Spring AI 사용을 위한 AI 핵심 컨셉 (2) - 토큰, 구조화된 출력, 모델 튜닝, 함수 호출, RAG, 평가
아래 글은 spring ai 의 doc 을 번역하여 옮긴 것입니다.
원문 : AI Concepts
Spring AI 사용을 위한 AI 핵심 컨셉 (1) 에서 이어지는 글입니다.
토큰 (Tokens)
토큰은 AI 모델이 작동하는 기본 구성 요소입니다. 모델은 입력된 단어를 토큰으로 변환합니다. 출력시 토큰을 다시 단어로 변환합니다.
영어에서 하나의 토큰은 대략 단어의 75%에 해당합니다. 참고로, 셰익스피어 전집은 약 90만 단어로 구성되어 있으며, 이는 약 120만 토큰에 해당합니다.

더 중요한 것은 토큰 = 돈이라는 것입니다. 호스팅된 AI 모델에서는 사용된 토큰 수에 따라 요금이 결정됩니다. 입력과 출력 모두 전체 토큰 수에 영향을 미칩니다.
모델에는 토큰 제한(limits)이 있습니다. 한 번의 API 호출에서 처리할 수 있는 텍스트의 양이 제한됩니다. 이 임계값을 ‘컨텍스트 창(context window)’라고 부르기도 합니다. 모델은 이 제한을 초과하는 텍스트는 처리하지 않습니다.
예를 들어 ChatGPT3에는 4K 토큰 제한이 있는 반면 GPT4는 8K, 16K, 32K와 같은 다양한 옵션을 제공합니다. Anthropic의 Claude AI 모델은 100K 토큰 제한을 특징으로 하며, Meta의 최근 연구에서는 1M 토큰 제한을 가지는 개인 모델이 도출되었습니다.
셰익스피어 전집을 GPT4로 요약하려면, 데이터를 잘게 쪼개 모델의 컨텍스트 창 제한 내에서 데이터를 표현(present) 해야합니다. Spring AI 프로젝트는 이러한 작업에 도움을 줄 수 있습니다.
구조화된 출력 (Structured Output)
AI 모델의 출력물은 JSON 형태로 답변을 요청해도 java.lang.String (문자열) 입니다. 내용물은 올바른 JSON 형태일 수 있지만, 결국에는 문자열일 뿐입니다. 또한 프롬프트에 JSON 형태로 요청하여도 100% 정확하지는 않습니다.
이러한 복잡성으로 인해 의도한 출력을 생성하기 위한 프롬프트 생성과 그 출력으로 나오는 단순한 문자열을 응용 프로그램 통합을 위해 사용 가능한 데이터 구조로 변환하는 전문 분야가 등장하게 되었습니다.
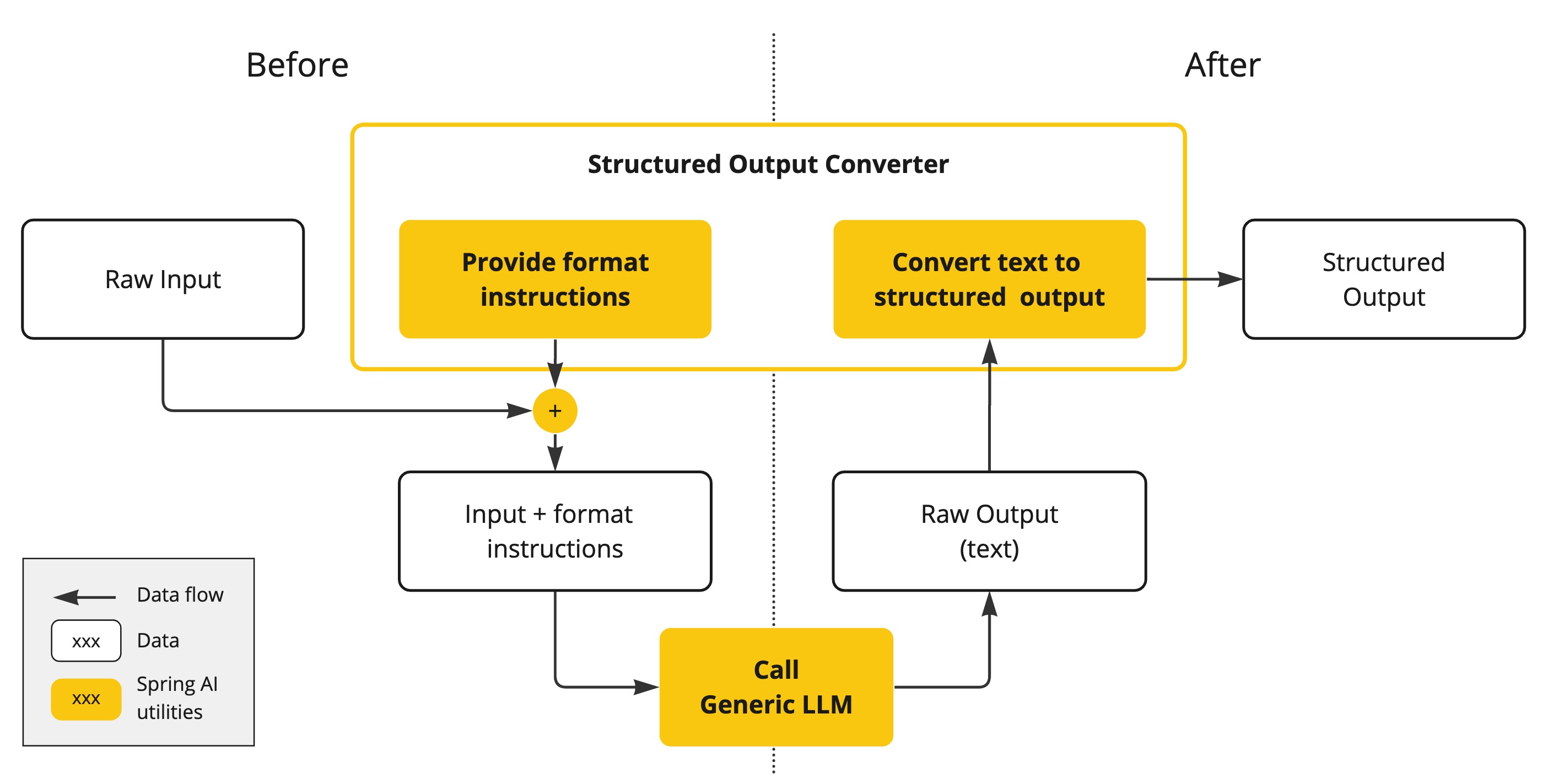
구조화 된 출력 변환은 세심하게 제작된 프롬프트를 사용하며, 원하는 형태를 얻기 위해 종종 모델과 여러 번의 상호 작용이 필요하기도 합니다.
데이터 및 API를 AI 모델로 가져오기 (Bringing Your Data & APIs to the AI Model)
AI 모델에 학습되지 않은 정보를 어떻게 적용(equip)할 수 있을까요?
GPT 3.5/4.0 데이터 셋은 2021년 9월 까지의 데이터로 적용(extends)되어 있습니다. 따라서 이 모델은 해당 날짜 이후의 지식이 필요한 질문에 대한 답을 모른다고 말합니다. 참고로 이 데이터 셋의 용량은 약 650GB입니다.
데이터를 적용하기 위해 AI 모델을 사용자 정의(customizing)할 수 있는 세 가지 기술이 있습니다.
파인 튜닝 (Fine Tuning)
전통적인 기계 학습 기술 입니다. 모델을 조정하고 내부 가중치를 변경하는 작업이 포함됩니다. 이는 어려운 프로세스이며 GPT와 같은 모델의 경우 크기로 인해 리소스가 많이 요구됩니다(resource-intensive). 또한 일부 모델에서는 이 옵션을 제공하지 않을 수도 있습니다.
프롬프트 스터핑 (Prompt Stuffing)
보다 실용적인 대안입니다. 모델에 제공된 프롬프트 내에 데이터를 삽입(embedding)하는 것입니다. 모델의 토큰 제한을 고려하여, 모델의 컨텍스트 윈도우 내에서 관련 데이터를 제공하기 위한 기술이 필요합니다. Spring AI 라이브러리는 RAG(Retrieval Augmented Generation)로 알려진 “프롬프트 채우기(stuffing the prompt)” 기술을 기반으로 솔루션을 구현하는데 도움을 줍니다.
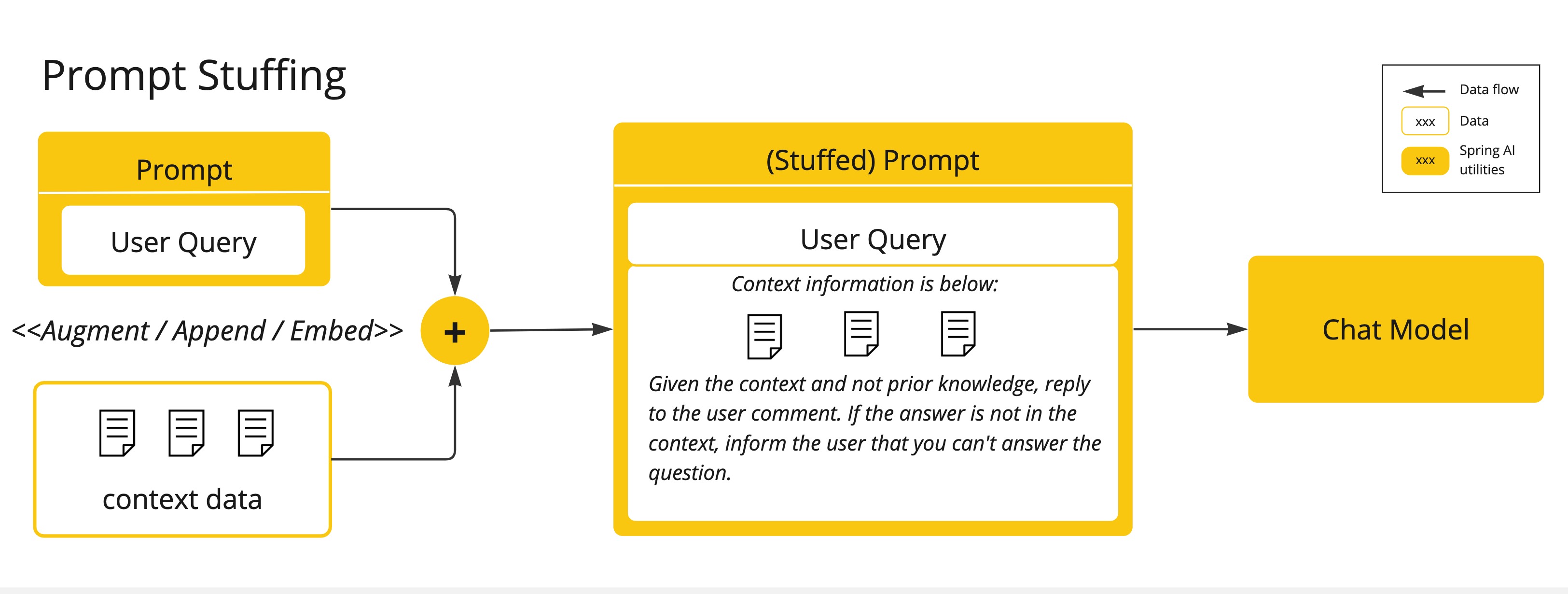
함수 호출(Function Calling)
이 기술을 사용하면 대규모 언어 모델을 외부 시스템의 API에 연결하는 사용자 정의 사용자 함수를 등록할 수 있습니다. Spring AI는 함수 호출을 사용하기 위해 작성해야 하는 코드를 크게 간소화합니다.
검색증강생성 (RAG, Retrieval Augmented Generation)
AI 모델의 정확한 응답을 위해 관련 데이터를 프롬프트에 통합할 수 있도록 하는 검색 증강 생성(RAG, Retrieval Augmented Generation)이라는 기술이 등장하였습니다.
이 기술은 문서에서 구조화되지 않은 데이터(비정형 데이터, unstructured data)를 읽고 변환한 다음, 벡터 데이터 베이스 쓰는 일괄 처리(batch processing) 방식으로 접근합니다.
이는 전체적인 관점(high level)에서 봤을 때 ETL(추출, 변환 및 로드) 파이프라인입니다. 벡터 데이터베이스는 RAG 기술의 검색 부분에서 사용됩니다.
구조화되지 않은 데이터를 벡터 데이터베이스에 로드하는 과정에서 가장 중요한 변환 중 하나는 원본 문서를 더 작은 조각으로 분할하는 것입니다. 원본 문서를 작은 조각으로 분할하는 절차에는 두 가지 중요한 단계가 있습니다.
- 콘텐츠의 의미적 경계를 유지하면서 문서를 여러 부분으로 분할해야 합니다. 예를 들어, 단락과 표가 있는 문서의 경우 단락이나 표 중간에 문서를 분할하지 않아야 합니다. 코드의 경우 메서드 구현 중간에 코드를 분할하지 않아야 합니다.
- AI 모델 토큰 제한보다 작은 크기로 분할되어야 합니다.
RAG의 다음 단계는 사용자 입력을 처리하는 것입니다. 사용자가 AI 모델에 질문할 때, 질문과 유사한(similar) 모든 문서 조각이 AI 모델에 전송되는 프롬프트에 포함됩니다. 이것이 벡터 데이터베이스를 사용하는 이유입니다. 벡터 데이터베이스는 유사한 콘텐츠를 찾는 데 매우 능숙합니다.
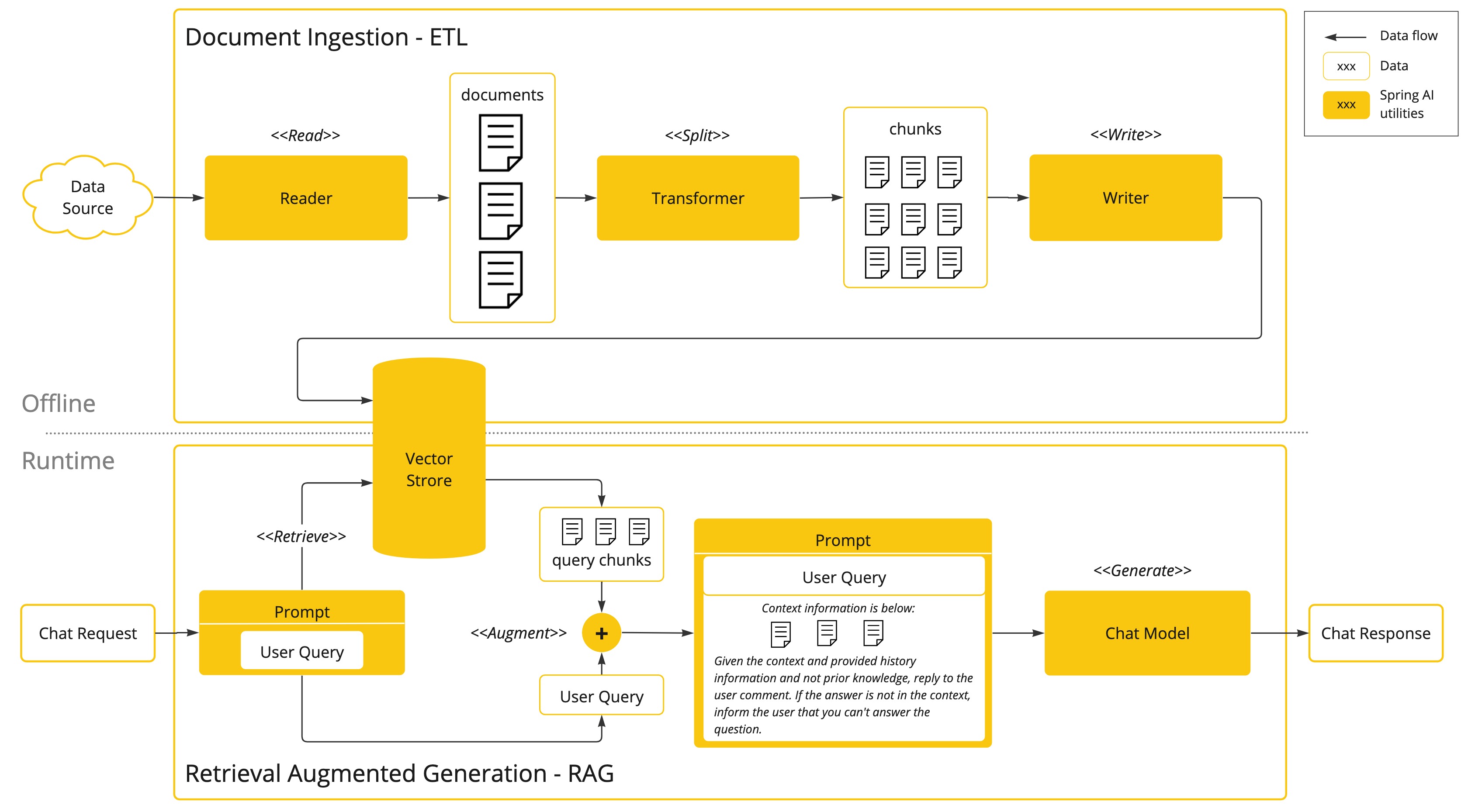
ETL 파이프라인은 데이터 소스에서 데이터를 추출하고 구조화된 벡터 스토어에 저장하는 흐름을 조율하여 데이터가 AI 모델이 추출하는데 최적의 형태가 되도록 추가 정보를 제공합니다.
ChatClient - RAG 문서에서는
QuestionAnswerAdvisor Advisor를 사용하여 애플리케이션에서 RAG 기술을 사용 하는 방법을 설명합니다.
함수 호출 (Function Call)
LLM(대규모 언어 모델)은 학습 후 고정됩니다. 이로인해 오래된 정보를 가지게 있게 됩니다. 외부의 데이터에 액세스하거나 수정할 수는 없습니다.
함수 호출 메커니즘은 이러한 단점을 해결합니다. 이 메커니즘은 자체 함수를 등록하여 대규모 언어 모델을 외부 시스템의 API에 연결할 수 있습니다. 이를 통해 LLM에 실시간 데이터를 제공하고 LLM을 대신하여 데이터 처리 작업을 수행할 수 있습니다.
Spring AI는 함수 호출을 지원하기 위해 작성해야 하는 코드를 크게 줄여줍니다. 함수 호출과 관련된 상호작용을 대신 처리해 줍니다. 함수를 @Bean으로 제공한 다음 프롬프트 옵션에 함수의 Bean 이름을 제공하면 해당 함수를 활성화할 수 있습니다. 또한 하나(single)의 프롬프트에서 여러 함수를 정의하고 참조할 수 있습니다.
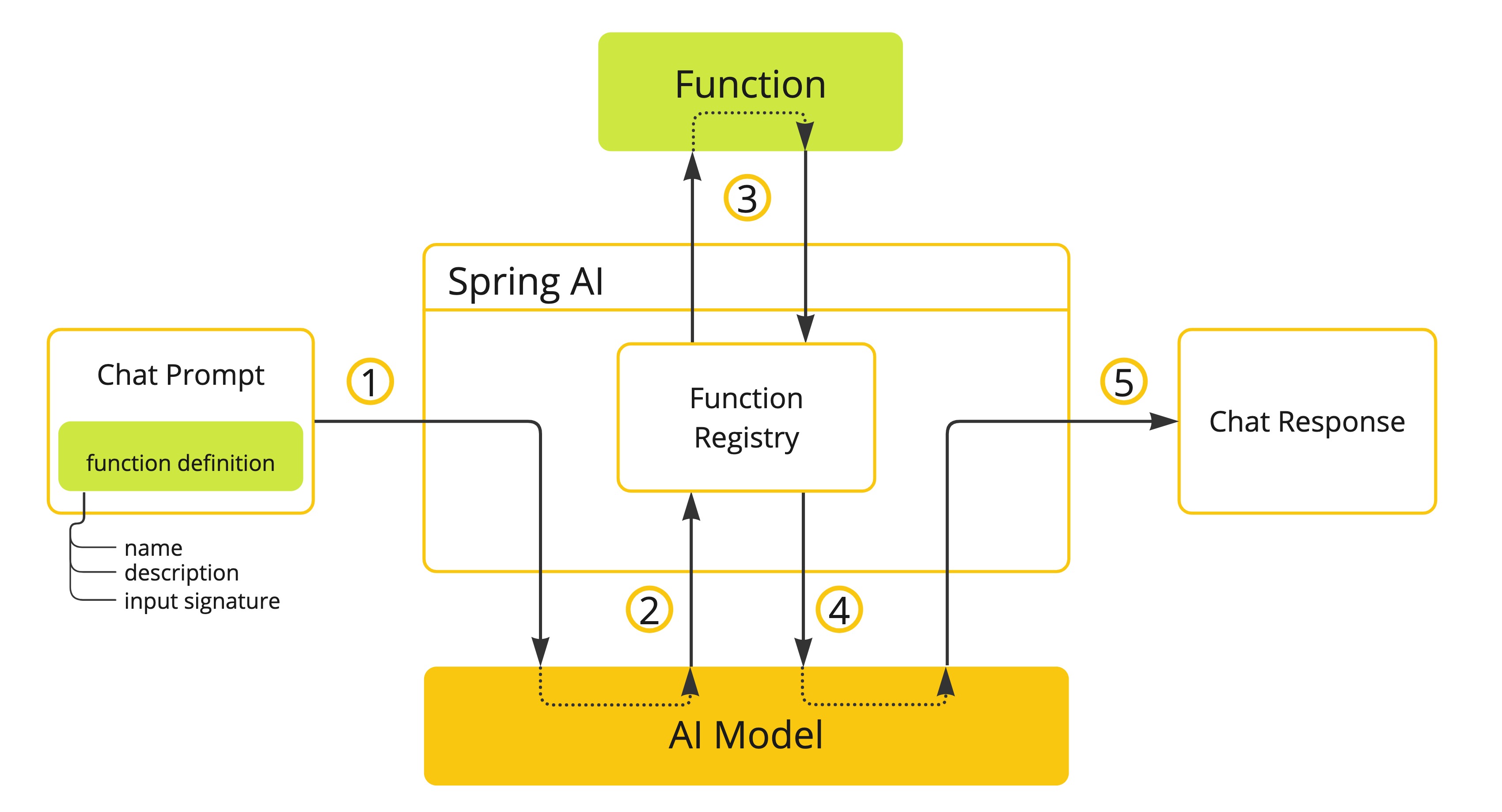
정의한 함수에 대한 정보와 함께 채팅 요청을 수행합니다. 이후
이름,설명(예: 모델이 언제 함수를 호출해야 하는지 설명),입력 매개변수(예: 함수의 입력 매개변수 스키마)를 제공합니다.모델은 함수가 호출되어야 할 때 입력 받은 매개변수를 사용하여 함수를 호출하고 출력을 모델에 반환합니다.
이 과정에서 Spring AI가 상호작용을 처리합니다. 적절한 함수를 호출하고 그 출력을 모델에 반환합니다.
모델은 여러 함수 호출을 수행하여 필요한 모든 정보를 검색할 수 있습니다.
필요한 모든 정보가 반영되면 모델은 응답을 생성합니다.
다양한 AI 모델에서 이 기능을 사용하는 방법에 대한 자세한 내용은 함수 호출 설명 문서를 참고하세요.
AI 응답 평가 (Evaluating AI responses)
애플리케이션의 정확성과 유용성을 보장하기 위해서는 사용자 요청에 대한 AI 시스템의 출력을 효과적으로 평가하는 것이 매우 중요합니다. 몇 가지 새로운 기술들은 이러한 목적으로 사전 훈련된 모델 자체를 사용하는 것을 가능하게 합니다.
이 평가 프로세스에는 생성된 응답이 사용자의 의도 및 쿼리 컨텍스트와 일치하는지 분석하는 작업이 포함됩니다. 관련성, 일관성, 사실적 정확성과 같은 지표는 AI 생성 응답의 품질을 측정하는 데 사용됩니다.
한 가지 접근 방식은 사용자의 요청과 AI 모델의 응답을 모두 모델에 제시하고 응답이 제공된 데이터와 일치하는지 쿼리하는 것입니다.
또한, 벡터 데이터베이스에 저장된 정보를 보조 데이터로 활용하면 평가 프로세스를 개선하여 응답 관련성을 판단하는 데 도움이 될 수 있습니다.
Spring AI 프로젝트는 현재 JUnit 테스트에서 프롬프트를 이용하여 응답을 평가할 수 있는 방법에 대한 매우 기본적인 예시를 제공하고 있습니다.