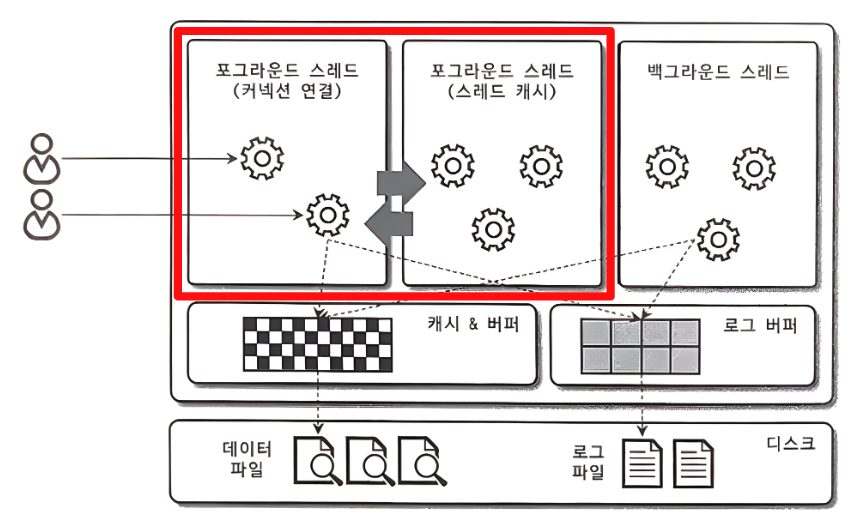
- Foreground Thread는 최소한 MySQL 서버에 접속된 클라이언트의 수만큼 존재
- MySQL은 커넥션마다 쓰레드를 생성하는 구조이다.
- 클라이언트가 작업을 마치고 커넥션을 종료하면 스레드 캐시로 돌아간다.
- 이미 스레드 캐시에 일정 개수 이상의 스레드가 대기중이라면 캐시에 넣지 않고 종료시킨다.
- 데이터를 MySQL의 데이터 버퍼나 캐시로부터 가져온다.
- 버퍼나 캐시에 없을 경우 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와서 작업을 처리한다.
Background Thread
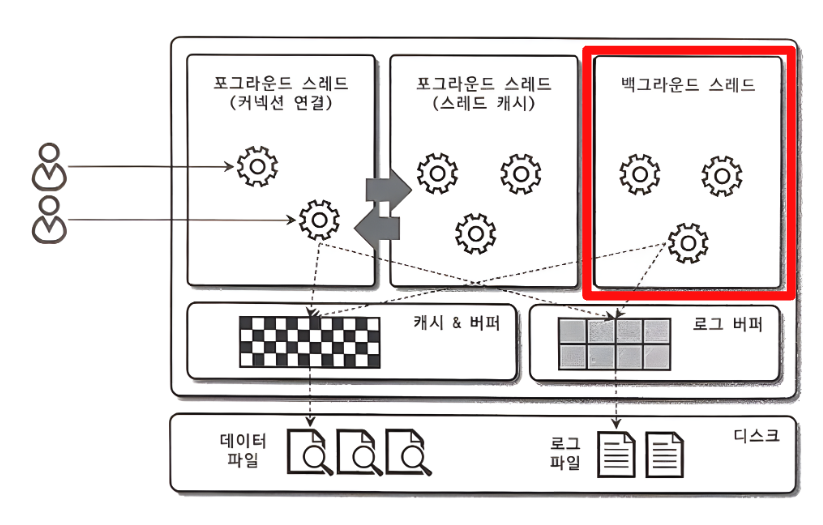
버퍼로부터 디스크에 기록하는 작업을 담당.
- 주요 작업
- 인서트 버퍼 병합
- 로그를 디스크에 기록 (로그 스레드, Log Thread)
- 버퍼 풀의 데이터를 디스크에 기록 (쓰기 스레드, Write Thread)
- 데이터를 버퍼로 읽어옴
- 잠금이나 데드락 모니터링
쓰기 작업은 지연(버퍼링)되어 처리될 수 있지만 데이터의 읽기 작업은 절대 지연될 수 없다. 따라서 쓰기 작업을 버퍼링해서 일괄 처리한다.
MySQL 메모리 구조
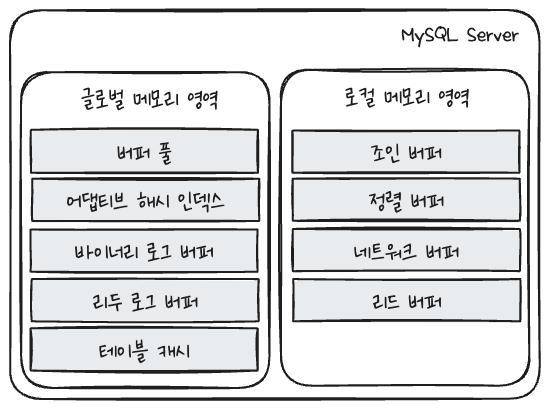
- 메모리 공간은 크게 글로벌 메모리 영역과 로컬 메모리 영역으로 구분할 수 있다.
- 모든 메모리 공간은 MySQL 서버가 시작되면서 운영체제로부터 할당된다.
- 운영체제에 따라 100% 할당해줄수도, 예약해두고 조금씩 할당해줄 수도 있다.
글로벌 메모리 영역
- 클라이언트의 수와 무관하게 할당된다.
- 일반적으로 하나로만 관리된다.
- 모든 스레드에 의해 공유된다.
- 대표적인 글로벌 메모리 영역
- 버퍼 풀
- 어댑티브 해시 인덱스
- 바이너리 로그 버퍼
- 리두 로그 버퍼
- 테이블 캐시
로컬 메모리 영역
- 클라이언트 스레드가 쿼리를 처리하는데 사용하는 메모리 영역이다.
- 세션(커넥션) 메모리 영역 이라고도 부른다.
- 대표적인 세션 메모리 영역
- 조인 버퍼
- 정렬 버퍼
- 네트워크 버퍼
- 리드 버퍼
- 로컬 메모리는 각 클라이언트 스레드별로 독립적으로 할당되며 절대 공유되어 사용되지 않는다.
- 할당되어 유지되는 공간도 있고 (커넥션 버퍼, 결과 버퍼), 필요시에만 할당되었다가 다시 해제하는 공간도 있다. (소트 버퍼, 조인 버퍼)
컴포넌트 아키텍처
엔진, 파서, 인증 / 암호화 등 MySQL 에 필요한 부분들을 컴포넌트 형태로 구성할 수 있도록 구현되어 있음.
쿼리 실행 구조
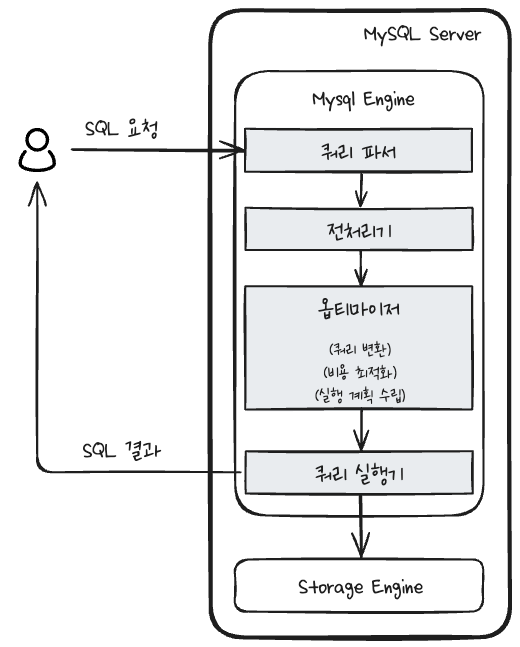
쿼리 파서
사용자가 요청한 쿼리 문장을 트리 형태의 구조로 만든다. 이 과정에서 기본 문법 오류를 확인한다.
전처리기
파서 트리를 기반으로 구조적인 문제점이 있는지 확인한다. 테이블 이름, 컬럼 이름, 내장함수 같은 객체들이 존재하고, 접근할 수 있는 권한이 있는지 등을 확인한다.
옵티마이저
쿼리를 어떻게 처리할지를 결정한다. 저렴한 비용으로 가장 빠르게 처리되면 이상적이다. 실행 계획을 수립한다.
실행 엔진 (실행기)
수립된 실행 계획에 따라 핸들러 API를 실행한다. 이때 핸들러는 InnoDB 스토리지 엔진이다.
스레드 풀
- MySQL은 엔터프라이즈 에디션에서 스레드 풀을 제공한다. (커뮤니티 에디션은 제공하지 않음)
- 스레드 풀은 내부적으로 사용자의 요청을 처리하는 스레드 개수를 줄여서 동시 처리되는 요청이 많다하더라도 CPU가 제한된 개수의 스레드 처리에만 집중할 수 있게 하여 서버의 자원 소모를 줄이는 것이 목적이다.
- 사용한다고 무조건 성능이 향상되지는 않는다. 스케줄링 과정에서 CPU 시간을 제대로 확보하지 못하는 경우에는 더 느려질 수 있다.
- 적절히 설정된다면 불필요한 컨텍스트 스위치를 줄여서 오버헤드를 낮출 수 있다.
- 스레드 풀은 기본적으로 CPU 코어의 갯수만큼 생성해준다.
메타데이터
- 데이터베이스 서버에서 테이블의 구조 정보와 스토어드 프로그램 등의 정보를 메타데이터 또는 데이터 딕셔너리 라고 한다.
- 8.0 이전에는 파일 형태로 관리되어 트랜잭션이 지원되지 않았지만 8.0 부터는 데이터베이스 내의 테이블에 저장하도록 개선되어 트랜잭션을 지원 한다.
- 스키마 변경 작업 중간에 MySQL 서버가 비정상적으로 종료된다고 하더라도 스키마 변경이 완전한 성공 또는 완전한 실패 로 정리된다. (기존과 달리 테이블이 깨지는 일이 발생되지 않음.)
- 시스템 테이블 과 메타데이터 들은 mysql DB 에 저장된다.
- mysql DB는 통째로 mysql.ibd라는 이름의 테이블스페이스에 저장된다.
InnoDB 스토리지 엔진 아키텍처
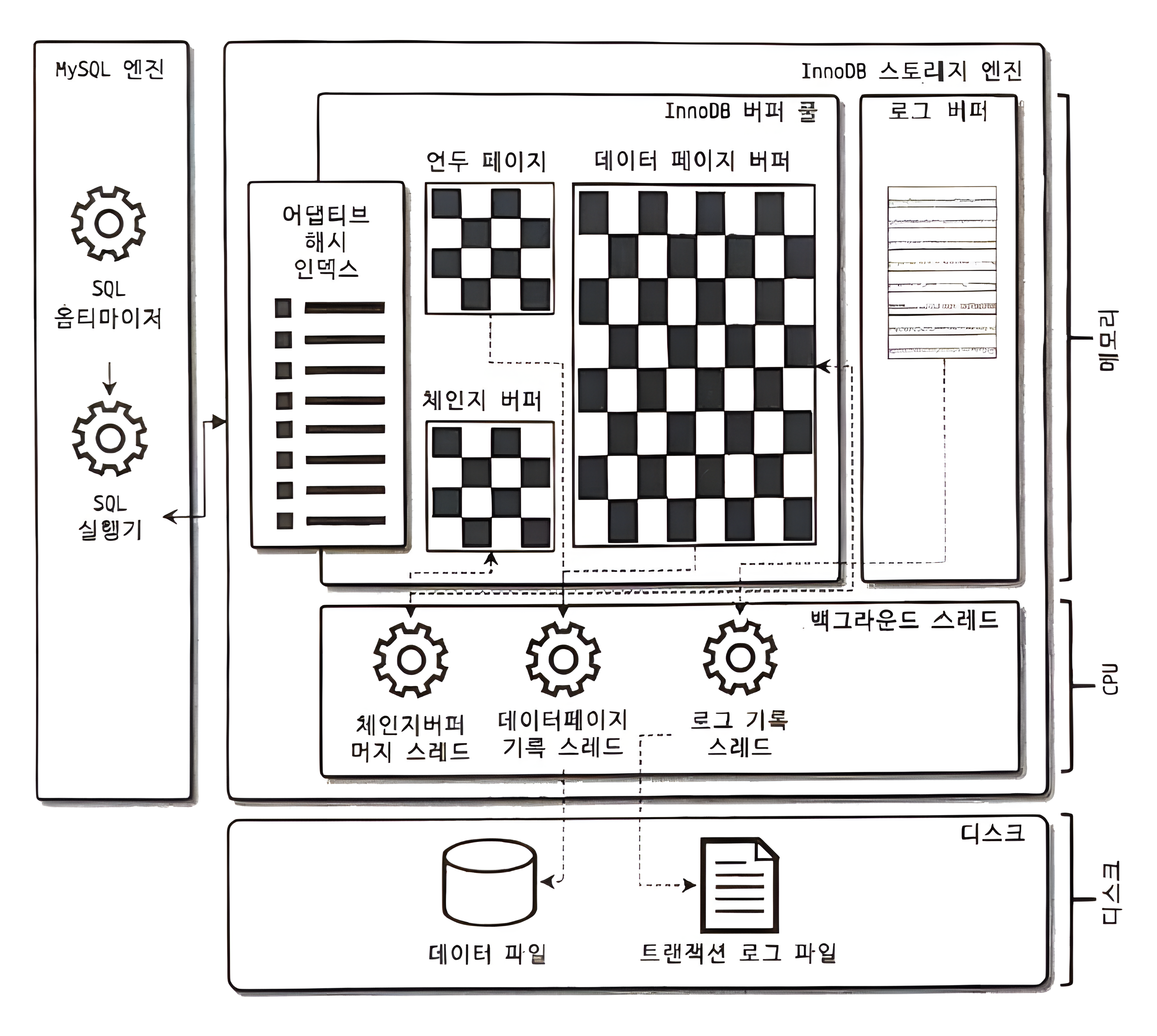
- InnoDB는 레코드 기반 잠금을 제공
- 높은 동시성 처리 지원
- 프라이머리 키에 의한 클러스터링
- 키 값의 순서대로 디스크에 저장
- 레인지 스캔을 빠르게 처리
- 세컨더리 인덱스는 레코드의 주소 대신 프라이머리 키의 값을 논리적인 주소로 사용
- 외래 키 지원
버퍼 풀
- 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시 해두는 공간
- 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할도 수행
- 버퍼를 통해 변경된 데이터를 모아서 처리하면 랜덤 디스크 작업의 횟수를 줄일 수 있다.
아래에서 별도의 파트로 더 자세히 다룬다.
페이지
- InnoDB가 디스크(데이터 파일)와 메모리(버퍼 풀) 간에 한 번에 전송하는 데이터의 양을 나타내는 단위
- 페이지에는 각 행의 데이터 양에 따라 하나 이상의 행이 포함될 수 있음.
- 더티페이지: 버퍼 풀에서 아직 디스크로 기록되지 않은 데이터
리두 로그
- 시스템 장애 복구를 위해 사용.
- 데이터의 최종 상태를 복구하는 데 사용 (일관성 보장)
- 데이터의 변경이 발생되었을 때 기록된다.
언두 로그
- 트랜잭션 롤백을 위해 사용.
- 트랜잭션 내에서 데이터를 변경했을 때 변경되기 전의 데이터(이전 데이터)를 보관하는 곳
- 트랜잭션의 격리 수준을 유지하면서 높은 동시성을 제공
리두 로그와 언두 로그 정리
리두 로그 는 데이터베이스의 상태를 앞으로 나아가게 만드는 역할을 한다. (너 이거 디스크에 기록 완료 했어? 안했네? 그럼 해야해)
언두 로그 는 데이터베이스의 상태를 뒤로 되돌리는 역할을 한다. (너 이거 디스크에 기록 했어? 이거 커밋 안된거라 다시 복구 해야해)
리두 로그는 모든 변경사항을 기록한다고 했는데 왜 언두로그도 필요할까?
리두 로그는 모든 변경 사항을 기록하지만, 커밋되지 않은 트랜잭션의 변경 사항을 롤백할 수 있는 정보를 제공하지 않는다. 단지 변경 사항을 다시 적용하는 역할로만 사용할 수 있다. 트랜잭션이 커밋되지 않은 상태에서 비정상적인 종료가 발생 되면 먼저 리두 로그를 이용해 최종 커밋된 상태로 되돌리고, 언두 로그를 이용해 완료되지 않은 트랙잭션 데이터를 롤백한다.
체인지 버퍼
레코드 INSERT 되거나 UPDATE 될 때 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행하지만 그렇지 않고 디스크로부터 읽어와서 업데이트해야 한다면 이를 즉시 실행하지 않고 임시 공간(= 체인지 버퍼)에 저장해 두고 바로 사용자에게 결과를 반환하는 형태로 성능을 향상시킨다. * 유니크 인덱스는 체인지 버퍼를 사용할 수 없다. 반드시 중복 여부를 체크해야 하기 때문
어댑티브 해시 인덱스
InnoDB 스토리지 엔진에서 사용자가 자주 요청하는 데이터에 대해 자동으로 생성하는 인덱스
다음의 경우에 유용하다.
- 디스크의 데이터가 InnoDB 버퍼 풀 크기와 비슷한 경우 (디스크 읽기가 많지 않은 경우)
- 동등 조건 검색(동등 비교와 IN 연산자)이 많은 경우
- 쿼리가 데이터 중에서 일부 데이터에만 집중되는 경우
SHOW ENGINE INNODB STATUS 명령어를 통해서 사용 빈도를 확인할 수 있다.
상황에 따라 비활성화 하여 버퍼 풀이 더 많은 메모리를 사용할 수 있도록 유도하는게 좋을 수도 있다.
버퍼 풀의 구조
스토리지 엔진은 버퍼 풀이라는 거대한 메모리 공간을 페이지로 나누어 관리한다.
버퍼 풀은 크게 아래의 3개의 자료 구조로 관리한다.
- LRU 리스트 (Least Recently Used)
- 플러시 리스트 (Flush)
- 프리 리스트 (Free) : 비어있는 공간을 관리
버퍼 풀은 여러 개로 관리할 수 있다. (버퍼 풀 인스턴스, innodb_buffer_pool_instances)
LRU 리스트
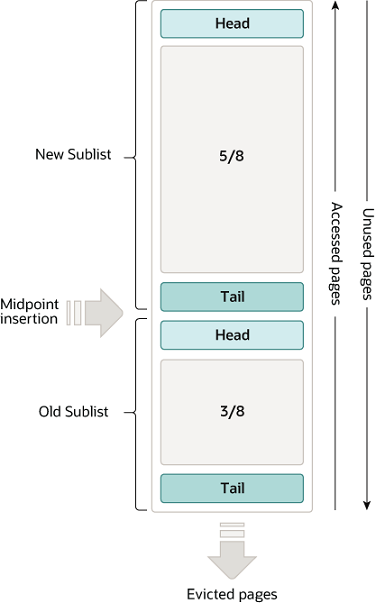
이미지 출처 : mysql doc - innodb buffer pool
Least Recently Used : 가장 오랫동안 사용되지 않은 페이지를 제거하는 전략
InnoDB의 LRU 리스트는 2개의 LRU 리스트가 결합된 형태이다. 데이터가 처음 추가될 때 5/8 지점에 삽입이 된다.
이 구조의 장점은 무엇일까? 자주 사용되지 않는 데이터가 LRU list에 추가되었을 때, 더 빨리 방출될 수 있을 것이다.
버퍼 풀과 리두 로그
버퍼 풀은 데이터 캐시와 쓰기 버퍼링 역할을 한다. 버퍼 풀의 메모리 용량만 늘릴 경우에는 캐시 기능만 향상된다. 쓰기 버퍼링 기능까지 향상시키려면 리두 로그의 크기도 적절히 설정해줘야 한다.
체크 포인트 : 리두 로그와 데이터 페이지의 상태를 동기화. 체크포인트는 리두 로그 파일이 가득 차거나 일정 시간이 경과하는 등 특정 조건에 따라 발생
리두 로그는 순환(circular)의 형태를 가지고 있음. LSN : Log Sequence Number, 현재 로그를 기록할 위치를 기록 체크포인트 에이지(Checkpoint Age) : 마지막 체크포인트 지점의 LSN 와의 값 차이
버퍼 풀 플러시
InnoDB는 더티 페이지들을 성능상의 악영향 없이 디스크에 동기화 될 수 있도록 2개의 플러시 기능을 백그라운드에서 실행한다.
- 플러시 리스트 플러시
- LRU 리스트 플러시
플러시 리스트 플러시
플러시 리스트(더티 페이지(디스크에서 변경되야할 데이터)를 관리하는 리스트)에서 오래전에 변경된 데이터 페이지를 순서대로 디스크에 동기화 하는 작업.
더티 페이지를 디스크로 동기화 하는 스레드를 클리너 스레드 라고 한다. 버퍼 풀에 더티 페이지가 많으면 많을수록 디스크 쓰기 폭발(Disk IO Burst) 현상이 발생될 가능성이 높아진다. (적절히 유지해야 한다.)
어댑티브 플러시 기능을 활성화 하면 리두 로그의 증가 속도를 분석해서 적정한 수준의 더티 페이지가 버퍼 풀에 유지될 수 있도록 디스크 쓰기를 실행한다.
LRU 리스트 플러시
- LRU 리스트의 끝부분부터 시작해서 시스템 변수(innodb_lru_scan_depth)로 설정된 갯수만큼 스캔한다.
- 스캔 중 더티페이지가 있을 경우 디스크에 동기화한다.
- 동기화된 페이지는 프리 리스트로 옮긴다.
Double Write Buffer
리두 로그는 공간 낭비를 막기 위해 페이지의 변경된 내용만 기록한다. 더티 페이지를 디스크 파일로 플러시할 때 일부만 기록되는 문제가 발생하면 그 페이지의 내용은 복구할 수 없을 수도 있다. (이러한 페이지를 파셜 페이지 partial-page, 톤 페이지 torn-page 라고 함.) 이를 방지하기 위해 Double Write 기법을 사용한다.
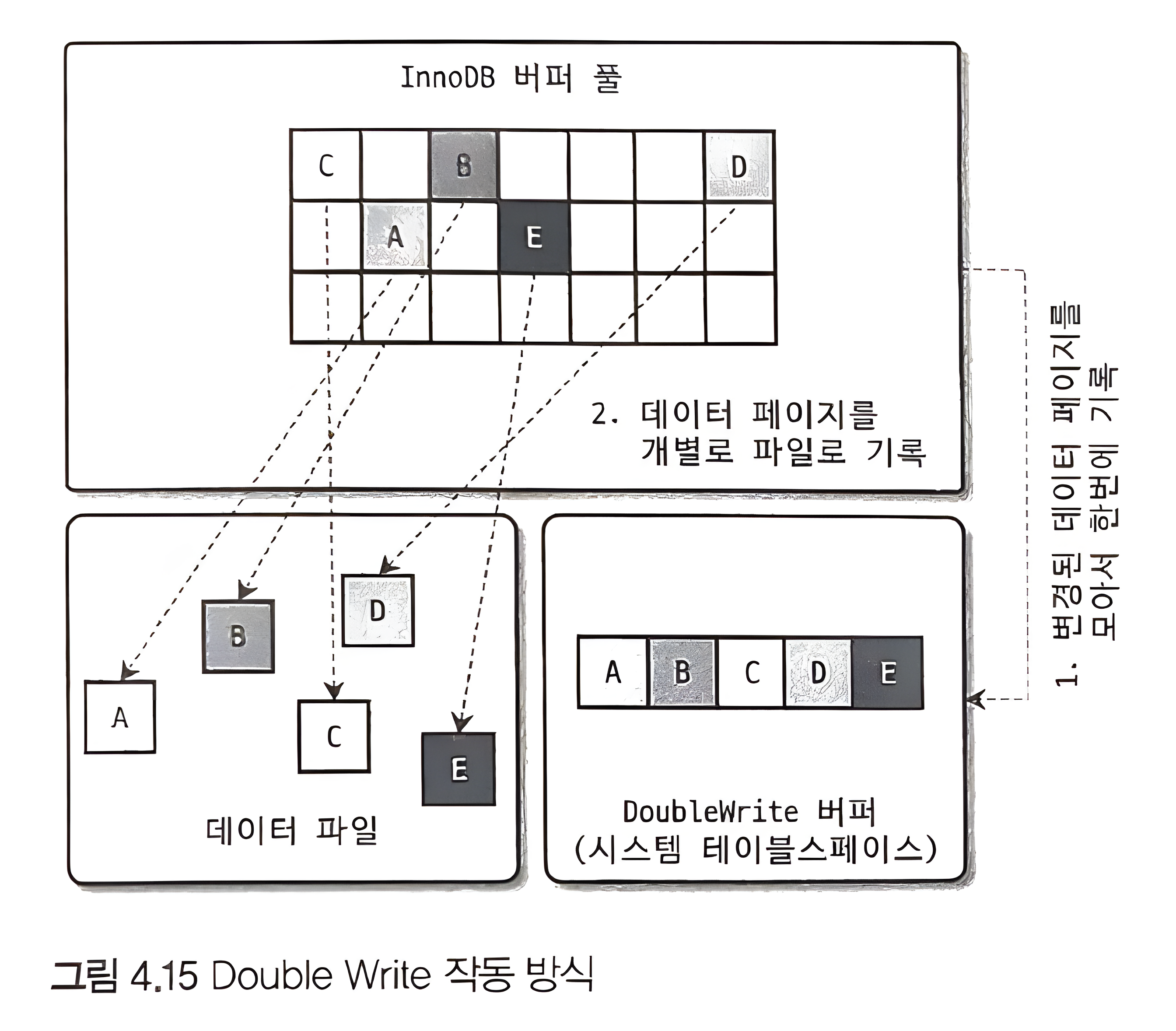
컨셉은 두 번 작성하는 것이다. 먼저 변경사항을 시스템 테이블스페이스의 DoubleWrite 버퍼에 한번에 기록한다. 이후 변경사항을 개별 데이터 파일로 기록한다. 만약 파일에 정상적으로 저장되었다면, DoubleWrite 버퍼에 기록한 데이터는 더 이상 필요하지 않다.
버퍼 풀 상태 확인
innodb_cache_indexes 테이블로 테이블별로 데이터 페이지가 얼마나 InnoDB 버퍼 풀에 적재돼 있는지 확인할 수 있다.
버퍼 풀 상태 백업 및 복구
MySQL 서버를 셧다운했다가 다시 시작하면, 평상시보다 쿼리 처리 성능이 낮다. 아직 버퍼 풀에 데이터가 적재되어 있지 못하기 때문이다.
MySQL 서버를 셧다운 하기 전에 버퍼 풀을 백업했다가 이후 다시 시작할 때 복구하면 처리 성능이 낮아지는 현상을 줄일 수 있다.
innodb_buffer_pool_dump_at_shutdown, innodb_buffer_pool_load_at_startup 옵션을 통해 자동으로 처리되게 할 수 있다.
버퍼 풀 적정 크기 설정 팁
- InnoDB 기본 값 : 134217728 byte = 128 MB
- 운영체제의 전체 메모리가 8GB 미만이라면, 50% 정도만 버퍼 풀로 설정하고 나머지 메모리 공간은 MySQL 서버와 운영체제, 그리고 다른 프로그램이 사용할 수 있는 공간으로 확보해주는 것이 좋다.
- 운영체제의 전체 메모리가 8GB 이상이라면, 50% 에서 시작해서 조금씩 올려가면서 최적점을 찾는다.
- 운영체제의 전체 메모리가 50GB 이상이라면, 대략 15GB에서 30GB 정도를 운영체제와 다른 응용 프로그램을 위해서 남겨두고 나머지를 버퍼풀로 할당한다.
MVCC (Multi Version Concurrency Control)
언두로그를 이용하여 잠금을 사용하지 않는 일관된 읽기를 제공 멀티 버전 : 하나의 레코드에 대해 여러 개의 버전이 동시에 관리됨.
잠금 없는 일관된 읽기 (Non-Locking Consistent Read)
격리 수준이 Serializable이 아닌 경우, 읽기 작업은 다른 트랜잭션의 변경 작업과 관계없이 잠금을 대기하지 않고 바로 실행된다.
Transaction (트랜잭션)
* 이 부분에 대해서는 다음 챕터인 트랜잭션에서 더 자세히 다루겠지만 간단히 정리하고 넘어간다.
트랜잭션 : 커밋하거나 롤백할 수 있는 작업의 원자 단위
트랜잭션이 데이터베이스를 변경하는 경우, 트랜잭션이 커밋될 때 모든 변경 사항이 성공하거나 트랜잭션이 롤백될 때 모든 변경 사항이 취소된다.
Commit / Rollback
- Commit 명령을 실행하면 더 이상의 변경 작업 없이 지금의 상태를 영구적인 데이터로 만들어 버린다.
- Rollback 명령을 실행하면 언두 영역에 있는 백업된 데이터를 InnoDB 버퍼 풀로 다시 복구하고, 언두 영역의 내용을 삭제해 버린다.
- 커밋이 된다고 언두 영역의 백업 데이터가 항상 바로 삭제되는 것은 아니다. 이 언두 영역을 필요로 하는 트랜잭션이 더는 없을 때 삭제된다.
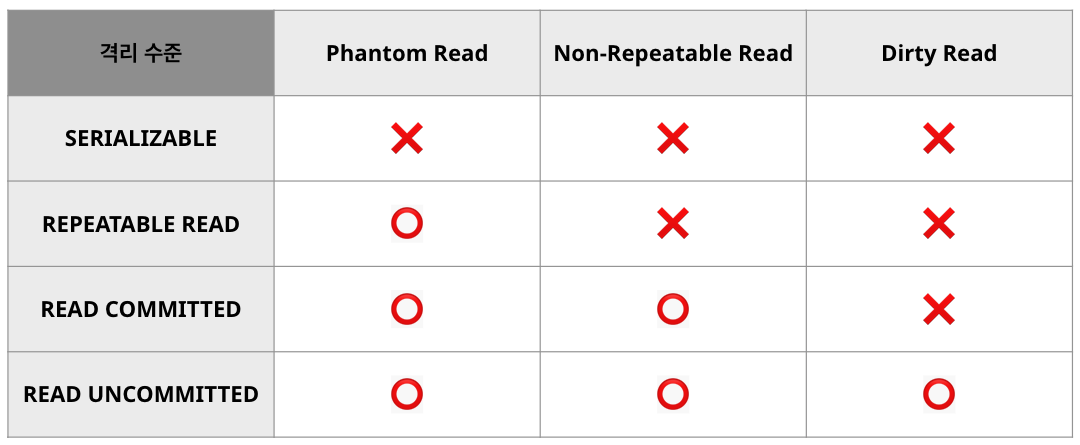
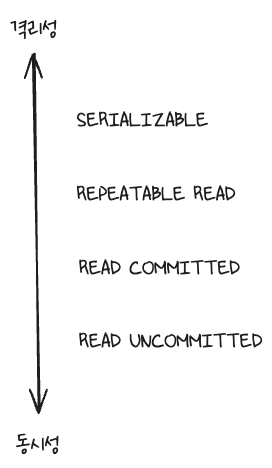
Transaction Isolation Levels (격리 수준)
transaction isolation levels described by the SQL:1992 standard
- READ UNCOMMITTED
- 현재 버퍼풀이 가지고 있는 데이터를 읽어서 반환한다.
- 아직 커밋되지 않은 변경사항을 조회할 수 있다. (Dirty Read)
- READ COMMITTED
- 현재 커밋되어 있는 데이터를 읽어서 반환한다.
- 다른 트랜잭션에 의해 데이터가 변경될수도 있다. (Non-Repeatable Read)
- REPEATABLE READ (default in mysql)
- 한 트랜잭션 내에서 항상 같은 데이터를 응답하는 것을 보장한다.
- 조회할 때는 보이지 않았던 새로운 데이터가 생기거나 데이터가 없어질 수 있다. (Phantom Read)
- SERIALIZABLE
- 트랜잭션간의 간섭이 전혀 발생되지 않는다.
ACID
- 원자성 (atomicity) : 부분적으로 실행되다가 중단되지 않는 것을 보장한다는 것을 의미
- 일관성 (consistency) : 트랜잭션 처리 전과 처리 후 데이터 모순이 없는 상태를 유지
- 격리성 (isolation) : 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장
- 내구성 (durability) : 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함
언두 로그 레코드 모니터링
트랜잭션이 불필요하게 오래 유지 될 경우 언두 로그의 양이 급증할 수 있다. 디스크 공간을 많이 차지 하는 것은 물론이고, 언두 로그의 이력을 불필요하게 많이 스캔해야 하기 때문에 쿼리의 성능이 낮아지는 것이 문제이다. 언두 로그 레코드가 얼마나 되는지 모니터링 하는 것이 좋다.
언두 테이블스페이스 관리
언두 로그는 항상 시스템 테이블스페이스 외부의 별도 로그 파일에 기록. 언두 로그 공간이 남는 것은 크게 문제가 되지 않지만, 언두 로그 슬롯이 부족한 경우에는 트랜잭션을 시작할 수 없는 심각한 문제가 발생할 수 있다.
자동 데드락 감지
내부적으로 잠금 대기 목록을 관리한다. 데드락 감지 스레드가 주기적으로 잠금 대기 목록을 검사해 교착 상태에 빠진 트랜잭션을 찾아 그 중 하나를 강제 종료한다.
innodb_table_locks 시스템 변수를 활성화 하면 스토리지 엔진 내부의 레코드 잠금뿐만 아니라 테이블 레벨의 잠금까지 감지할 수 있다.
자동은 항상 트레이드 오프가 있다. 동시 처리 스레드가 매우 많은 경우 데드락 감지 스레드는 더 많은 CPU 자원을 소모할 수도 있다.
자동 장애 복구
InnoDB에는 손실이나 장애로부터 데이터를 보호하기 위한 여러 가지 메커니즘이 탑재돼 있다. 일반적으로 서버를 실행할 때 자동으로 복구를 진행한다. 자동으로 복구 될 수 없는 손상이 발생될 경우, 자동 복구를 멈추고 MySQL 서버는 종료된다. 이 때는 케이스별로 수동 복구를 진행해야한다.
- 1(SRV_FORCE_IGNORE_CORRUPT)
- 테이블스페이스나 인덱스 페이지 손상
- 2(SRV_FORCE_NO_BACKGROUND)
- 메인 스레드가 언두 데이터를 삭제하는 과정에서 장애가 발생
- 메인 스레드를 사용하지 않음.
- 3(SRV_FORCE_NO_TRX_UNDO)
- 트랜잭션 롤백 하는 과정에서 장애 발생
- 4(SRV_FORCE_NO_IBUF_MERGE)
- 인서트 버퍼의 손상
- 5(SRV_FORCE_NO_UNDO_LOG_SCAN)
- 언두 로그의 손상
- 언두 로그를 스캔 하지 않음.
- 6(SRV_FORCE_NO_LOG_REDO)
- 리두 로그의 손상
백업이 있다면 마지막 백업으로 데이터베이스를 새로 구축한다. 바이너리 로그가 있다면 최대한 장애 시점까지의 데이터를 복구할 수 있다.
MySQL Log 파일 종류
- error log
- 시작 하는 과정에서 발생된 에러
- 의도치 않은 종료 메시지
- 비정상 종료 복구 메시지
- 쿼리 처리중 발생된 에러
- 비정상으로 종료된 커넥션 메시지
- general log
- 실행된 모든 쿼리 기록
- slow query log
- 실행된 쿼리중 오래걸리는 쿼리를 기록
- long_query_time (default : 10s)
- pt-query-digest 스크립트를 사용하면 쉽게 분석가능