운영체제 9장 - 메인 메모리 (2) - 페이징, paging
에서 이어지는 글입니다.
메인 메모리
9.2 연속적 메모리 할당
메모리는 일반적으로 두 개의 부분으로 나누어진다.
하나는 운영체제를 위한 것이며 다른 하나는 사용자 프로세스를 위한 것이다.
일반적으로 여러 사용자 프로세스가 동시에 메모리에 상주하기를 원한다. 연속적 메모리 할당(contiguous memory allocation)에서 각 프로세스는 다음 프로세스가 로드된 영역과 인접한 하나의 메모리 영역에 로드된다.
많은 운영체제에서 운영체제를 높은 메모리에 배치합니다. 이 배치가 가지는 의미는 이후 내용들에서 알아볼 수 있습니다.
9.2.1 메모리 보호
relocation 레지스터는 가장 작은 물리 주소의 값을 저장하고, limit 레지스터는 논리 주소의 범위 값을 저장한다. 각각의 논리주소는 limit 레지스터가 지정한 범위 안에 존재해야 한다. MMU는 동적으로 논리 주소에 재배치 레지스터의 값을 더함으로써 주소를 변환하는 역할을 한다.
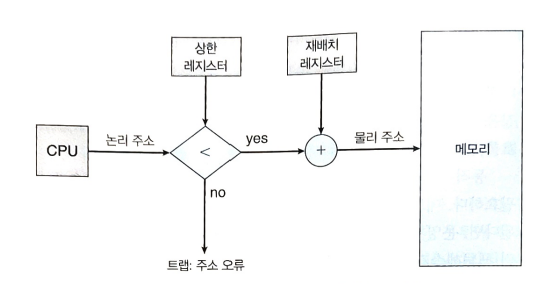
CPU 스케줄러가 다음으로 수행할 프로세스를 선택할 때, 디스패처는 컨텍스트 스위치의 일환으로 relocation 레지스터와 limit 레지스터에 정확한 값을 로드한다. 모든 주소는 이 레지스터들의 값을 참조해서 확인 작업을 거치기 때문에, 현재 수행 중인 사용자 프로그램을 보호할 수 있다.
relocation 레지스터 체계는 운영 체제의 크기가 동적으로 변경될 수 있도록 합니다. 이는 다양한 상황에서 의미가 있습니다. 예를들면 운영체제에는 장치 드라이버를 위한 코드 공간 및 버퍼 공간이 있습니다. 현재 사용중이 아닌 장치 드라이버를 메모리에 계속 유지하는 것은 의미가 없으므로 필요할 때만 메모리에 적재합니다. 마찬가지로 장치 드라이버가 더 이상 필요하지 않은 경우 장치 드라이버를 제거하고 메모리를 다른 요청에 할당할 수 있습니다.
9.2.2 메모리 할당
메모리를 할당하는 가장 간단한 방법 중 하나는 프로세스를 메모리의 가변 크기 파티션에 할당하는 것이다. 각 파티션에는 정확히 하나의 프로세스만 적재될 수 있다. 이 가변 파티션 기법에서 운영체제는 사용 가능한 메모리 부분과 사용 중인 부분을 나타내는 테이블을 유지한다. 사용 가능한 메모리 부분은 hole(구멍) 이다. 결국에는 다양한 크기의 hole이 생기게 된다.
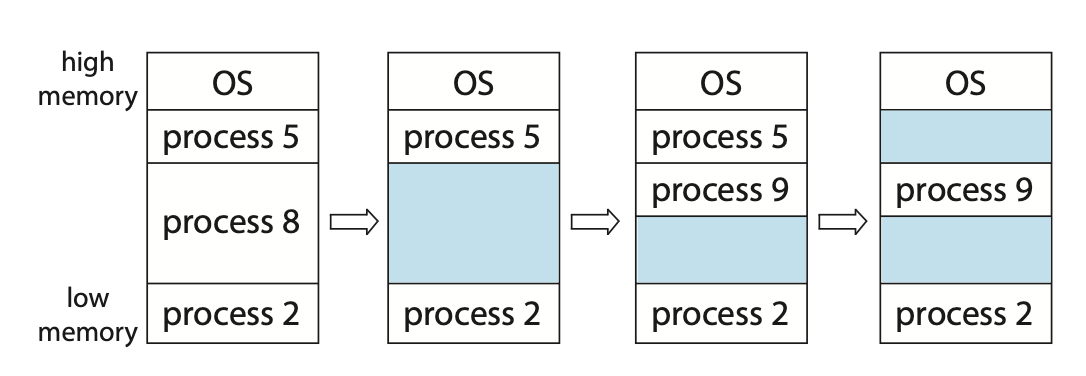
프로세스가 시스템에 들어오면, 운영체제는 각 프로세스가 메모리를 얼마나 요구하며, 또 사용 가능한 메모리 공간이 어디에 얼마나 있는지를 고려하여 공간을 할당한다. 프로세스가 종료되면 메모리를 반납한다.
메모리가 충분하지 않으면 어떻게 되는가?
- 프로세스를 거부하고 적절한 오류 메시지를 제공한다.
- 대기 큐에 넣고 메모리가 해제될때마다 대기 큐를 검사한다.
hole 의 산재 문제
- 필요한 것보다 큰 hole 일 경우 hole을 두 개로 나누어 한 조각은 프로세스에 할당한다.
- 인접한 두 개의 hole을 합쳐서 하나의 hole로 만든다.
동적 메모리 할당 문제(dynamic storage allocation problem)
- 최초 적합(first-fit)
- 첫 번째 사용 가능한 가용 공간을 할당한다.
- 검색은 시작에서부터 하거나 지난번 검색이 끝났던 곳에서 시작할 수 있다.
- 충분히 큰 가용 공간을 찾았을 때 검색을 끝낼 수 있다.
- 최적 적합(best-fit)
- 사용 가능한 공간 중에서 가장 작은 것을 택한다.
- 리스트가 크기순으로 되어있으면 유리하다.
- 최악 적합(worst-fit)
- 가장 큰 가용 공간을 택한다.
- 리스트가 크기순으로 되어있으면 유리하다.
모의 실험 결과 최초 적합과 최적 적합이 시간과 메모리 이용 효율 측면에서 최악 적합보다는 좋다는 것이 입증되었다. 최초 적합와 최적 적합은 어느 것이 항상 더 좋다고 말할수는 없지만, 최초 적합이 일반적으로 속도가 더 빠르다.
9.2.3 단편화
최초 적합 전략과 최적 적합 전략 모두 외부 단편화(external fragmentation) 이 발생한다. 프로세스들이 메모리에 적재되고 제거되는 일이 반복되다 보면, 어떤 가용 공간은 너무 작은 조각이 되어 버린다. 외부 단편화는 이처럼 유휴 공간들을 모두 합치면 충분한 공간이 되지만 그것들이 너무 작은 조각들로 여러 곳에 분산되어 있을 때 발생한다.
내부 단편화(internal fragmentation)도 발생할 수 있다. 18484B 크기의 가용 공간이 있을 때 프로세스에서는 18482B 를 요구한다고 해보자. 그러면 2B 만큼의 가용 공간이 남는다. 일반적으로는 메모리를 먼저 아주 작은 공간들로 분할하고 프로세스가 요청하면 이 분할된 크기의 정수배로 할당을 해주게 된다. 이 때 남는 부분이 바로 내부 단편화이다.
외부 단편화를 해결하는 방법 중 하나는 압축(compaction)이다. 메모리의 모든 내용을 한군데로 몰고 모든 가용 공간을 다른 한군데로 몰아서 큰 블록을 만드는 것이다. 그러나 압축이 항상 가능한 것은 아니다. relocation이 어샘블 또는 로드 시에 정적으로 진행된다면 압축을 실행될 수 없다. 압축은 프로세스들의 재배치가 실행 시간에 동적으로 이루어지는 경우에만 가능하다. 동적으로 재배치 가능한 프로세스라면 새로운 위치로 옮기고 base 레지스터만 변경하면 완료된다. 비용이 많이 드는 편이다.
다른 방법은 한 프로세스의 논리 주소 공간을 여러 개의 비연속적인 공간으로 나누어 필요한 크기의 공간이 가용해지는 경우 물리 메모리를 프로세스에 할당하는 방법이다. 이는 페이징 에서 사용되는 전략이다.
단편화는 데이터 블록들을 다루는 한 언제든지 일어나는 일반적인 문제이다.
외부 단편화 : 메모리의 여유 공간이 작은 조각들로 나뉘어져서 발생하는 현상 내부 단편화 : 할당된 메모리 영역 중에서 사용되지 않는 부분이 발생하는 현상
9.3 페이징
페이징은 물리 주소 공간이 연속되지 않아도 되는 메모리 관리 기법이다. 페이징은 외부 단편화와 압축의 필요성을 피한다.
9.3.1 기본 방법
물리 메모리를 프레임(frame)이라 불리는 같은 크기의 블록으로 나눈다. 논리 메모리는 페이지(page)라 불리는 같은 크기의 블록으로 나눈다. 프로세스가 실행될 때 프로세스의 페이지는 파일 시스템 또는 예비 저장장치로부터 사용 가능한 메인 메모리 프레임으로 로드된다. 이러한 방식을 통해 물리 메모리의 크기가 2^64 바이트보다 적게 장착된 시스템에서도 프로세스는 64비트로 이루어진 논리 주소 공간을 사용할 수 있다.
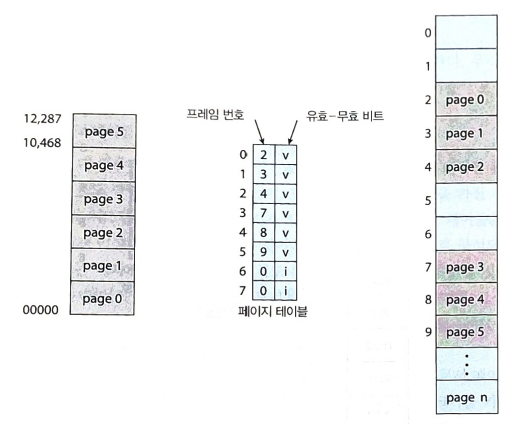
CPU 에서 나오는 모든 주소는 페이지 번호(p)와 페이지 오프셋(d: offset) 두 개의 부분으로 나누어진다.
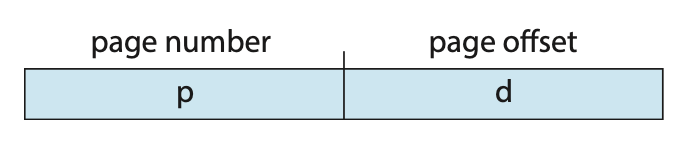
페이지 번호는 프로세스 페이지 테이블을 액세스 할 때 사용된다.
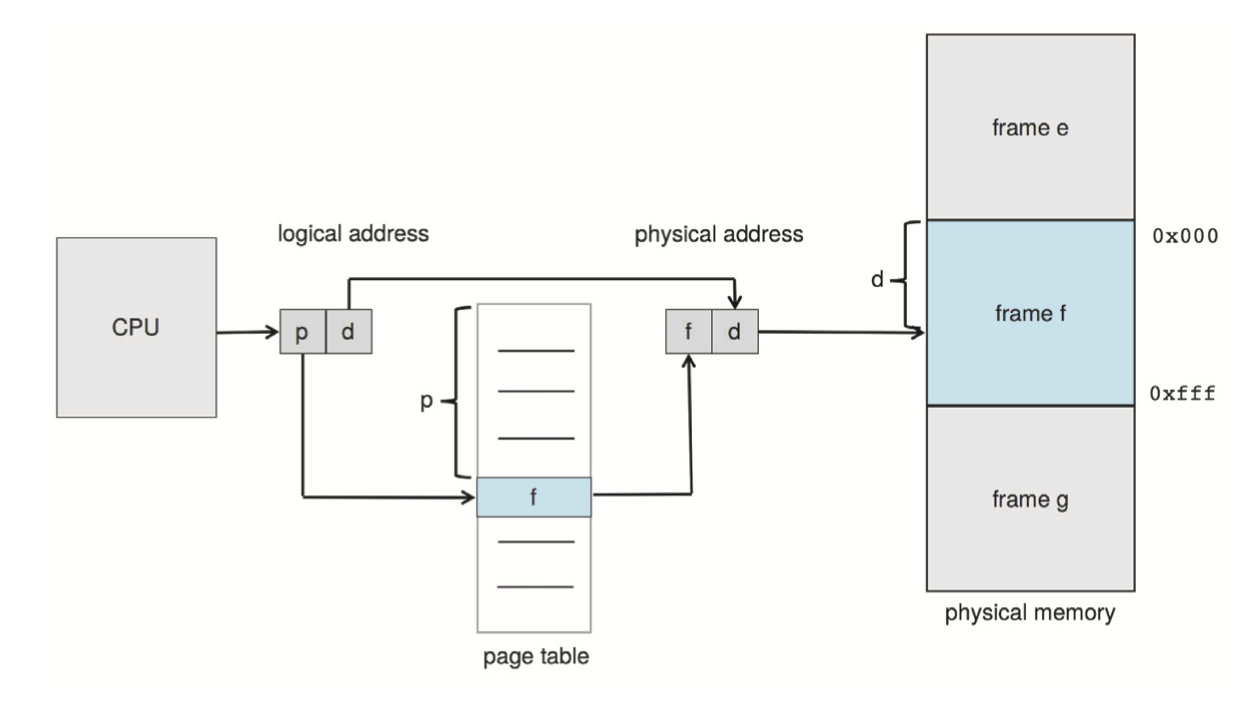
CPU에 의해 생성된 논리 주소를 물리 주소로 변환하기 위해 MMU는 다음의 단계를 거친다.
- 페이지 번호 p를 추출하여 페이지 테이블의 인덱스로 사용한다.
- 페이지 테이블에서 해당 프레임 번호 f를 추출한다.
- 논리 주소의 페이지 번호 p를 프레임 번호 f로 바꾼다. 이때 오프셋은 변하지 않으므로 대체되지 않는다.
페이징 자체는 일종의 동적 재배치이다. 모든 논리 주소는 페이징 하드웨어에 의해 실제 주소로 바인딩 된다. 페이징을 사용하는 것은 각 메모리 프레임마다 하나씩 base 레지스터를 테이블로 유지하는 것과 유사하다.
페이징 기법을 사용하면 외부 단편화가 발생하지 않는다. 모든 놀고 있는 프레임이 프로세스에 할당될 수 있기 때문이다. 그러나 이제는 내부 단편화가 발생한다.
페이지 크기가 크면 내부 단편화가 더 잘 발생되지만 그렇다고 페이지 크기가 작아지면 그에 반비례하여 페이지 테이블의 크기가 커지게 된다. 일반적인 추세는 4 KB 이다.
프로세스가 실행되기 위해 도착하면 프로세스의 크기가 페이지 몇 개에 해당하는가를 확인한다. 각 페이지는 한 프레임씩 필요하다. 프로세스의 페이지들이 할당된 프레임에 하나씩 로드되고, 로드 될 때마다 프레임 번호를 페이지 테이블에 기록된다.
페이징을 통해서 프로그래머는 마치 하나의 연속된 공간을 사용하는 것과 같이 사용할 수 있게 되었다. 실제로는 주소 변환 하드웨어를 통해 논리 주소가 물리 주소로 변환된다. 이 변환과정은 프로그래머에게는 보이지 않으며 따라서 사용자 프로세스는 자기의 것이 아닌 메모리에 접근할 수 없다.
운영체제는 물리 메모리를 관리하기 때문에 물리 메모리의 자세한 할당에 대해서 파악하고 있어야 한다. 프레임 테이블(frame table)을 통해 어느 프레임이 할당되어 있고, 어느 프레임이 사용 가능하고 총 프레임은 몇 개나 되는지 등의 정보를 확인할 수 있다. 프레임 테이블은 각 프레임당 하나의 row를 가진다.
운영체제는 모든 프로세스의 주소들을 실제 주소로 변환할 수 있어야 한다. 만약 사용자가 system call을 호출하여 인자로 어떤 주소를 주면 제대로 변환하여 정확히 그 물리 주소를 찾아가야 한다. 페이징은 context switching 시간을 늘린다.
9.3.2 하드웨어 지원
페이지 테이블은 프로세스별 자료구조이므로 페이지 테이블에 대한 포인터는 각 프로세스의 프로세스 제어 블록에 다른 레지스터 값과 함께 저장된다. CPU 스케줄러가 실행할 프로세스를 선택하면 사용자 레지스터와 적절한 페이지 테이블 값을 로드합니다. 대부분의 컴퓨터는 페이지 테이블을 메인 메모리에 저장하고 page table base register 로 하여금 페이지 테이블을 가리키도록 합니다. 다른 페이지 테이블을 사용하려면 이 레지스터만 변경하면 되기 때문에 context switching 시간을 줄일 수 있습니다.
9.3.2.1 Translation Lock-Aside Buffer
메인 메모리에 페이지 테이블을 저장해서 context switching 시간은 줄였지만, 메모리 액세스를 하는데 시간이 소요된다.
총 2번의 메인 메모리 액세스를 하게 되는데 다음과 같다.
- 페이지 번호를 기준으로 PTBR(page table base register)의 오프셋 값을 이용하여 페이지 테이블의 항목을 찾는다. (페이지 테이블이 메인 메모리에 있기 때문에)
- 실제 주소에 접근한다.
이 문제를 해결하기 위해서 TLB (translation look-aside buffers)라고 불리는 하드웨어 캐시가 사용된다. TLB 는 키와 값의 두 부분으로 구성된다. 페이지를 찾는 요청이 들어오면 TLB를 먼저 거치고 발견되면 그에 대응하는 프레임 번호를 알려준다. TLB에 없으면(TLB 미스라고 함) 기존과 같은 단계로 진행된다. 결과를 TLB 추가하여 다음 참조에서 빠르게 찾을 수 있도록 한다.
시스템에서 ASID(address-space identifier) 를 지원하면 그 TLB 항목이 어느 프로세스에 속한것인지를 알 수 있다. ASID 지원이 없으면 새로운 페이지 테이블이 선택될 때마다 TLB를 플러시 해야 한다.
intel 에서는 PCID(Process Context IDentifiers) 라고도 부르는 것으로 보인다.
현재의 CPU는 여러 단계의 TLB를 가지고 있다.
e.g. Intel Core i7 CPU
128개 항목의 L1 instruction TLB, 64개 항목의 L1 data TLB 이 있음.
L1에서 TLB 미스가 날 경우 512개 항목의 L2 TLB 를 검색함.
9.3.3 보호
페이징 환경에서는 각 페이지에 붙어있는 보호 비트를 통해 메모리를 보호한다.
보호 비트는 페이지에 대해 읽기/쓰기 또는 읽기 전용 임을 정의할 수 있다. 메모리에 대한 모든 접근은 페이지 테이블을 거치므로, 주소 변환과 함께 이 페이지에 쓰기가 허용되는지 안되는지와 같은 검사도 할 수 있다.
읽기 전용 페이지에 관해 쓰기를 시도하면 운영체제가 하드웨어로 트랩을 걸어준다.
페이지 테이블의 각 엔트리에는 유효/무효(valid/invalid) 비트가 있다.
이 비트가 유효로 설정되면 관련된 페이지가 프로세스의 합법적인 페이지임을 나타내며, 이 비트가 무효로 설저오디면 그 페이지는 프로세스의 논리 주소 공간에 속하지 않았다는 것을 나타낸다. 운영체제는 이 비트를 이용해서 그 페이지에 대한 접근을 허용하든지 또는 허용하지 않을 수 있다.
읽으면서, cheat engine 같은 애들은 뭐지? 라는 생각이 들었다. cheat engine 을 사용하면 다른 프로세스의 메모리 영역을 스캔하고 수정할 수 있다.
9.3.4 공유 페이지
페이징의 장점은 공통의 코드를 공유할 수 있다는 점이다.
재진입 코드(reentrant code - shared code 라고도 함)로 작성되었다면 동일한 부분을 사용하는 프로세스에서 함께 사용할 수 있다.
대표적인 예시로 표준 C 라이브러리가 있다.
공유 라이브러리의 경우 운영체제가 읽기 전용 속성을 강제해야 한다.