6장 JDK 동시성(concurrency) 라이브러리 (1)
Well-Grounded Java Developer – 2nd edition
이번 장에서는 아래의 것들을 다룹니다.
- 아토믹(Atomic) 클래스
- 락(Lock) 클래스
- Concurrent data structures
- BlockingQueues
- Futures and CompletableFuture
- Executors
java.util.concurrent 를 어떻게 다루는지에 대해서 알아보고 이번 장을 통해 실제 코드로 적용할 준비를 갖추는 것 목표로 합니다.
6.1 최신 동시성 어플리케이션을 위한 블록 만들기
Java는 예전부터 동시성을 지원해왔습니다. 그러나 Java 5가 출시 되면서 java.util.concurrent 패키지를 통해 새로운 방식들을 지원해왔습니다.
java.util.concurrent의 주요 클래스들에 대해 소개하고 사용 사례를 살펴보겠습니다.
6.2 아토믹 클래스
java.util.concurrent 패키지에서 Atomic으로 시작하는 여러 클래스가 포함되어 있습니다.
이러한 클래스들은 안전한 동시성 응용 프로그램을 만들 수 있도록 도와주는 동시성 프리미티브 (concurrency primitive) 들입니다.
[Warning] AtomicBoolean은 Boolean 대신 사용할 수 없으며, AtomicInteger는 Integer가 아닙니다.
Atomic의 요점은 스레드로부터 안전한 가변 변수를 제공하는 것입니다.
[Note] atomic 은 모던 프로세서 기능의 이점을 활용하도록 구현되었습니다. 하드웨어와 OS에서 지원하는 경우 논 블로킹(락 프리)방식으로 동작할 수 있습니다. (최소한 하나의 스레드가 진행될 수 있는 경우 Lock Free 처리함.)
volatile 변수와 비슷하지만 더 제공되는 기능이 있습니다.
lock없이 사용 불가 하며 atomic 처리를 위한 메소드 (all or nothing, 처리 되거나, 아예 되지 않는 것을 의미하는것으로 보임) 를 제공합니다.
이러한 기능으로 atomic은 개발자들에게 공유 데이터에 대한 경쟁 조건을 피할 수 있는 매우 간단한 방법을 제공해줍니다.
Atomic의 사용 사례를 들어보면 SQL에서 제공하는 시퀸스 ID를 구현한다고 생각해봅시다.
아래와 같이 구현할 수 있습니다.
Atomic을 이용하여 accountId를 공유하는 것을 불가능 하도록 보장합니다.
또 다른 예시로 AtomicBoolean을 이용하여 volatile shutdown 패턴에 적용해보겠습니다.
AtomicReference는 atomic 한 변경을 하는데도 사용됩니다.
일반적인 사용 패턴은 안전한 수정 가능 상태가 되었을 때 CAS(compare and swap) 작업을 수행합니다.
6.3 잠금(Lock) 클래스
동기화를 위한 블록 구조 접근 방식은 단순한 잠금 개념을 기반으로 합니다. 그렇다보니 아래와 같은 단점이 있습니다.
- 한 가지 유형의 잠금만 존재합니다.
- 잠긴 개체에 대한 모든 동기화 작업이 동일하게 적용됩니다.
- 잠금은 동기화된 블록 또는 메소드 시작 시 획득됩니다.
- 잠금은 블록 또는 메소드의 끝에서 해제됩니다.
- 잠금이 획득되거나 스레드가 무기한 차단되는, 두 가지 결과값만 있습니다.
우리가 락을 지원하는 기능을 개선한다면, 다음과 같이 개선할 수 있을 것입니다.
- 잠금의 유형을 추가. (ex. reader lock / writer lock 분리)
- 잠금을 한 블록으로 제한하지 않기. (잠금 메소드와 해제 메소드의 분리)
- 스레드가 잠금을 획득할 수 없는 경우 스레드가 취소하거나 계속하거나 다른 작업을 수행할 수 있도록 허용하기
- 일정 횟수 이상 잠금을 얻는데 실패했다면 포기하도록 처리하기
위와 같은 기능을 수행할 수 있도록 java.util.concurrent.locks 의 Lock 인터페이스가 있습니다. 이 인터페이스는 다음 구현체과 함께 제공됩니다.
- ReentrantLock : Java synchronized block과 비슷하지만 더 유연합니다.
- ReentrantReadWriteLock : 읽기 처리는 많지만 쓰기 처리가 적은 상황에서 유리합니다.
[Note] 다른 구현체도 있지만 위 2가지가 가장 일반적으로 사용됩니다.
Lock 인터페이스를 이용해서 기본의 블록 구조 동시성을 대체할 수 있습니다.
ReentrantLock의 사용 예는 다음과 같습니다.
위 코드에서
첫 번째 락과 두 번째 락이 있는 이유는 A 가 B에게 보내는 동안에 B가 다른 계좌로 이체를 시도할 경우 정합성이 깨지게 되기 때문이고
첫 번째 락과 두 번째 락의 순서를 정하는 이유는 아래와 같은 상황을 방지하고자 함입니다.
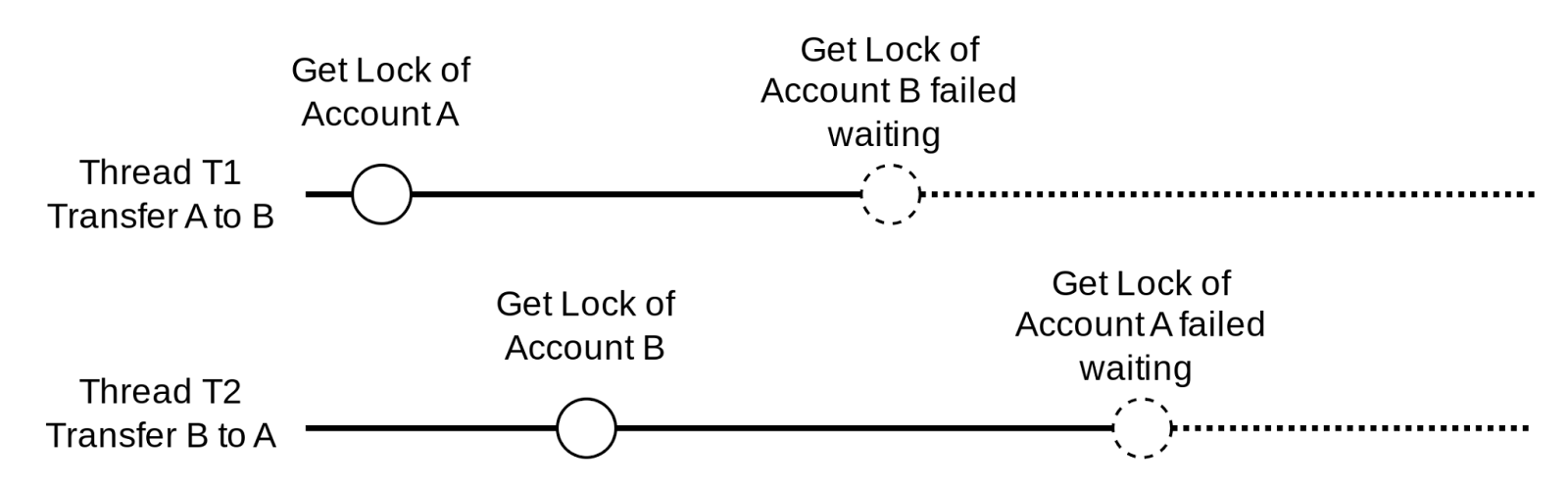
try … finally 블록과 결합된 잠금 구조는 큰 개선사항입니다.
다만 Lock 개체를 전달해야 하는 경우 (메서드에서 반환) 이 패턴을 사용할 수 없습니다.
6.3.1 조건(Condition) 객체
java.util.concurrent 에서 제공하는 또 다른 API는 조건 개체 입니다.
스레드가 특정 조건에서 대기하고 있다가 특정 조건이 참이 되면 깨어날 수 있는 기능을 제공합니다.
기본 스레드 에서 wait()와 notify()는 스레드를 구분하여 처리하는 것이 불가능 하였다면
Condition은 wait()와 signal() 이라는 함수를 제공하여 스레드에 따른 처리를 할 수 있게 만들어 줍니다.
Condition은 이미 생성된 lock으로부터 newCondition() 메소드를 호출하여 생성할 수 있습니다.
6.4 카운트다운래치
카운트다운래치(CountDownLatch, 참고로 래치는 걸쇠 라는 뜻이란다.)는 합의를 제공하는 간단한 동시성 프리미티브 입니다.
카운트다운래치는 초기화 할때 int 값을 매개변수로 받습니다. 이 매개변수는 카운트 다운할 때 사용됩니다.
생성 된 이후 countDown 과 await 라는 두 가지 메서드를 사용하여 래치를 제어합니다.
countDown은 카운트를 1씩 줄이고, await는 카운트가 0에 도달할 때까지 호출 스레드를 차단합니다 (카운트가 이미 0이면 아무것도 수행하지 않음.)
카운트다운래치를 사용한 예시는 다음과 같습니다.
여기서 CountDownLatch와 AtomicInteger를 함께 사용한 이유는 실제적으로 5번 호출이 정상적으로 되는지 확인하기 위함입니다. 실제 사용시에는 같이 사용할 필요는 없습니다.
쿼럼(정족수) 값을 2로 두고 동작 시뮬레이션을 해본다면 다음과 같이 나올 수 있습니다. (for문도 수정해줘야 합니다.)
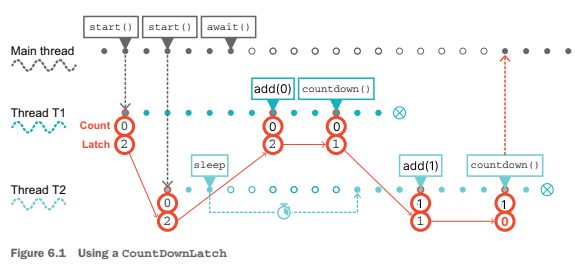
* 책에는 오류가 있어 알맞게 수정하였습니다.
카운트래치다운에 대한 좋은 사용 사례를 들어보자면
여러 개시를 참조 데이터로 미리 채워야 하는 어플리케이션을 고려해봅시다.
이 상황에서 공유 래치를 사용하면 이를 쉽게 달성할 수 있습니다.
로드를 마치면 캐시를 채우는 Runnable이 래치를 카운트다운해 나간다면 모든 캐시가 로드 되었을 때 메인 스레드에서 await을 마치고 이어서 서비스를 수행할 수 있을 것입니다.
6.5 동시성 해시 맵 (Concurrent Hash Map)
ConcurrentHashMap 클래스는 표준 HashMap의 동시 버전을 제공합니다.
맵은 동시성 응용 프로그램을 구축하는데 매우 유용한(그리고 흔히 사용되는) 자료 구조입니다.
6.5.1 간단한 해시맵의 이해
고전적인 Java HashMap은 Hash 함수를 사용하여 키-값 쌍을 저장할 버킷을 결정합니다.
키-값 쌍(key-value pair)은 키를 해싱하여 얻은 인덱스에 해당하는 버킷에 해당하는 연결 목록(해시 체인이라고 함)에 저장됩니다.
현재의 HashMap은 더 복잡한 구조이지만 여기서는 이해를 위해 Java 7의 해시맵을 기반으로 한 코드로 설명합니다. (일부 메소드는 구현하지 않았기 때문에 UnsupportedOperationException을 발생시킵니다.)
https://github.com/well-grounded-java/resources/blob/main/Ch06/ch06/Dictionary.java
내부적으로 indexFor 메소드를 이용하여 어떤 인덱스에 저장되어 있는지 찾습니다.
get 메소드는
먼저 null 입력에 대한 케이스를 처리합니다.
그 다음 키 개체의 해시 코드를 사용하여 배열 테이블에 대한 인덱스를 계산합니다.
[Note] 참고로 테이블의 크기는 bitwise operation을 처리해야 하므로 2의 거듭제곱이여야 합니다.
인덱스를 계산하면 이를 사용하여 조회 작업을 위한 해시 체인을 선택합니다.
헤드에서 시작하여 해시 체인을 따라 이동하고 찾았다면 해당 값을 반환합니다.
pub 메소드도 get 메소드와 유사하게 처리합니다.
6.5.2 Dictionary 구조의 한계
이 Dictionary의 경우 아래 기능을 제공하지 않습니다.
- 저장된 요소의 수가 증가함에 따라 테이블 크기 조정
- hashCode의 병리학적 문제를 방어
(여기서 병리학적(pathological) 이라는 것은, 현상이 직관과 어긋날 때 라고 함.)
6.5.3 Concurrent Dictionary 알아보기
위에서 소개한 Dictionary는 분명히 스레드로부터 안전하지 않습니다.
특정 키에 대해 하나는 삭제를, 하나는 업데이트를 시도하는 두 개의 스레드가 있다고 고려해보면 됩니다.
이 문제를 해결하기 위해 우리는 Dictionary를 개선할 수 있는 두가지 방법을 생각해보겠습니다.
첫번째 방식는 5장에서 보았던 완전 동기화 접근 방식입니다.
이 접근 방식은 성능 오버헤드로 인해 실제로는 사용하기 어렵습니다.
그러나 구현하는 방법을 살펴보는 것은 가치가 있습니다.
Dictionary 클래스를 복사하여 이를 ThreadSafeDictionary 라고 부르고 모든 메서드를 동기화 하도록 처리 합니다. 이 방법은 잘 동작하지만 많은 중복 코드를 발생시킵니다.
대신 우리는 동기화된 래퍼를 사용하여 기본 개체에 위임을 제공할 수 있습니다.
방법은 다음과 같습니다.
물론 이 예제에는 아직 여러 가지 문제가 있습니다.
그 중 가장 중요한 문제는 개체 d가 이미 존재하고 동기화되지 않는다는 것입니다.
이것은 동시성 자료 구조에 대한 올바른 접근이 될 수 없습니다.
(저자가 이야기 하고 싶은 것은 래퍼 객체를 생성한다 하더라도 d는 결국 동시성 자료 구조가 아니라는 것을 이야기 하려는 것 같음.)
실제로 JDK는 Collections 클래스 에서 제공되는 synchronizedMap 메서드를 제공합니다. 널리 사용되며 잘 동작합니다.
두번째 방식은 불변성을 이용하는 것입니다.
이렇게 구현하는 것은 문제점이 있는데 Map 의 유효한 기능 API를 통해 인스턴스를 변경하려고 하였때 에러가 발생된다는 것입니다. 이는 객체 지향 원칙을 위반한 것이라 볼 수 있습니다.
또한 방식 1과 마찬가지로 여전히 변경 가능한 객체가 존재하게 됩니다.
6.5.4 ConcurrentHashMap 사용하기
ConcurrentHashMap의 핵심은 여러 스레드가 한 번에 업데이트하는 것이 안전하다는 것입니다. 이것이 필요한 이유를 알아보기 위해 HashMap 에 항목을 동시에 추가하는 두 개의 스레드가 있을 때 어떤 일이 발생되는지 알아보겠습니다. (예외 처리 생략)
SIZE 값을 늘려서 테스트 해보면 더 쉽게 문제를 확인할 수 있습니다.
이 예시 코드에서는 Lost Update(갱신 손실) 안티패턴을 볼 수 있습니다. (갱신 손실은 두 개 이상의 트랙잭션(or 스레드)이 값을 바꾸려 할 때 발생, 업데이트가 다른 업데이트에 덮어씌워지면서 Lost 되는 것을 나타냄)
또 맵을 업데이트하려는 스레드 중 하나가 완료되지 않는 현상을 경험할 수도 있습니다. (무한 루프에 빠짐)
반면에 HashMap을 ConcurrentHashMap 으로 바꾸면 문제없이 작동하는 것을 확인할 수 있습니다.
이것이 어떻게 달성될 수 있는지에 대해서 살펴보겠습니다.
ConcurrentHashMap은 전체 구조를 잠그는 대신 변경되거나 읽히는 해시 체인만 잠그는 전략을 사용합니다.
이 기술을 잠금 스트라이핑(lock striping) 이라고 합니다. 이를 통해 여러 스레드가 서로 다른 체인에서 작동하는 경우 맵에 액세스 할 수 있습니다. 물론 두 개의 스레드가 동일한 체인에서 작동해야 하는 경우 여전히 서로를 제외 해야 하지만, 기존에 비해 더 나은 처리량을 제공합니다.
서로 데이터를 공유해야 하는 다중 스레드 프로그램을 개발해야 한다면 ConcurrentHashMap을 사용하십시오.
ConcurrentMap 인터페이스는 Map을 확장하였습니다.
스레드로부터 안전한 수정을 제공하기 위해 다음과 같은 새로운 메서드를 포함하였습니다.
- putIfAbsent() : 키가 아직 없는 경우 HashMap 에 키-값 쌍을 추가합니다.
- remove() : 키가 있는 경우 키-값 쌍을 안전하게 제거합니다.
- replace() : 안전한 교체를 위해 HashMap의 replace와 다른 2가지 형태를 제공합니다.
ConcurrentMap의 경우 멀티스레드 안정성을 제공하지만 더 많은 성능을 사용하여, 일반적인 환경에서는 심각한 단점이 될 수 있습니다.
fin.