운영체제 10장 - 가상 메모리 (2) - 요구 페이징, copy-on-write
에서 이어지는 글입니다.
가상 메모리
10.2 요구 페이징
10.2.1 요구 페이징 기본개념 은 이전글에서 다름.
10.2.2 가용 프레임 리스트
대부분의 운영체제는 가용 프레임 풀인 가용 프레임 리스트를 유지한다.
일반적으로 zero-fill-on-demand 라는 기법을 사용하여 가용 프레임을 할당한다. zero-fill-on-demand 프레임은 할당되기 전에 0으로 모두 채워 (zero-fill) 이전 내용을 지우는 방식이다. 이전 내용이 지워지지 않을 경우 잠재적인 보안 취약점이 될 수도 있기 때문이다.
시스템이 시작되면 모든 가용 메모리가 가용 프레임 리스트에 넣어진다. 가용 프레임이 요청되면 가용 프레임 리스트의 크기가 줄어든다. 리스트의 크기가 특정 값 이하로 떨어지면 이 시점에서 다시 채워져야 한다. 10.4절에서 이 상황을 해결하기 위한 전략을 다룬다.
10.2.3 요구 페이징의 성능
요구 페이징은 컴퓨터 시스템의 성능에 큰 영향을 줄 수 있다.
이를 확인해 보기 위해 실질 접근 시간 을 계산해보면 다음과 같다.
메모리 접근 시간(ma, memory access time)을 10 ns 라고 가정하자.
가상 면접 사례로 배우는 대규모 시스템 설계 기초 책의 시스템 규모 추정하기 책에서는 주 메모리 참조에 걸리는 시간을 100ns로 잡고있다.
페이지 폴트가 없다면 실질 접근 시간은 메모리 접근 시간과 같다. 그러나 페이지 폴트가 발생하면 먼저 보조저장장치에서 해당 페이지를 읽은 다음 원하는 워드에 접근해야 한다.
워드 : 2바이트(16비트), 4바이트(32비트), 또는 8바이트(64비트)
페이지 폴트의 확률이 p 라고 하자(0 <= p < 1)
p는 0에 매우 가깝다고 가정한다. (다시말해 페이지 폴트가 많이 발생하지 않을 것으로 기대한다.)
이때 실질 접근 시간은 다음과 같다.
실질 접근 시간 = (1 - p) x ma + p x 페이지 폴트 시간
그러면 페이지 폴트를 처리하는 데 얼마나 많은 시간이 걸릴까?
페이지 폴트는 다음과 같은 순서로 처리된다.
- 운영체제에 트랩을 요청한다.
- 레지스터들과 프로세스 상태를 저장한다.
- 인터럽트 원인이 페이지 폴트임을 알아낸다.
- 페이지 참조가 유효한 것인지 확인하고, 보조저장장치에 있는 페이지의 위치를 알아낸다.
- 저장장치에 가용 프레임으로의 읽기 요구를 낸다.
5.1. 읽기 차례가 돌아올때까지 대기 큐에서 기다린다.
5.2. 디스크에서 찾는(seek) 시간과 회전 지연 시간 동안 기다린다.
5.3. 가용 프레임으로 페이지 전송을 시작한다. - 기다리는 동안 CPU 코어는 다른 사용자에게 할당한다.
- 저장장치가 다 읽었다고 인터럽트를 건다(I/O 완료)
- 다른 프로세스의 레지스터들과 프로세스 상태를 저장한다(6단계가 실행되었을 경우)
- 인터럽트가 보조저장장치로부터 왔다는 것을 알아낸다.
- 새 페이지가 메모리로 올라왔다는 것을 페이지 테이블과 다른 테이블들에 기록한다.
- CPU 코어가 자기 차례로 오기까지 다시 기다린다.
- CPU 차례가 오면 위에서 저장시켜 두었던 레지스터들, 프로세스 상태, 새로운 페이지 테이블을 복원시키고 인터럽트 되었던 명령어를 다시 실행한다.
어떤 경우에도, 페이지 폴트 처리 시간은 다음 3개의 주요 작업 요소로 이루어져 있다.
- 인터럽트의 처리
- 페이지 읽기
- 프로세스 재시작
1, 3번 작업은 100마이크로초 내로 처리가 가능하다.
페이징 장치로 HDD가 사용되는 경우, 페이지 읽는 시간은 약 8밀리초 가까이 걸릴 것이다. (대부분의 하드 디스크는 3밀리초의 지연시간과 5밀리초의 탐색 시간(seek time) 및 0.05밀리초의 전송 시간을 필요로 한다.) 이 계산은 장치 처리 시간(device service time)만 고려한 것이고, 해당 디스크에 대해 대기하고 있는 프로세스들이 존재하면 요청을 처리할 수 있을 때까지 기다리는 시간도 추가되어 처리 시간은 더 늘어난다.
평균 페이지 폴트 처리 시간을 8초로, 메모리 접근 시간을 100나노초로 잡는다면, 실질 접근 시간은 다음과 같다.
실질 접근 시간 = (1-p) x (200ns) + p (8ms)
= (1-p) x (200ns) + p (8,000,000)
= 200 + 7,999,800 x p
실제 접근 시간은 페이지 폴트율(page fault rate)에 비례한다.
만약 1000번 중 한 번의 접근에 페이지 폴트가 발생한다면, 실제 접근 시간은 8.2마이크로초이다. 요구 페이징으로 인해 40배나 느려지는 것이다.
만약 성능 저하를 10% 이내로 유지하겠다면 다음 조건을 만족해야 한다.
220 > 200 + 7,999,800 x p
20 > 7,999,800 x p
p < 0.0000025
399,990번 중에서 1번 이하의 페이지 폴트가 발생해야 한다. 따라서 페이지 폴트율을 낮게 유지하는 것이 상당히 중요하다.
참고로 SSD의 경우에는
average latency : 20 ms 이하
seek time : 0.08 ~ 0.16 ms
요구페이징을 처리하기 위해 스왑 공간을 사용합니다. 스왑 공간에서의 디스크 I/O는 일반적으로 파일 시스템에서의 입출력보다 빠르다. 그 이유는 스왑 공간은 파일 시스템보다 더 큰 블록을 사용하기 때문이고, 또 스왑 공간과 입출력을 할 때는 파일 찾기(lookup)나 간접 할당 방법 등은 사용하지 않기 때문이다 (11장)
모바일 운영체제에서는 일반적으로 스와핑을 지원하지 않는다. 모바일 시스템에서는 일반적으로 스와핑의 대안으로 압축 메모리를 사용한다 (10.7절)
익명 메모리(Anonymous memory, Anonymous page)
파일 시스템과 관련없는 메모리 페이지, 프로세스의 스택과 힙이 여기에 해당됨. 익명 메모리가 아닌 파일과 관련된 부분은 수정 없이 그대로 덮어씌울 수 있지만, 익명 메모리 부분은 그럴 수 없음.
10.3 쓰기 시 복사
10.2절에서 첫 명령어가 포함된 페이지를 요구 페이징 함으로써 프로세스를 빠르게 시작시킬 수 있음을 설명하였다.
fork() 는 부모 프로세스와 똑같은 자식 프로세스를 만들어 준다. 하지만 대부분의 자식은 이렇게 만들어지자마자 곧 exec() 시스템 콜을 한다. 그러면 부모로부터 복사해온 페이지들은 다 쓸모없어지고 만다. 그래서 부모의 페이지들을 다 복사해오는 대신 쓰기 시 복사 (copy-on-write) 방식을 사용할 수 있다.
이 방식에서는 자식 프로세스가 시작할 때 부모 페이지를 당분간 함께 사용하도록 한다. 이때 공유되는 페이지를 쓰기 시 복사 페이지라고 표시한다. 둘 중 한 프로세스가 공유 중인 페이지를 수정한다면 때 그 페이지의 복사본이 만든다.
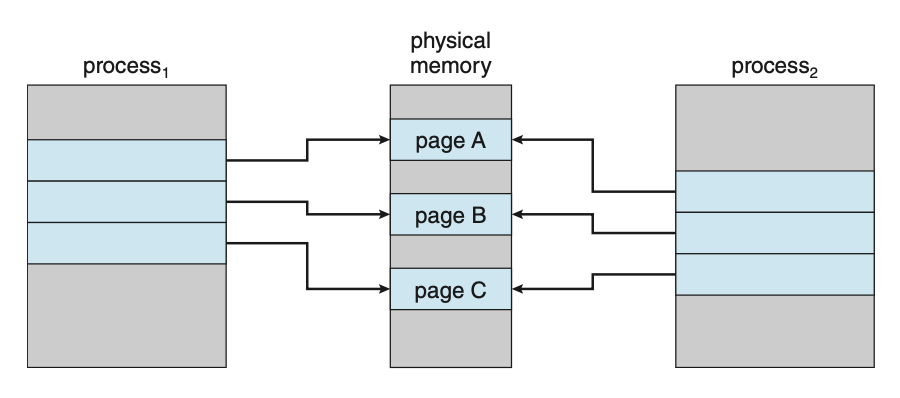
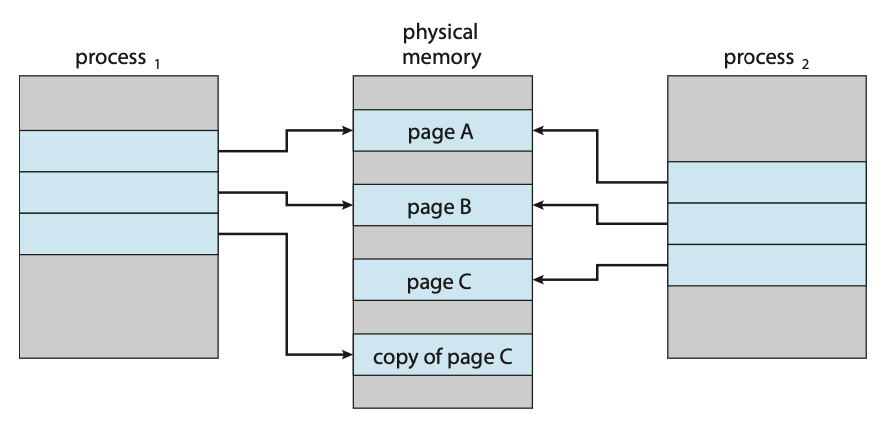
수정된 페이지(page C)에 대해서만 복사본(copy of page C)이 생기게 되며 수정되지 않은 페이지들(page A, page B)은 자식과 부모 사이에 계속 공유될 수 있다.
vfork 를 사용하면 한 곳에서 수정하더라도 계속 같은 페이지를 바라보게 할 수 있음.