프롬프트 엔지니어링 (정의, 체이닝, 튜닝, RAG) - 데브콘 서울 : 오월엔 AI
지난 5월 30일 K-DEVCON은 네이버 클라우드의 콜라보로 “데브콘 서울 : 오월엔 AI” 행사를 진행하였다. (festa 링크)
요즘 개발자라면 AI와 LLM에 관심이 있을 수밖에 없을 것 같다. 나 역시도 그 중 한명이다.
이 글에서 정리할 내용은 네이버 클라우드의 오정식 님께서 발표하신 내용의 일부인데 이론적인 이야기들을 매우 잘 설명해주셨다고 생각되서 해당 발표자료의 내용과 추가적으로 보충 설명을 함께 정리해서 블로그에 올려본다.
평소에 프롬프트 엔지니어링에 대해 관심이 있었다. 이번 행사는 이와 관련된 많은 키워드들을 배워갈 수 있었던 시간이였다. 기대보다도 더 재밌게 참여하였다.
프롬프트의 정의
자연어로 설명하고 지시하여 원하는 결과물을 출력할 수 있게 하는 입력 값 (업무 메뉴얼과 같은 것)
시스템, 사용자, 어시스턴트
- 시스템은 목표와 행동을 가진 AI, 특정 작업이나 규칙을 정의하고 사용자와의 상호 작용 방식을 결정
- 어시스턴트는 사용자와 시스템 간의 중개 역할, 실질적으로 사용자와 상호작용
- 사용자는 시스템과 상호 작용하는 사람, 당신
Chain of thought (CoT)
CoT(Chain-of-Thought)는 최종 결과를 생성할 때 필요한 중간 과정 및 추론 과정을 모델 스스로 생성할 수 있게 만드는 프롬프트 방법이다. 모델 규모가 커질수록 산술적 추론, 상식적 추론 등 추론 능력을 갖게 되고, CoT 프롬프트는 초거대언어모델(LLM)의 추론 능력을 크게 향상시킬 수 있다.
예시는 다음과 같다.

모델 input에 왜 답이 그렇게 나오는지에 대해서 과정을 알려준다.
추가 참고
실제 업무에 적용하는 법
- 1단계: 최종 목표 설정
- 최종 목표를 명확하게 설정한다
- 2단계: 논리적인 순서 설정
- 논리적인 순서대로 생각을 정리하고, 순서를 설정한다
- 3단계: 프롬프트 설계
- 각 생각을 프롬프트로 설계한다. 만약 각 프롬프트가 2가지 이상 답변을 만든다면 2단계를 다시 한다
- 4단계: 벡터DB 필요 프롬프트 선정
- 벡터DB를 이용하여 입력데이터를 만드는 프롬프트를 선별한다
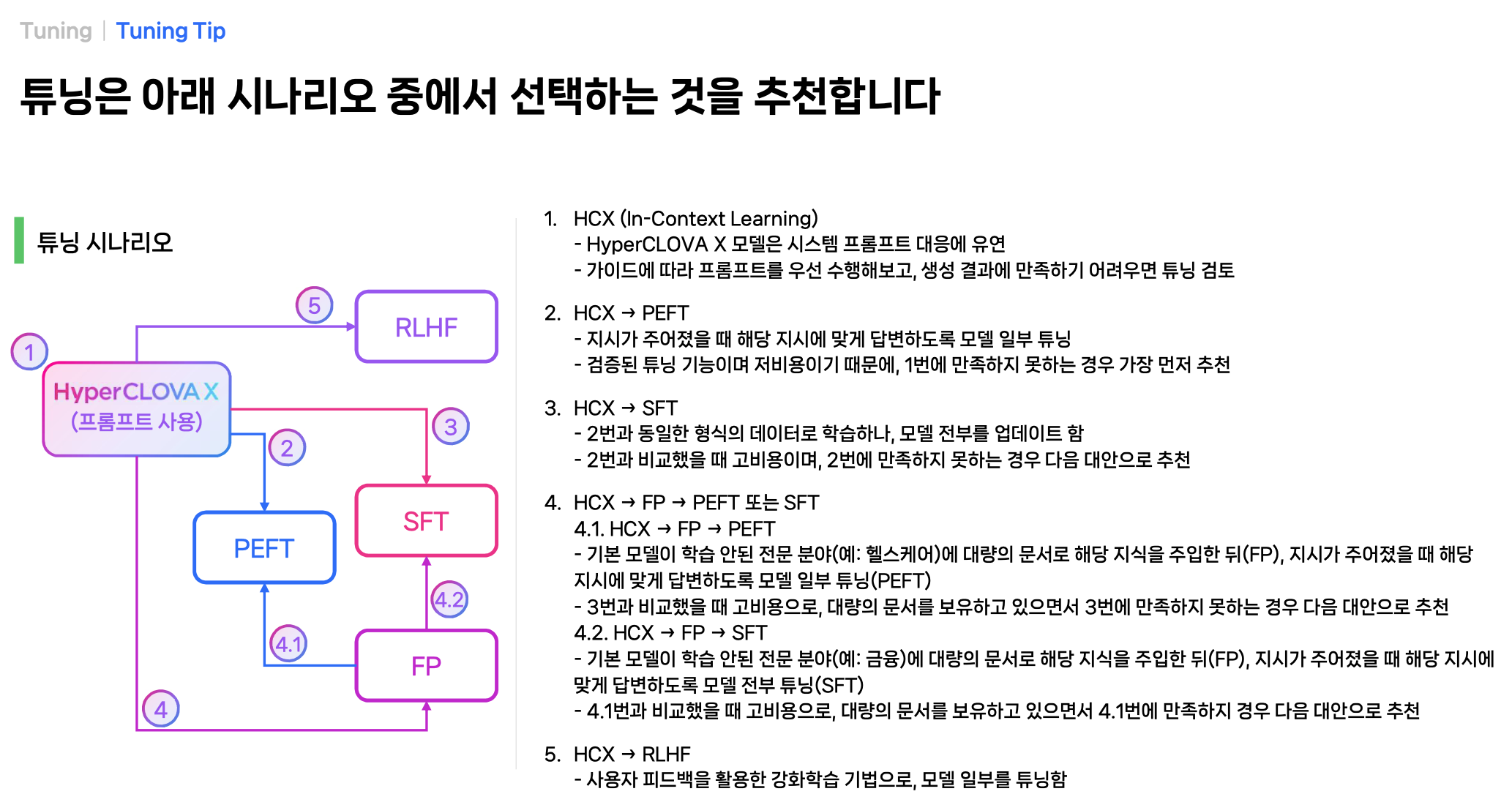
프롬프트 튜닝
언어모델에게 원하는 출력 스타일을 연습 시키는 것
PT를 예시로 들어주셨는데. 좋은 자세(답)가 나오려면 자주 훈련(튜닝)을 해줘야 한다는 것이였다. (그리고 자주 해주지 않으면 다시 돌아간다.) (Coaching = Tuning)
PEFT (Parameter-Efficient Fine Tuning)
PEFT(Parameter-Efficient Fine Tuning)는 기본 모델의 능력치를 유지하면서, 모델의 답변(문체, 표현 등 스타일)을 일부 조정할 수 있는 효율적인 학습 기법
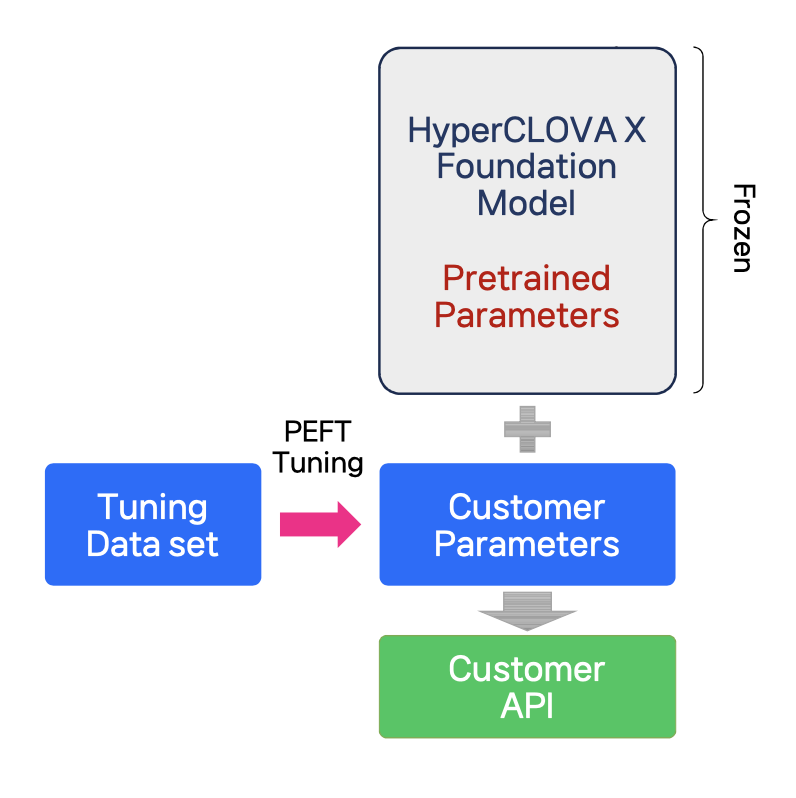
- low-rank matrices만을 최적화함으로써 학습을 효과적으로 할 수 있고, 학습용 하드웨어 리소스도 적게 사용함
- PEFT 학습데이터는 질문답변(Q&A) 형식
SFT(Supervised Fine Tuning) / FP(Further Pretraining)
SFT(Supervised Fine Tuning)는 모델을 원하는 대로 자유롭게 조정할 수 있는 학습 기법이고 FP(Further Pretraining)는 모델에 지식을 주입하여, 성능을 향상시키는 기법
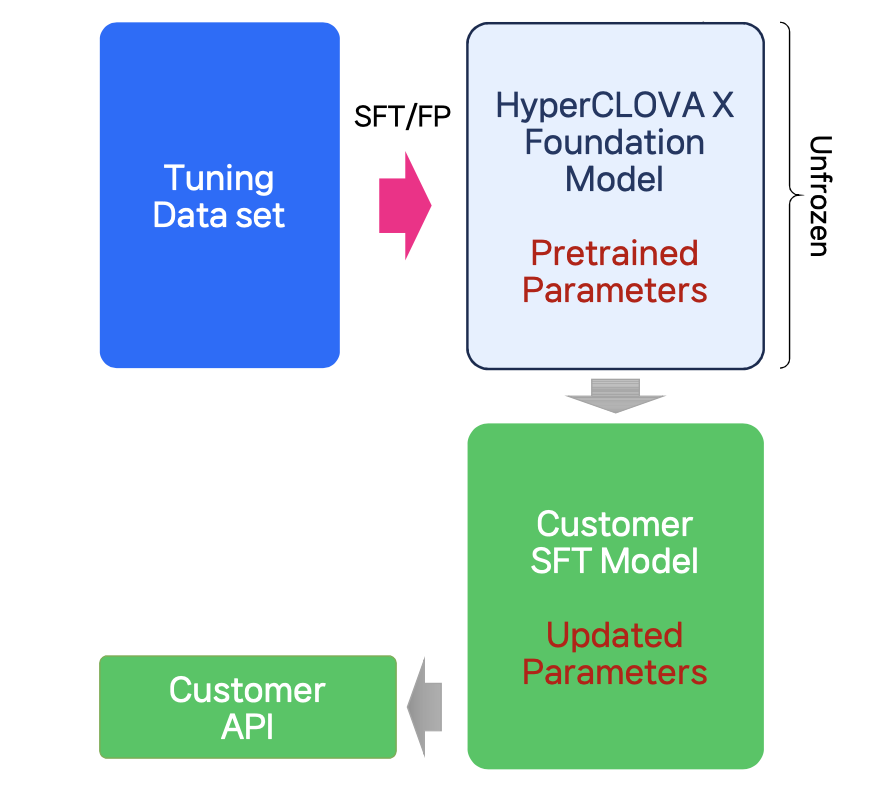
- 기본 모델 전체가 업데이트되므로 PEFT보다 많은 학습시간 및 하드웨어 리소스가 필요함
- SFT 학습데이터는 질문답변(Q&A) 형식
- FP 학습데이터는 지식(예: 교과서, 전문서적 등) 자체를 의미하며 텍스트 형식
RLHF(Reinforcement Learning from Human Feedback)
RLHF(Reinforcement Learning from Human Feedback)는 모델이 답변하지 않아야 하는 내용, 답변해야 하는 내용에 대한 정책을 반영하는 학습 기법
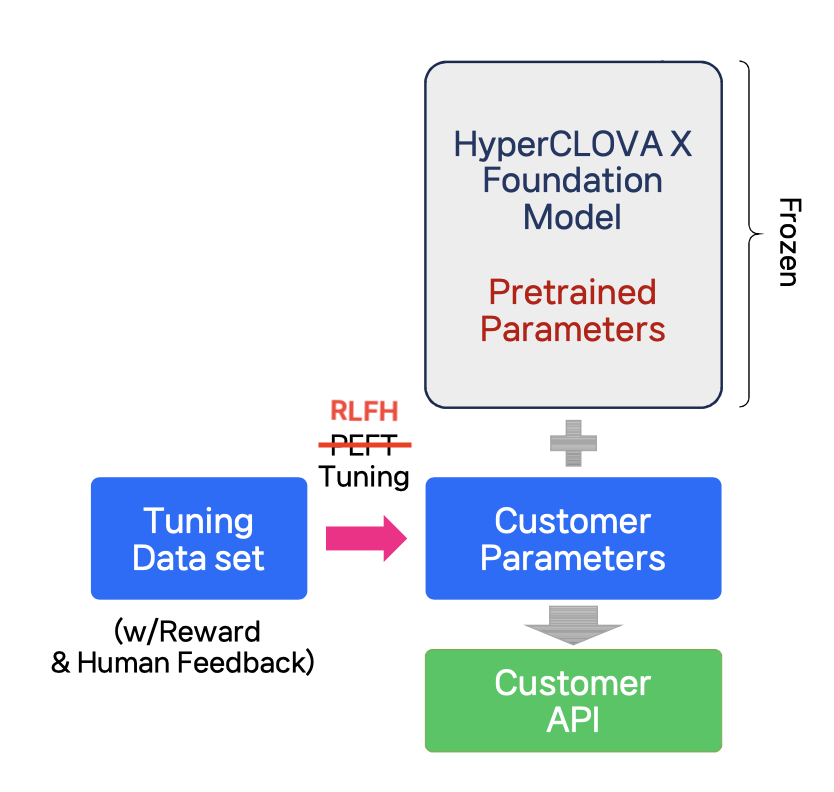
- ‘올바른 답변 만들기’라는 매우 복합적인 작업을 단순한 피드백를 통해 해결
* 자료 이미지에는 PEFT 라고 적혀있었는데 문맥상 RLHF가 맞을 것 같아 수정하였다.
튜닝 방법 (싱글턴 / 멀티턴)
턴(turn) : 대화의 참여자가 말을 주고받는 각각의 순간을 의미
- 싱글턴 튜닝 : 각 대화의 턴을 독립적으로 처리하는 방식, 빠름, 단순 정보 제공이나, 명확한 답변에 좋음.
- 멀티턴 튜닝 : 대화의 여러 턴을 연결하여 문맥을 유지하고 이해하는 방식, 코스트 큼, 복잡한 질문에 좋음.
- 하나의 대화 주제에 3개 이상의 턴을 구성하는 것을 권고
튜닝 방법간 차이 정리
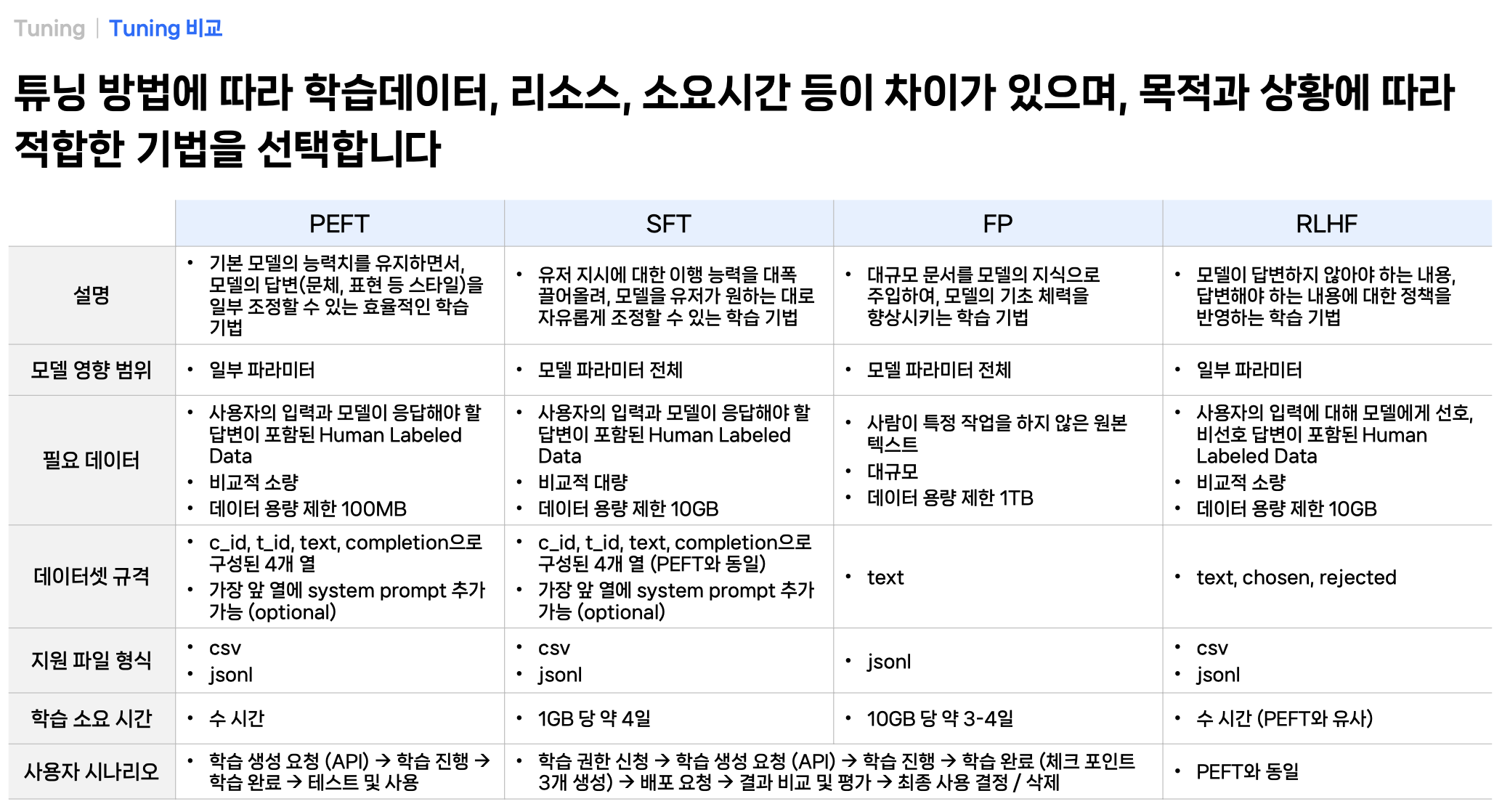
튜닝 시나리오 (상황에 따른 튜닝 방식 선택하기)
RAG
언어모델이 학습하지 않는 내용을 알려주고, 그 내용 기반으로 답변 하는 것 (서류 보관함에 비유해주셨다.)
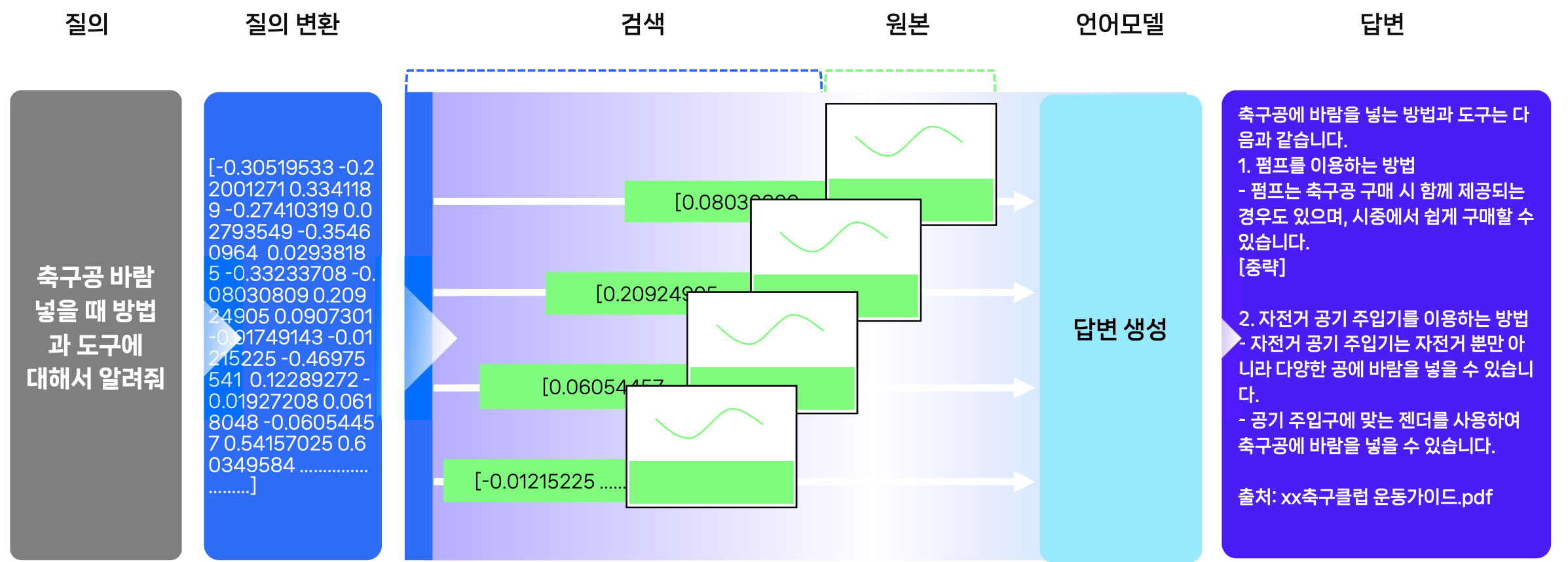
사용자의 질의에 대해 최신 정보 기반의 답변 생성을 위해 RAG(검색증강생성)를 활용한다.
RAG Tip
답변생성을 위해 LLM에 제공되는 Chunk의 품질은 매우 중요하다. 품질 높은 Chunk를 찾기 위해 Pre-retrieval, Post-Retrieval 과정을 추가한다
- 질의를 분석하고, 그 결과를 검색한다.
- Query Decomposition(질의 분해)
- Query Rewriting(질의 재작성)
- Query Expansion(질의 확장)
- 검색 결과를 줄인다.
- Mete DB 구축
- Re-rank : 검색된 결과를 질의 연관성을 다시 산출
- 키워드 검색결과와 임베딩 검색결과를 비교
- 프롬프트를 구조화 한다
- 지시문을 다음 3개 문장으로 구성하여 답변 성능을 향상시킴
- LLM에게 다음 구절을 참조하여 질문에 답하도록 요청
- 질문을 주의 깊게 읽고 이해해야 한다는 점을 강조
- 질문에 답하고 왜 이 답을 선택했는지 설명 요청
- 지시문을 다음 3개 문장으로 구성하여 답변 성능을 향상시킴
관련 용어 정리
행사에 직접적으로 나온 용어는 아니지만, LLM 관련해서 많이 보이는 것 같아서 찾아보았다.
- 멀티모달 모델 : 이미지, 동영상, 텍스트 등 여러 형식의 정보를 처리할 수 있는 모델
발표자료에 예시로 나온 Vector DB
- PostgreSQL
- Milvus
- opensearch
- drant
마무리
행사에서 들었던 세션 내용을 정리 해보았다.
AI와 LLM은 정말 빠른 발전속도를 보여주고 있어서 기대되면서도 한편으로는 무섭기도 한 것 같다.
질의 응답 시간에서는 환영(할루시네이션) 관련 이야기가 많이 나왔던 것으로 기억되는데 이 부분은 계속 해결해 나가야 할 숙제인 것을 보인다.