[Review] 초보자를 위한 랭체인 - 랭체인 데브콘 LA : 유월엔 랭체인
[Review] 2024-06-22(토) K-DEVCON LA : 유월엔 랭체인
데브콘 블로그에도 남겼지만 내 블로그에도 정리한 내용을 남겨본다.
개요
6월 22일(토) 에는 K-DEVCON LA 챕터에서 <데브콘 LA : 유월엔 랭체인> 이라는 주제로 온라인 세미나가 진행되었습니다.
지난 5월 행사에 이어 AI와 관련된 주제로 행사가 진행되었습니다.

이번 세미나는 줌으로 진행되었습니다.
LangChain에 대한 이야기를 정말 많이 들어봤었는데 이번 세미나를 통해서 LangChain이 무엇이고, 어떤 역할을 하는지 코드와 함께 살펴볼 수 있었습니다.
이번 세미나를 통해 재밌게 보았던 부분들을 정리해보았습니다.
LangChain 이란
LangChain은 대규모 언어 모델(LLM)을 기반으로 애플리케이션을 구축하기 위한 오픈 소스 프레임워크입니다.
LangChain의 도구와 API를 통해 LLM 기반 애플리케이션을 구축하는 과정을 간소화할 수 있습니다.
LangChain에 대한 설명은 인터넷에서 쉽게 찾아볼 수 있습니다.
dev container
https://code.visualstudio.com/docs/devcontainers/containers
devcontainer를 사용하면 도커를 이용하여 로컬개발환경을 구축할 수 있습니다. 이를 통해 깔끔한 환경 구성이 가능하게 됩니다.
Token calculator
토큰은 AI 모델이 작동하는 기본 구성 요소입니다. 모델은 입력된 단어를 토큰으로 변환합니다. 출력시 토큰을 다시 단어로 변환합니다.
중요한 것은 토큰 = 돈 이라는 것입니다.
https://platform.openai.com/tokenizer
위 링크는 openai 의 토큰 계산기 입니다. 영어에서 하나의 토큰은 대략 단어의 75%에 해당한다고 합니다.

Chat model vs LLMs
https://python.langchain.com/v0.1/docs/modules/model_io/concepts/
LangChain에서는 두가지 모델을 제공합니다. Chat model과 LLMs 인데요.
LLMs는 순수 텍스트 완성 모델이고 Chat model은 채팅에 좀 더 특화되어 있습니다.
Chat model 은 메시지 주고 받습니다. 그리고 모든 메시지에는 역할과 콘텐츠 속성이 있습니다.
역할은 누가 말하는지를 설명하고 콘텐츠는 메시지의 내용을 의미합니다.
Chat model - 역할
역할은 크게 HumanMessage, AIMessage, SystemMessage 가 있습니다. 각각에 대해 간단하게 설명하면 다음과 같습니다.
- system message : 시스템에 대한 메세지 (모델이 어떻게 동작할지에 대해 정의)
- human message : 사용자가 입력한 메세지
- ai message : ai가 출력한 메세지 (assistant, openai term)
Temperature
LangChain을 통해 OpenAI 의 모델을 초기화 할 때 temperature 라는 속성 값을 넣을 수 있는데요

이 속성 값은 무작위성에 영향을 미치는데 값이 클수록 출력이 더 무작위로 나오고 값이 작을수록 값이 비슷하게 나온다고 합니다.
관련해서 Seed 라는 속성 값에 대한 언급도 있었습니다.
LangChain express language(LCEL)
https://python.langchain.com/v0.1/docs/expression_language/
LangChain express language(LCEL, 랭체인 표현 언어)는 체인을 쉽게 구성하는 선언적 방법입니다.
LCEL을 사용하면 기본 구성 요소로 복잡한 체인을 쉽게 구축할 수 있으며 스트리밍, 병렬 처리, 로깅과 같은 기본 기능을 지원합니다.
LCEL을 사용하여 다양한 구성 요소를 단일 체인으로 통합할 수 있습니다. | (pipe) 를 이용해서 체인으로 결합할 수 있으며. 예시는 다음과 같습니다.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
chain.invoke({"topic": "ice cream"})
Output Parser 라는 것 외에는 Function Calling 으로 처리할 수 있는 방법도 있다고 한합니다.
Prompt engineering
지난 5월 행사에서는 CoT (Chain of Thought) 라는 기법에 대해서 소개해주셨는데 이번에는 아래의 세가지 방법에 대해서 소개해주셨습니다.
- Zero Shot : 모델에게 예제를 제공하지 않음
- One Shot : 모델에게 예제를 한번만 제공
- Few Shot : 모델에게 예제를 몇 번 제공 (6개 미만으로 주는게 좋다고 함.)
LangChain Smith (LangSmith)
개인적으로 재밌게 본 플랫폼인데요. 내 어플리케이션이 chain 을 따라 어떻게 동작하는지 각 단계별로 볼 수 있었습니다. LLM을 로깅, 모니터링 해주는 플랫폼 이였습니다.
LangChain hub
LangChain hub에서는 내가 만든, 혹은 다른 사람들이 만든 프롬프트를 공유할 수 있었습니다.
검색증강생성 (RAG, Retrieval Augmented Generation)
이번 세미나를 통해서 개인적으로 더 가까워질 수 있었던 개념입니다.
기존부터 RAG에 대한 이야기는 많이 들었는데 대략적인 이해만 하고 있었다가 이번 기회를 통해서 이해를 할 수 있었습니다.
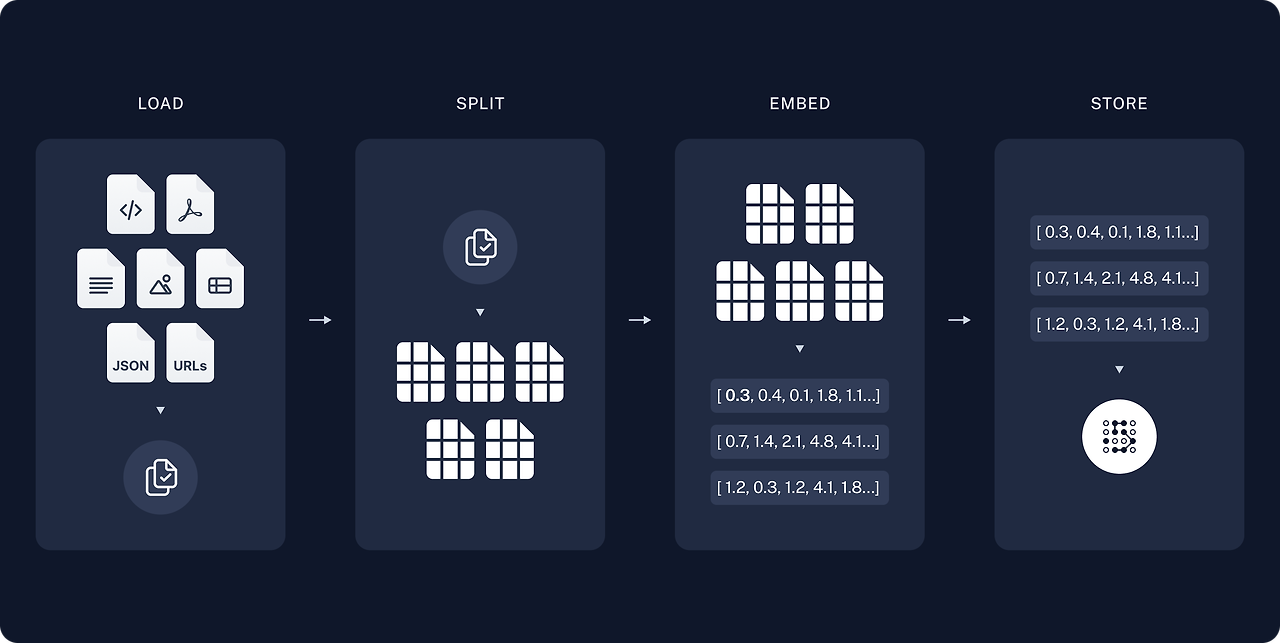
RAG 는 크게 두 단계로 나누어 집니다.
- 전처리
- 서비스
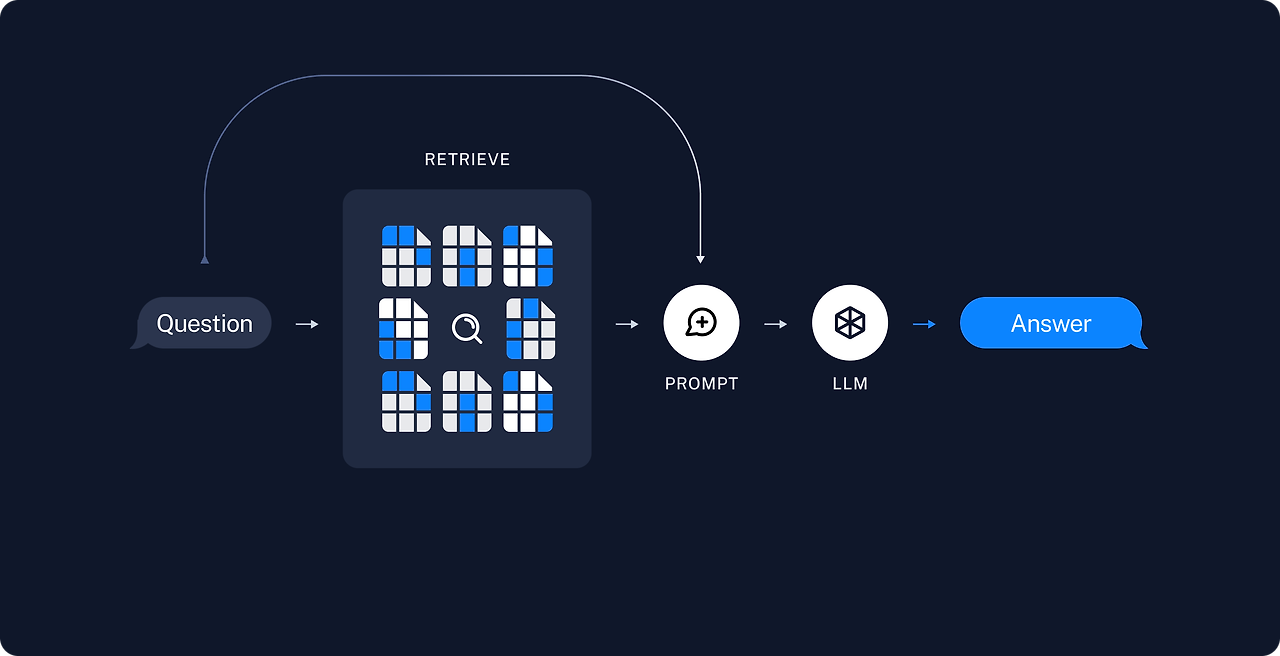
RAG에는 임베딩 이라는 것이 진행되는데, 실제적으로 경험을 해본적이 없다보니 실제로는 어떻게 진행되는지 궁금했었는데요 이번 세미나에서는 설명과 함께 예시를 보여주셔서 쉽게 이해할 수 있었습니다.
전처리 과정에서는 어떻게 기존에 있던 문서들을 적절하게 자를 수 있는지가 포인트인 것 같았습니다. 적절히 자른 데이터는 백터화 하여 벡터 DB에 저장을 합니다.
서비스 과정에서는 벡터 DB에서 유사도를 검사하여 관련된 키워드/문장들을 추출 해내고, 추출된 값을 LLM에 담아 활용하도록 합니다.
코드 예시는 다음과 같습니다.
from langchain_openai import OpenAIEmbeddings
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.storage import LocalFileStore
from langchain_community.document_loaders import UnstructuredMarkdownLoader
splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)
loader = UnstructuredMarkdownLoader("files/kubernetes_hardening_guidance.md")
docs = loader.load_and_split(text_splitter=splitter)
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
# 임베딩을 해서 디비에 넣는다.
vectorstore = FAISS.from_documents(docs, embeddings)
results = vectorstore.similarity_search("누구에게 이 가이드를 추천하는가?")
# 유사도 검사를 통해 관련된 문장을 찾아온다. 이것을 프롬프트에 담아 llm에 보낸다.