11장 뉴스 피드 시스템 설계
가상 면접 사례로 배우는 대규모 시스템 설계 기초 – System Design Interview
개인적으로 이번 장은 두리뭉실하게 나온 부분이 많은 것 같아 너무 아쉬운 장이였다.
용어 통일에서도 조금 아쉬운 면이 있었던 것 같다.
뉴스피드(news feed)란
“뉴스 피드는 여러분의 홈 페이지 중앙에 지속적으로 업데이트되는 스토리들로, 사용자 상태 정보 업데이트, 사진, 비디오, 링크, 앱 활동(app activity), 그리고 여러분이 페이스북에서 팔로우하는 사람들, 페이지, 또는 그룹으로부터 나오는 ‘좋아요’ 등을 포함한다.”
- facebook -
페이스북, 인스타그램. 트위터 등에서 사용
1단계 문제 이해 및 설계 범위 확정
질문 예시
- 모바일 앱을 위한 시스템인가요? 아니면 웹? 둘 다 지원해야 합니까?
- 중요한 기능으로는 어떤 것이 있을까요?
- 뉴스 피드에는 어떤 순서로 스토리가 표시되어야 하나요? 최신순 인가요? 아니면 토픽 점수(topic score) 같은 다른 기준이 있습니까?
- 한 명의 사용자는 최대 몇 명의 친구를 가질 수 있습니까?
- 트래픽 규모는 어느 정도입니까?
- 피드에 이미지나 비디오 스토리도 올라올 수 있습니까?
2단계 개략적 설계안 제시 및 동의 구하기
(1) 피드 발행(feed publishing) 과 (2) 뉴스 피드 생성(news feed building)의 두 가지 부분으로 나누어 진행한다.
피드 발생 : 사용자가 스토리를 포스팅하면 해당 데이터를 캐시와 데이터베이스에 기록한다.
뉴스 피드 생성 : 뉴스 피드는 모든 친구의 포스팅을 시간 흐름 역순으로 모아서 만든다고 가정.
* 피드가 각 스토리를 의미하고 뉴스 피드가 스토리의 모음을 의미하는 것으로 이해하고 감.
뉴스 피드 API
피드 발행 API
새 스토리를 포스팅하기 위한 API
POST /v1/me/feed
인자
body: 포스팅 내용
Authorization 헤더: API 호출을 인증하기 위해 사용
피드 읽기 API
뉴스 피드를 가져오는 API
GET /v1/me/feed
인자
Authorization 헤더: API 호출을 인증하기 위해 사용
피드 발행
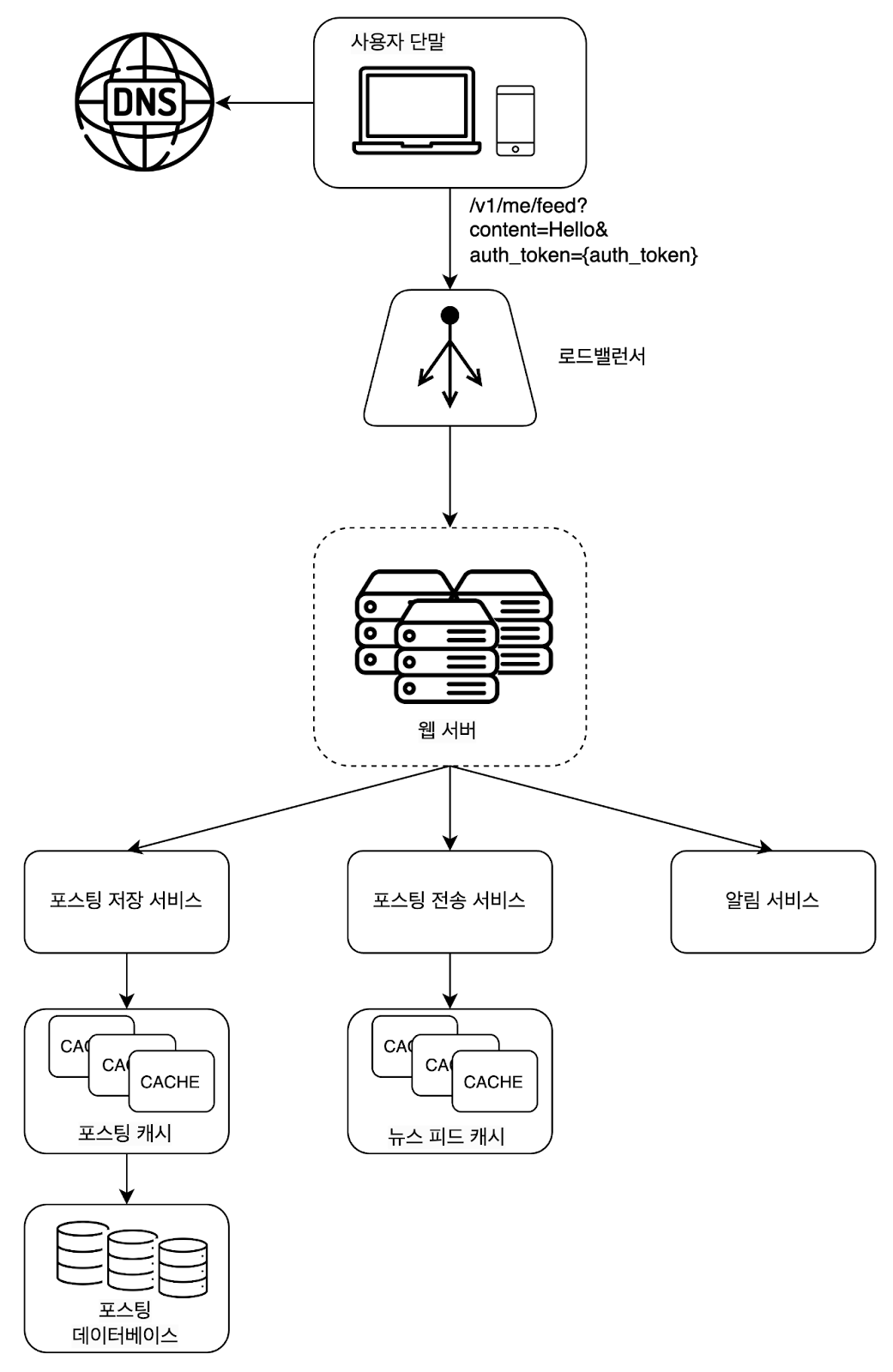
사용자 : 새 포스팅을 올리는 주체. POST /v1/me/feed API를 호출
로드밸런서(load balancer): 트래픽을 웹 서버들로 분산한다.
웹 서버: HTTP 요청을 내부 서비스로 중계하는 역할을 담당한다.
포스팅 저장 서비스(post service): 새 포스팅을 데이터베이스와 캐시에 저장한다.
포스팅 전송 서비스(fanout service): 새 포스팅을 친구의 뉴스 피드에 푸시(push)한다. 뉴스 피드 데이터는 캐시에 보관하여 빠르게 읽어갈 수 있도록 한다.
알림 서비스(notification service): 친구들에게 새 포스팅이 올라왔음을 알리거나, 푸시 알림을 보내는 역할을 담당한다.
책의 그림에는 “피드 캐시” 라고 적혀있는데
이 부분(p186.)에서 피드 캐시 / 뉴스 피드 캐시 의 용어 통일이 안된 것으로 보임
읽으면서 서로 다른 것인가 고민을 하였는데 고민해본 결과 같은 것이라고 판단함.
따라서 혼란을 막기 위해 동일하다고 생각하고 뉴스 피드 캐시로 통일하여 정리.
그렇게 생각 한 이유:
1. 바로 위 내용에 뉴스 피드 데이터를 저장하는 캐시라고 되어 있음.
여기서 캐시에 저장한 것을 “뉴스 피드 생성” API 에서 받아가는 것이 흐름상 자연스러움.
2. 후반부(p189.)에는 뉴스 피드 캐시로 나와있음.
뉴스 피드 생성

사용자 : 뉴스 피드를 읽는 주체. GET /v1/me/feed API를 이용한다.
로드밸런서(load balancer): 트래픽을 웹 서버들로 분산한다.
웹 서버: 트래픽을 웹 서버들로 분산한다.
뉴스 피드 서비스(news feed service): 캐시에서 뉴스 피드를 가져오는 서비스.
뉴스 피드 캐시(news feed cache): 뉴스 피드를 렌더링할 때 필요한 피드 ID를 보관한다.
3단계 상세 설계
피드 발행 흐름 상세 설계
웹 서버
웹 서버는 클라이언트와 통신할 뿐 아니라 인증이나 처리율 제한 등의 기능도 수행한다.
포스팅 전송(팬아웃) 서비스
포스팅 전송, 즉 팬아웃(fanout)은 어떤 사용자의 새 포스팅을 그 사용자와 친구 관계에 있는 모든 사용자에게 전달하는 과정이다.
팬아웃에는 두 가지 모델이 있는데
하나는 쓰기 시점에 팬아웃(fanout-on-write)하는 모델이고(푸시 모델이라고도 함),
다른 하나는 읽기 시점에 팬아웃(fanout-on-read)하는 모델이다(풀 모델이라고도 함)
쓰기 시점에 팬아웃 하는 모델
장점
- 뉴스피드가 실시간으로 갱신되며 친구 목록에 있는 사용자에게 즉시 전송된다.
- 새 포스팅이 기록되는 순간에 뉴스 피드가 이미 갱신되므로(pre-computed)
단점
- 친구가 많은 사용자의 경우 친구 목록을 가져오고 그 목록에 있는 사용자 모두의 뉴스 피드를 갱신하는 데 많은 시간이 소요될 수 도 있다. (핫키(hotkey) 라고 부르는 문제다.)
- 서비스를 자주 이용하지 않는 사용자의 피드까지 갱신해야 하므로 컴퓨팅 자원이 낭비된다.
읽기 시점에 팬아웃 하는 모델
장점
- 비활성화된 사용자, 또는 서비스에 거의 로그인하지 않는 사용자의 경우에는 이 모델이 유리하다. 로그인하기까지는 어떤 컴퓨팅 자원도 소모하지 않아서다.
- 데이터를 친구 각각에 푸시하는 작업이 필요 없으므로 핫키 문제도 생기지 않는다.
단점
- 뉴스피드를 읽는 데 많은 시간이 소요될 수 있다.
본 설계안은 이 두 가지 방법을 결합하여 사용한다.
친구나 팔로워가 아주 많은 사용자의 경우에는 팔로어로 하여금 해당 사용자의 포스팅을 필요할 때 가져가도록 하는 풀 모델을 사용
안정 해시를 통해 요청과 데이터를 보다 고르게 분산하여 핫키 문제를 줄임.
팬 아웃과 관련된 부분을 정리하면 다음과 같다.
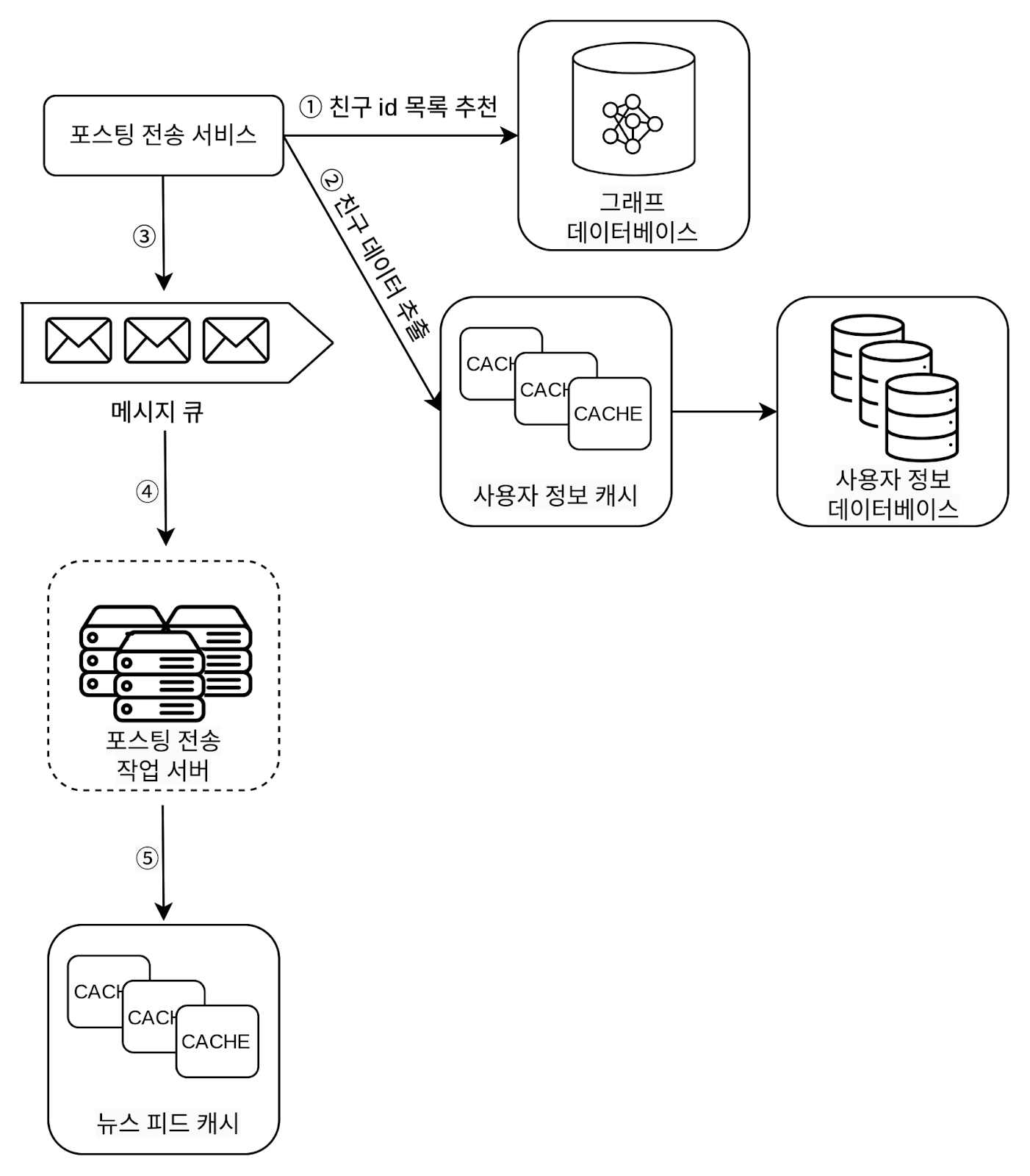
팬아웃 서비스는 다음과 같이 동작한다.
1. 그래프 데이터베이스에서 친구 ID 목록을 가져온다. 그래프 데이터베이스는 친구 관계나 친구 추천을 관리하기 적합하다.
관련 논문 : TAO: facebook's distributed date store for the social graph
2. 사용자 정보 캐시에서 친구들의 정보를 가져온다. 그런 후에 사용자 설정에 따라 친구 가운데 일부를 걸러낸다. (ex. 내 글에 대해서 mute 처리한 친구)
3. 친구 목록과 새 스토리의 포스팅 ID를 메시지 큐에 넣는다.
4. 포스팅 전송(팬아웃) 작업 서버가 메시지 큐에서 데이터를 꺼내어 뉴스 피드 데이터를 뉴스 피드 캐시에 넣는다.
뉴스피드 캐시는 <포스팅 ID, 사용자 ID>의 순서쌍을 보관하는 매핑 테이블이라고 볼 수 있다.
새로운 포스팅이 만들어질 때마다 이 캐시에 레코드들이 추가될 것이다.
(메모리 절약을 위해 최소한의 데이터를 저장한다.)
메모리 크기를 적정 수준으로 유지하기 위해서, 이 캐시의 크기에 제한을 두며, 해당 값은 조정이 가능하도록 한다.
사용자가 수천 개의 스토리를 전부 훑어보는 일이 벌어질 확률은 지극히 낮다.
대부분의 사용자가 보려 하는 것은 최신 스토리다. 따라서 캐시 미스(cache miss)가 일어날 확률은 낮다.
피드 읽기 흐름 상세 설계

1. 사용자가 뉴스피드를 읽으려는 요청을 보낸다. 요청은 /v1/me/feed로 전송될 것이다.
2. 로드밸런서가 요청을 웹 서버 가운데 하나로 보낸다.
3. 웹 서버는 피드를 가져오기 위해 뉴스 피드 서비스를 호출한다.
4. 뉴스 피드 서비스는 뉴스 피드 캐시에서 포스팅 ID 목록을 가져온다.
5. 뉴스 피드에 표시할 사용자 이름, 사용자 사진, 포스팅 콘텐츠, 이미지 등을 사용자 캐시와 포스팅 캐시에서 가져와 완전한 뉴스 피드를 만든다.
6. 생성된 뉴스 피드를 JSON 형태로 클라이언트에게 보낸다. 클라이언트는 해당 피드를 렌더링 한다.
캐시구조
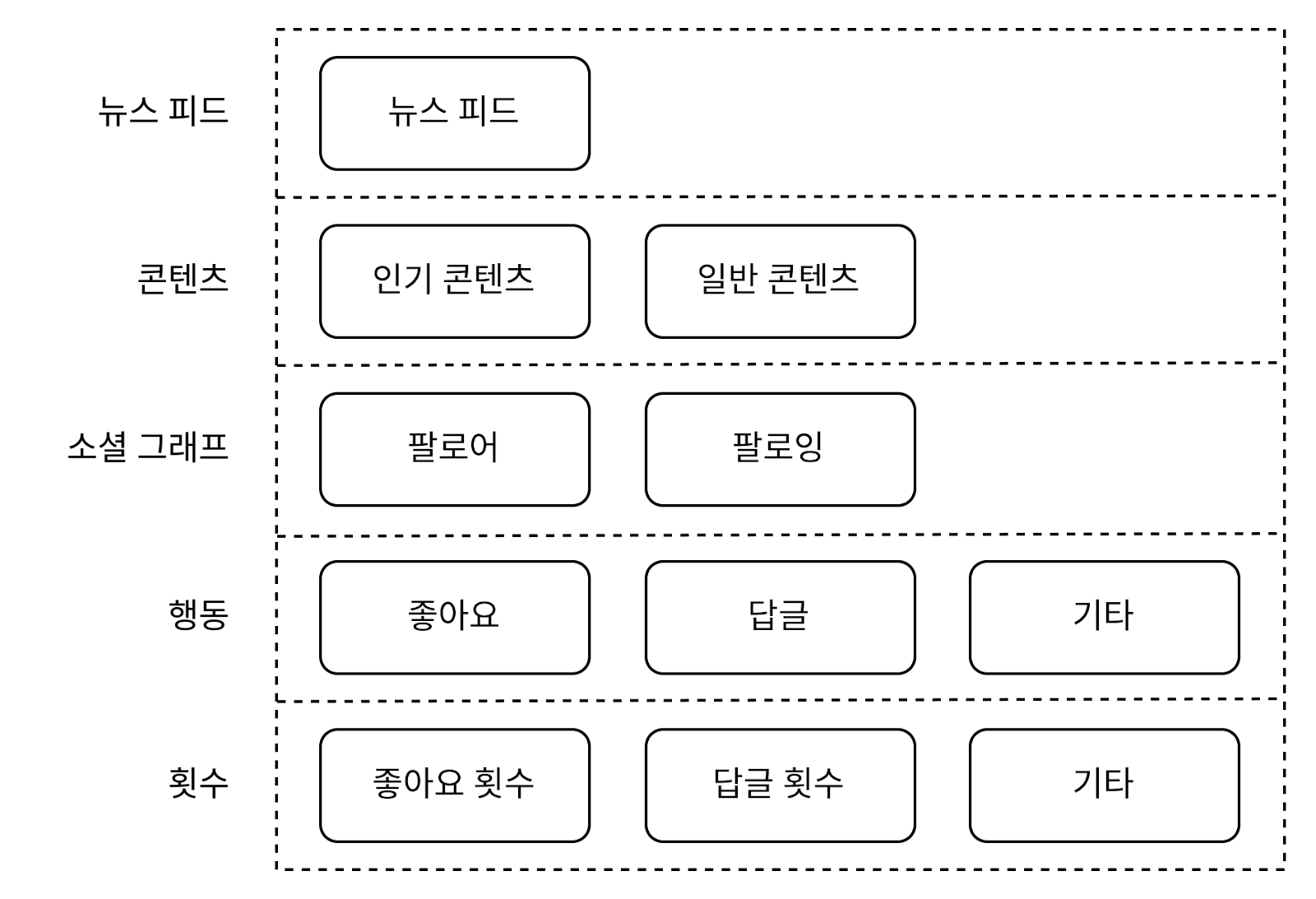
뉴스 피드: 뉴스 피드의 ID를 보관한다.
콘텐츠: 포스팅 데이터를 보관한다. 인기 콘텐츠는 따로 보관한다.
소셜 그래프: 사용자 간 관계 정보를 보관한다.
행동(action): 포스팅에 대한 사용자의 행위에 관한 정보를 보관한다. 포스팅에 대한 ‘좋아요’, 답글 등등이 이에 해당한다.
횟수(counter): 좋아요 횟수, 응답 수, 팔로어 수, 팔로잉 수 등의 정보를 보관한다.
4단계 마무리
이번 문제에도 정답은 없다. 회사마다 독특한 제약이나 요구 조건이 있기 때문에, 시스템을 설계할 때는 그런 점을 고려해야만 한다. 설계를 진행하고 기술을 선택할 때는 그 배경에 어떤 타협적 결정 (trade-off)들이 있었는지 잘 이해하고 설명할 수 있어야 한다.
추가적으로 다루면 좋은 것들
데이터베이스 규모 확장
- 수직적 규모 확장 vs 수평적 규모 확장
- SQL vs NoSQL
- 주-부(master-slave)에 대한 읽기 연산
- 일관성 모델
- 데이터베이스 샤딩
웹 계층(web tier)을 무상태로 운영하기
가능한 많은 데이터를 캐시할 방법
여러 데이터 센터를 지원할 방법
메시지 큐를 사용하여 컴포넌트 사이의 결합도 낮추기
핵심 메트릭(key metric)에 대한 모니터링
fin.