TabbyML 사용해보기 (private 오픈소스 코드 어시스턴트) (with arm architecture)
개요
최근에 Blog를 이동하면서 남는 서버 리소스가 생기게 되었다.
블로그용으로 사용하는 서버는 Oracle에서 제공해주는 프리티어로 생성한 서버인데
오라클에서 제공해주는 프리티어의 경우 VM을 상시 무료로 제공해주기 때문에 관심이 있는 사람은 아래 글을 참고하면 좋을 것 같다.
아무튼 이 남는 자원으로 무엇을 해볼까 고민하다가, 예전부터 private 코드 어시스턴트 API 서버를 구축하는 Tabby 라는 오픈소스 프로젝트에 관심이 갔기 때문에 한 번 설치해보기로 마음 먹었다.
동작 예시는 아래와 같다. (출처 : tabby readme) 
레포지토리 README에 보면 docker로 run 명령어 예시가 작성되어있다.
아래 명령어를 입력하면 tabby 서버가 실행된다.
docker run -it --gpus all -p 8080:8080 -v $HOME/.tabby:/data tabbyml/tabby serve --model TabbyML/SantaCoder-1B --device cuda
Oracle 상시 무료로 제공해주는 서버는 일반적으로 주로 사용되는 amd64 서버와 arm 서버, 이렇게 두 가지 종류가 있는데 arm 서버의 스펙이 더 좋기 때문에 나는 arm 서버에 tabby 서버를 실행하기로 마음을 먹은 상태였다.
arm 아키텍처를 써본 사람들은 알겠지만 arm 의 경우 docker 이미지로 지원하지 않는 경우가 많다. 그래서 arm 아키텍처에서 tabby를 사용하기 위해 직접 코드를 받아서 수동으로 빌드를 진행해야 했다. (사실 arm이 아니였다면 아래 내용들은 대부분 겪지 않아도 될 문제들이다. 그냥 docker 명령어로 실행하면 되니깐…)
README 파일을 보면 수동 빌드 하는 방법도 설명되어 있다.
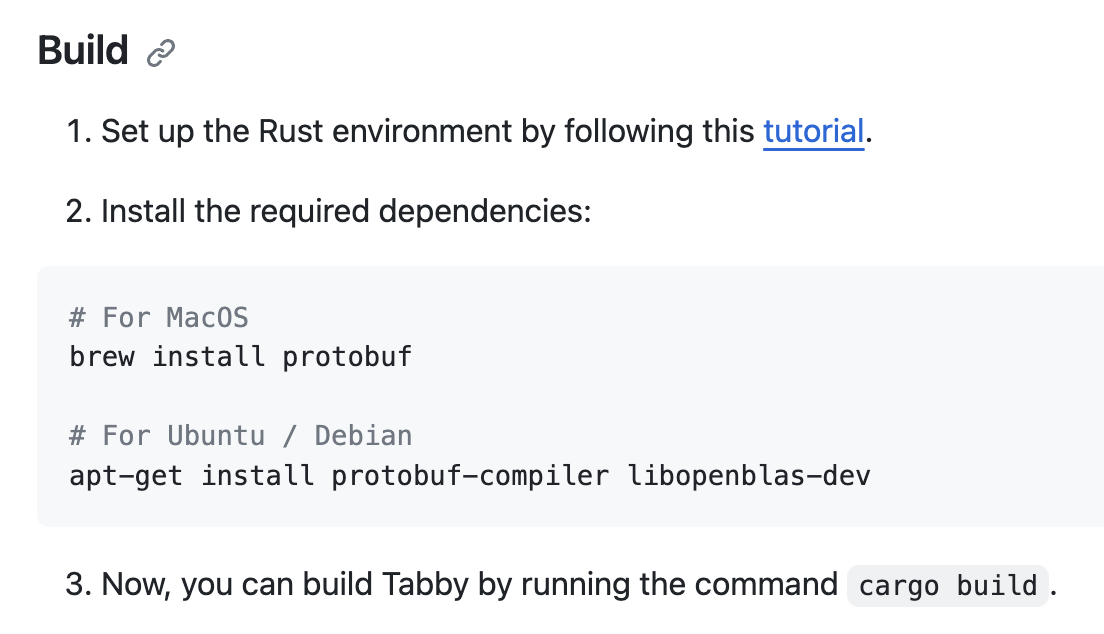
위 설명 따라서 진행을 하면 되는데 ubuntu 에 설치되는 CMake 버전의 경우 이 프로젝트를 빌드하기 위해 필요한 버전보다 낮기 때문에 package를 직접 받아서 설치해야 한다.
CMake 3.26 or higher is required. You are running version 3.22.1
실제로 빌드 과정중에 위 에러 로그를 만났고, askubuntu의 How to upgrade cmake in Ubuntu 라는 글에 달린 답변을 보고 해결하였다.
https://cmake.org/download/에서 aarch64 버전을 찾으니 Latest Release 기준으로는 3.27.7 버전이여서 해당 버전을 다운로드 하였다.
https://github.com/Kitware/CMake/releases/download/v3.27.7/cmake-3.27.7-linux-aarch64.sh
설치 스크립트를 실행한 후 안내에 따라
sudo ln -s /opt/cmake-3.27.7-linux-aarch64/bin/\* /usr/local/bin
명령어까지 실행해주면 CMake 버전 업데이트가 완료된다.
ubuntu@instance:~$ cmake --version
cmake version 3.27.7
빌드가 끝났으면 아래와 같이 명령어를 입력하여 실행할 수 있다.
cargo run serve --model TabbyML/SantaCoder-1B --device cuda
실제 실행할 때는 그래픽 카드는 없으므로 뒤에 device 옵션은 빼고 실행하였다.
정상적으로 서버가 실행되었다면 서버 외부에서 이 서비스에 접속할 수 있도록 oracle cloud에서 8080을 오픈해주고 방화벽 (iptable) 에서 아래 명령어를 통해 8080 포트를 오픈해주면 된다.
sudo iptables -I INPUT 1 -p tcp --dport 8080 -j ACCEPT
Tabby는 대부분의 주요 에디터/IDE 에서 사용할 수 있도록 플러그인을 지원한다.
- Visual Studio Code
- IntelliJ Platform
- VIM / NeoVIM
나는 Visual Studio Code 에서 확장프로그램을 설치하였다. 설치한 이후로 크게 설정할 것은 없고 tabby 서버의 api 엔드포인트만 입력해주면 된다.
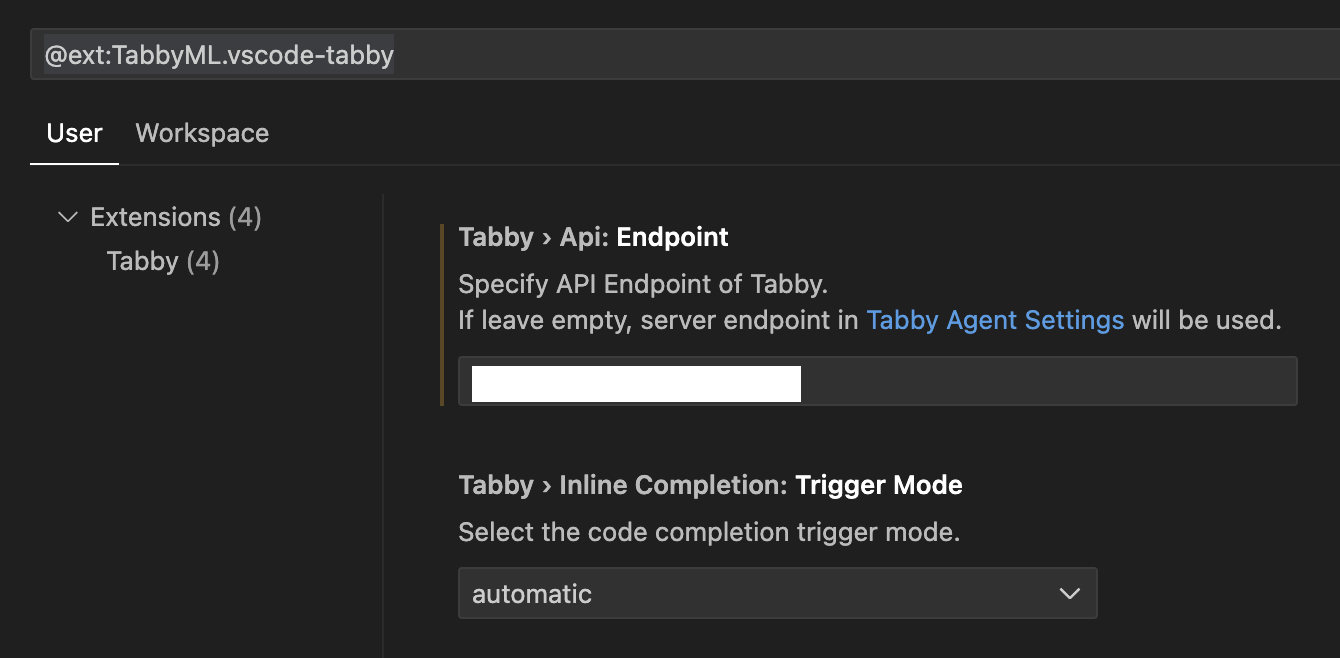
그런데 여기서 문제는 타임 아웃 에러가 계속 발생하였다.
Most completion requests timed out.
그래픽카드가 없다보니 제 시간에 응답을 못해주는 것은 아닐까 추측해보았다. 일단 모델을 더 낮은 것으로 변경해보기로 하였다.
Tabby는 여러가지 모델을 공개해두었다.
https://tabby.tabbyml.com/docs/models/
모델 사이즈별 추천 스펙도 대략적으로 정리해있으니 참고하면 좋을 것 같다.
small models (less than 400M) for CPU devices.
For 1B to 7B models, it's advisable to have at least NVIDIA T4, 10 Series, or 20 Series GPUs.
For 7B to 13B models, we recommend using NVIDIA V100, A100, 30 Series, or 40 Series GPUs.
CPU가 없다보니 나와있는 가장 작은 모델인 TabbyML/J-350M으로 변경해보았지만 CPU만으로는 감당이 되지 않는지 여전히 timeout 에러가 발생하여서 포기하였다.
그래서 개인 컴퓨터에서 실행을 해보았다.
개인 컴퓨터에서는 3070 GPU를 사용하고 있고, ARM도 아니기 때문에 Docker를 이용해서 아래 명령어와 같이 실행해주었다.
docker run -it
–gpus all -p 8080:8080
-e TABBY_DISABLE_USAGE_COLLECTION=1
-v $HOME/.tabby:/data
tabbyml/tabby
serve –model TabbyML/CodeLlama-7B –device cuda
참고로 TABBY_DISABLE_USAGE_COLLECTION=1 을 해주지 않으면 정보를 수집해간다. (https://tabby.tabbyml.com/docs/configuration 참고) 개인적인 정보는 수집해가지 않는다는것 같지만 찝찝하기 때문에 DISABLE 을 명시해주었다.
개인 컴퓨터에서 실행된 Tabby API를 통해서 VS Code 확장 프로그램을 재 설정하고 테스트를 해보았다.
아래와 같이 함수를 자동으로 완성해주는 것도 정상적으로 되는 것도 확인하였다.
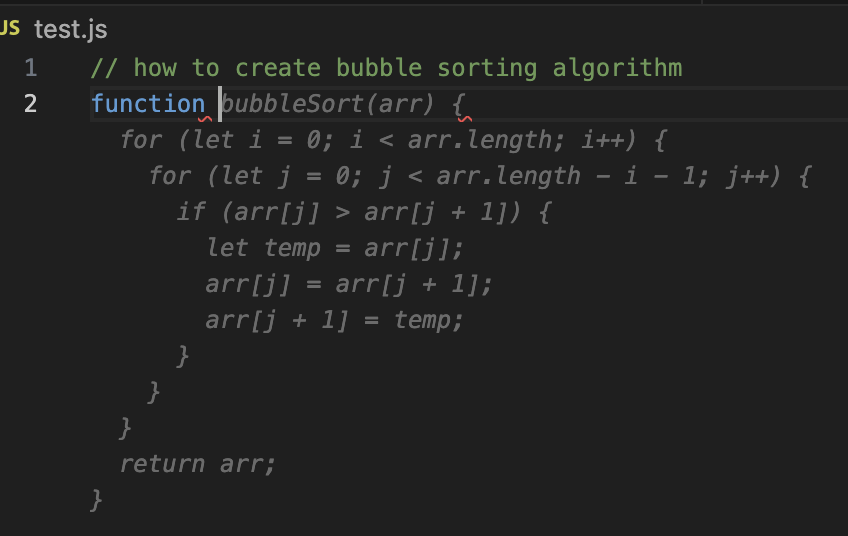
한국어 문장도 중간중간 자동완성을 해주기도 한다.
근데 생각보다 유용하지는 않은 것 같다. 내 GPU 성능이 부족해서 매우 좋은 모델은 사용하지 못한것도 있겠지만 아쉬운 점이 많았다.
자체 구축해서 사용하면 private 코드 어시스턴트라 데이터가 유출될 걱정은 덜 해도 되겠지만 결과를 보았을 때 그냥 코파일럿을 구매하거나 필요한 질문을 잘 정리해서 ChatGPT에 직접 물어보는게 편할 것 같다는 생각이 들었다.
코드 어시스턴트를 사용해 보는 경험을 한 것에 의의를 두고 만족하는걸로 마무리 지어본다