클린 아키텍처에 대하여
클린 아키텍처 - 로버트 C. 마틴 22장 클린 아키텍처
시스템 아키텍처와 관련된 여러 가지 아이디어들이 있다. 대표적으로 아래와 같은 것들이 있다.
- 육각형 아키텍처 (Hexagonal Architecture)
- DCI (Data, Context and Interaction)
- BCE (Boundary-Control-Entity)
이러한 아키텍처는 모두 세부적인 면에서는 다소 차이가 있더라도 그 내용은 상당히 비슷하다. 이러한 아키텍처들의 목표는 관심사의 분리(separation of concerns)로 같다. 계층을 분리함으로써 관심사의 분리라는 목표를 달성할 수 있었다.
각 아키텍처는 최소한 업무 규칙을 위한 계층 하나와 사용자와 시스템 인터페이스를 위한 또 다른 계층 하나를 반드시 포함한다.
이 아키텍처들은 모두 시스템이 다음과 같은 특정을 지니도록 한다.
- 프레임워크 독립성 아키텍처는 프레임워크의 존재 여부에 의존하지 않는다. 프레임워크를 하나의 도구로 사용할 뿐이며, 프레임워크가 지닌 제약사항 안으로 시스템을 욱여 넣도록 강제하지 않는다.
- 테스트 용이성 업무 규칙(business rule)은 UI, 데이터베이스, 웹 서버, 또는 여타 외부 요소가 없이도 테스트할 수 있다.
- UI 독립성 시스템의 나머지 부분을 변경하지 않고도 UI를 쉽게 변경할 수 있다. (업무 규칙이 독립되어 업무 규칙을 변경하지 않고 대상을 변경할 수 있음.(웹 → 콘솔))
- 데이터베이스 독립성 오라클이나 MSSQL 서버를 몽고DB, 빅테이블, 카우치DB 등으로 교체할 수 있다. (마찬가지로 업무 규칙이 데이터베이스에 결합되지 않아야 한다.)
- 모든 외부 에이전시에 대한 독립성 업무 규칙은 외부 세계와의 인터페이스에 대해 전혀 알지 못한다.
의존성 규칙
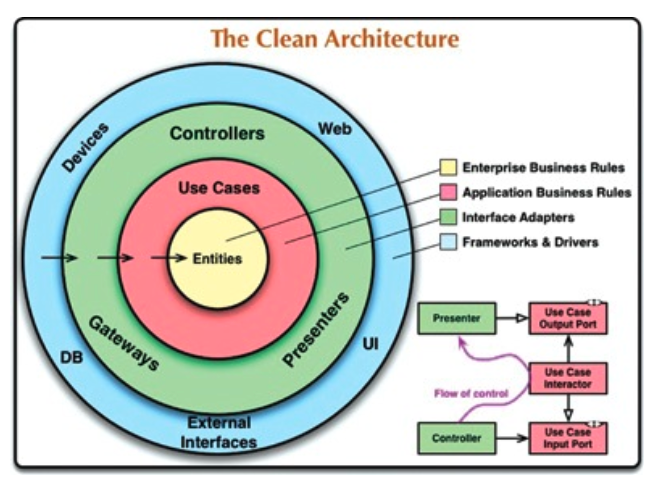
그림 에서 동심원은 소프트웨어에서 서로 다른 영역을 표현한다. 보통 안으로 들어갈수록 고수준의 소프트웨어가 된다. 바깥쪽 원은 메커니즘이고, 안쪽 원은 정책이다.
이러한 아키텍처가 동작하도록 하는 가장 중요한 규칙은 의존성 규칙(Dependency Rule) 이다.
소스 코드 의존성은 반드시 안쪽으로, 고수준의 정책을 향해야 한다.
내부의 원에 속한 요소는 외부의 원에 속한 어떤 것도 알지 못한다. 특히 내부의 원에 속한 코드는 외부의 원에 선언된 어떤 것에 대해서도 그 이름을 언급해서는 절대 안 된다. 여기에는 함수, 클래스, 변수, 그리고 소프트웨어 엔티티로 명명되는 모든 것이 포함된다.
같은 이유로, 외부의 원에 선언된 데이터 형식도 내부의 원에서 절대로 사용해서는 안 된다. 특히 그 데이터 형식이 외부의 원에 있는 프레임워크가 생성한 것이라면 더더욱 사용해서는 안 된다.
우리는 외부 원에 위치한 어떤 것도 내부의 원에 영향을 주지 않기를 바란다.
엔티티
엔티티는 전사적인(enterprise-wide) 핵심 업무 규칙을 캡슐화한다.
운영 관점에서 특정 애플리케이션에 무언가 변경이 필요하더라도 엔티티 계층에는 절대로 영향을 주어서는 안 된다.
유스케이스
유스케이스 계층의 소프트웨어는 애플리케이션에 트고하된 업무 규칙을 포함한다. 또한 유스케이스 계층의 소프트웨어는 시스템의 모든 유스케이스를 캡슐화하고 구현한다.
유스케이스는 엔티티로 들어오고 나가는 데이터 흐름을 조정하며, 엔티티가 자신의 핵심 업무 규칙을 사용해서 유스케이스의 목적을 달성하도록 이끈다.
이 계층에서 발생한 변경이 엔티티에 영향을 줘서는 안 된다. 또한 데이터베이스, UI, 또는 여타 공통 프레임워크와 같은 외부 요소에서 발생한 변경이 계층에 영향을 줘서도 안 된다. 유스케이스 계층은 이러한 관심사로부터 격리되어 있다.
하지만 운영 관점에서 애플리케이션이 변경된다면 유스케이스가 영향을 받으며, 따라서 이 계층의 소프트웨어에도 영향을 줄 것이다. 유스케이스의 세부 사항이 변하면 이 계층의 코드 일부는 분명 영향을 받을 것이다.
인터페이스 어댑터
인터페이스 어댑터(Interface Adaptor) 계층은 일련의 어댑터들로 구성된다.
어댑터는 데이터를 유스케이스와 엔티티에게 가장 편리한 형식에서 데이터베이스나 웹 같은 외부 에이전시에게 가장 편리한 형식으로 변환한다.
이 계층은 GUI의 MVC 아키텍처를 모두 포괄한다. 프레젠터, 뷰, 컨트롤러는 모두 인터페이스 어댑터 계층에 속한다. 모델은 그저 데이터 구조 정도에 지나지 않으며, 컬트롤러에서 유스케이스로 전달되고, 다시 유스케이스에서 프레젠터와 뷰로 되돌아 간다.
마찬가지로 이 계층은 데이터를 엔티티와 유스케이스에게 가장 편리한 형식엥서 영속성용으로 사용 중인 임의의 프레임워크(즉, 데이터베이스)가 이용하기에 가장 편리한 형식으로 변환한다.
이 원 안에 속한 어떤 코드도 데이터베이스에 대해 조금도 알아서는 안 된다. 예컨대 SQL 기반의 데이터베이스를 사용한다면 모든 SQL은 이 계층을 벗어나서는 안된다. 특히 이 계층에서도 데이터베이스를 담당하는 부분으로 제한되어야 한다.
또한 이 계층에는 데이터를 외부 서비스와 같은 외부적인 형식에서 유스케이스나 엔티티에서 사용되는 내부적인 형식응로 변환하는 또 다른 어댑터가 필요하다.
프레임워크와 드라이버
그림에서 가장 바깥쪽 계층은 일반적으로 데이터베이스나 웹 프레임워 같은 프레임워크나 도구들로 구성된다. 일반적으로 이 계층에서는 안쪽 원과 통신하기 위한 접합 코드 외에는 특별히 더 작성해야 할 코드가 없는 편이다.
프레임워크와 드라이버 계층은 모든 세부사항이 위치하는 곳이다. 웹은 세부사항이다. 데이터베이스는 세부사항이다. 우리는 이러한 것들을 모두 외부에 위치시켜서 피해를 최소화한다.
원은 네 개여야만 하나?
그림에 표시한 원들은 그저 개념을 설명하기 위한 하나의 예시일 뿐이다. 항상 네 개만 사용해야 한다는 규칙은 없다. 하지만 어떤 경우에도 의존성 규칙은 적용된다.
소스 코드 의존성은 항상 안쪽을 향한다. 안쪽으로 이동할수록 추상화와 정책의 수준은 높아진다. 가장 바깥쪽 원은 저수준의 구체적인 세부사항으로 구성된다. 그리고 안쪽으로 이동할수록 소프트웨어는 점점 추상화되고 더 높은 수준의 정책들을 캡슐화한다. 따라서 가장 안쪽 원은 가장 범용적이며 높은 수준을 가진다.
경계 횡단하기
컨트롤러와 프레젠터가 다음 계층에 속한 유스케이스와 통신하는 모습을 예시로 확인해보자.
제어흐름은 컨트롤러에서 시작해서, 유스케이스를 지난 후, 프레젠터에서 실행되면서 마무리된다. 각 의존성은 유스케이스를 향해 안족으로 가리킨다.
이처럼 제어흐름과 의존성의 방향이 명백히 반대여야 하는 경우, 대체로 의존성 역전 원칙을 사용하여 해결한다.
예를 들어 유스케이스에서 프레젠터를 호출해야 한다고 가정해 보자. 이 때 직접 호출해서는 안 되는데, 직접 호출해 버리면 의존성 규칙(내부의 원에서 외부 원에 있는 어떤 이름도 언급해서는 안 된다)을 위반하기 때문이다. 따라서 우리는 유스케이스가 내부 원의 인터페이스를 호출하도록 하고, 외부 원의 프레젠터가 그 인터페이스를 구현하도록 만든다.
아키텍처 경계를 횡단할 때 언제라도 동일한 기법을 사용할 수 있다. 우리는 동적 다형성을 이용하여 소스 코드 의존성을 제어흐름과는 반대로 만들수 있고, 이를 통해 제어 흐름이 어느 방향으로 흐르더라도 의존성 규칙을 준수할 수 있다.
경계를 횡단하는 데이터는 어떤 모습인가
경계를 가로지르는 데이터는 흔히 간단한 데이터 구조로 이루어져 있다. 기본적인 구조체나 간단한 데이터 전송 객체(data transfer object, dto) 등 원하는 대로 고를 수 있다.
또는 함수를 호출할 때 간단한 인자를 사용해서 데이터로 전달할 수도 있다.
그게 아니라면 데이터를 해시맵으로 묶거나 객체로 구성할 수도 있다.
중요한 점은 격리되어 있는 간단한 데이터 구조가 경계를 가로질러 전달된다는 사실이다.
꾀를 부려서 엔티티 객체나 데이터베이스의 행을 전달하는 일은 원치 않는다. 우리는 데이터 구조가 어떤 의존성을 가져 의존성 규칙을 위배하게 되는 일은 바라지 않는다.
예를 들어 많은 데이터베이스 프레임워크는 쿼리에 대한 응답으로 사용하기에 편리한 데이터 포맷을 사용한다. 이러한 포맷은 행 구조인 경우가 많다. 우리는 이 행 구조가 경계를 넘어 내부로 그대로 전달되는 것을 원치 않는다. 이렇게 되면 의존성 규칙을 위배하게 되는데, 내부의 원에서 외부의 원의 무언가를 알아야만 하기 때문이다.
따라서 경계를 가로질러 데이터를 전달할 때, 데이터는 항상 내부의 원에서 사용하기에 가장 편리한 형태를 가져야만 한다.
전형적인 시나리오
아래 이미지의 다이어그램은 웹 기반 자바 시스템의 전형적인 시나리오를 보여준다.
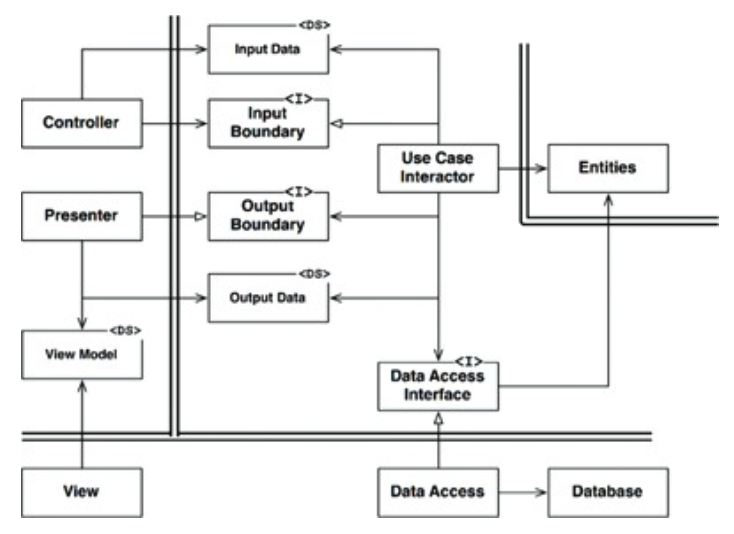
- 웹 서버는 사용자로부터 입력 데이터를 모아서 좌측 상단의 Controller로 전달한다.
- Controller는 데이터를 평범한 자바 객체(POJO)로 묶은 후, InputBoundary 인터페이스를 통해 UseCaseInteractor로 전달한다. UseCaseInteractor는 이 데이터를 해석해서 Entities가 어떻게 동작할지를 제어하는데 사용한다.
- UseCaseInteractor는 DataAccessInterface를 사용하여 Entities가 사용할 데이터를 데이터베이스에서 불러와서 메모리로 로드한다.
- Entities가 완성되면, UseCaseInteractor는 Entities로 부터 데이터를 모아서 또 다른 평범한 자바 객체인 OutputData 를 구성한다.
- 그리고 나서 OutputData는 OutputBoundary 인터페이스를 통해 Presenter로 전달된다.
번역서에는 “UseCaseInteractor는 이 데이터를 해석해서 Entities가 어떻게 춤출지를 제어하는데 사용한다.” 라는 내용이 있다. 원문으로 보면 “control the dance of the Entities” 이라고 되어 있다. 이 부분을 동작 으로 바꾸어 작성했다.
Presenter가 맡은 역할은 OutputData를 ViewModel과 같이 화면에 출력할 수 있는 형식으로 재구성하는 일이다. ViewModel 또한 평범한 자바 객체다. ViewModel은 주로 문자열과 플래그로 구성되며, View에서는 이 데이터를 화면에 출력한다.
OutputData에서는 Date 객체를 포함할 수 있는 반면, Presenter는 ViewModel을 로드할 때 Date 객체를 사용자가 보기에 적절한 형식의 문자열로 변환한다. 이 변환은 Currency 객체와 같은 곳에도 똑같이 적용된다.
ViewModel에서 HTML 페이지로 데이터를 옮기는 일을 빼면, View에서 해야 할 일은 거의 남아 있지 않다.
의존성의 방향에 주목하라. 모든 의존성은 경계선을 안쪽으로 가로지르며, 따라서 의존성 규칙을 준수한다.
결론
위의 간단한 규칙들을 준수하는 일은 어렵지 않으며, 향후에 겪을 수많은 고통거리를 덜어줄 것이다. 소프트웨어를 계층으로 분리하고 의존성 규칙을 준수한다면 본질적으로 테스트하기 쉬운 시스템을 만들게 될 것이며, 그에 따른 이점을 누릴 수 있다. 테스트베이스나 웹 프레임 워크와 같은 시스템의 외부 요소가 구식이 되더라도, 이들 요소를 야단스럽지 않게 교체할 수 있다.