6장 키-값 저장소 설계
가상 면접 사례로 배우는 대규모 시스템 설계 기초 – System Design Interview
6장 키-값 저장소 설계
도입
키-값 저장소(key-value store)는 키-값 데이터베이스라고도 불리는 비 관계형(non-relational) 데이터베이스 이다. 이 저장소에 저장되는 값은 고유 식별자(identifier)를 가져야 한다. 키와 값 사이의 이런 연결 관계를 “키-값” 쌍(pair)이라고 지칭한다.
키는 짧을수록 좋다.
키-값 저장소로 널리 알려진 것으로는
- 아마존 다이나모
- memcached
- redis
같은 것들이 있다.
이번 장에서는 다음 연산을 지원하는 키-값 저장소를 설계한다.
- put(key, value): 키-값 쌍을 저장소에 저장한다.
- get(key): 인자로 주어진 키에 매달린 값을 꺼낸다.
문제 이해 및 설계 범위 확정
완벽한 설계란 없다.
읽기, 쓰기 그리고 메모리 사용량 사이에 어떤 균형을 찾고 데이터의 일관성과 가용성 사이에서 타협적 결정을 내린 설계를 만들었다면 쓸만한 답안일 것이다.
이번 장에서는 다음 특성을 갖는 키-값 저장소를 설계해 볼 것이다.
- 키-값 쌍의 크기는 10KB 이하이다.
- 큰 데이터를 저장할 수 있어야 한다.
- 높은 가용성을 제공해야 한다. 따라서 시스템은 설사 장애가 있더라도 빨리 응답해야 한다.
- 높은 규모 확장성을 제공해야 한다. 따라서 트래픽 양에 따라 자동적으로 서버 증설/삭제가 이루어져야 한다.
- 데이터 일관성 수준은 조정이 가능해야 한다.
- 응답 지연시간(latency)이 짧아야 한다.
단일 서버 키-값 저장소
한 대의 서버만 사용하는 키-값 저장소를 설계하는 것은 쉽다.
가장 직관적인 방법은 키-값 쌍 전부를 메모리에 해시 테이블로 저장하는 것이다.
이 접근법은 빠른 속도를 보장하긴 하지만 모든 데이터를 메모리 안에 두는 것이 불가능할 수도 있다는 약점을 갖고 있다. 이 문제를 해결하기 위해 개선책으로는 다음과 같은 것이 있다.
- 데이터 압축(compression)
- 자주 쓰는 데이터만 메모리에 두고 나머지는 디스크에 저장
그러나 이렇게 개선한다고 해도, 한 대 서버로 부족한 때가 곧 찾아온다.
많은 데이터를 저장하려면 분산 키-값 저장소(distributed key-value store)를 만들 필요가 있다.
분산 키-값 저장소
분산 키-값 저장소는 분산 해시 테이블이라고도 불린다. 키-값 쌍을 여러 서버에 분산시키는 탓이다. 분산 시스템을 설계할 때는 CAP 정리(Consistency, Availability, Partition Tolerance theorem)을 이해하고 있어야 한다.
CAP 정리
CAP 정리는 데이터 일관성(Consistency), 가용성(Availability), 파티션 감내(Partition Tolerance)라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다는 정리다.
각 요구사항의 의미는 다음과 같다.
- 데이터 일관성(Consistency)
- 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
- 가용성(Availability)
- 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
- 파티션 감내(Partition Tolerance)
- 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미한다. 파티션 감내는 네트워크에 파티션이 생기더라도 시스템은 계속 동작하여야 한다는 것을 뜻한다.
CAP 정리는 이들 가운데 어떤 두 가지를 충족하려면 나머지 하나는 반드시 희생되어야 한다는 것을 의미한다.

- CP 시스템
- 일관성과 파티션 감내를 지원하는 키-값 저장소
- 가용성을 희생한다.
- AP 시스템
- 일관성과 파티션 감내를 지원하는 키-값 저장소
- 데이터 일관성을 희생한다.
- CA 시스템
- 일관성과 가용성을 지원하는 키-값 저장소
- 파티션 감내를 희생한다.
* 분산 시스템은 반드시 파티션 문제를 감내할 수 있도록 설계되어야 한다. 그러므로 실세계에 CA 시스템은 존재하지 않는다. (네트워크 장애는 피할 수 없다.)
가정
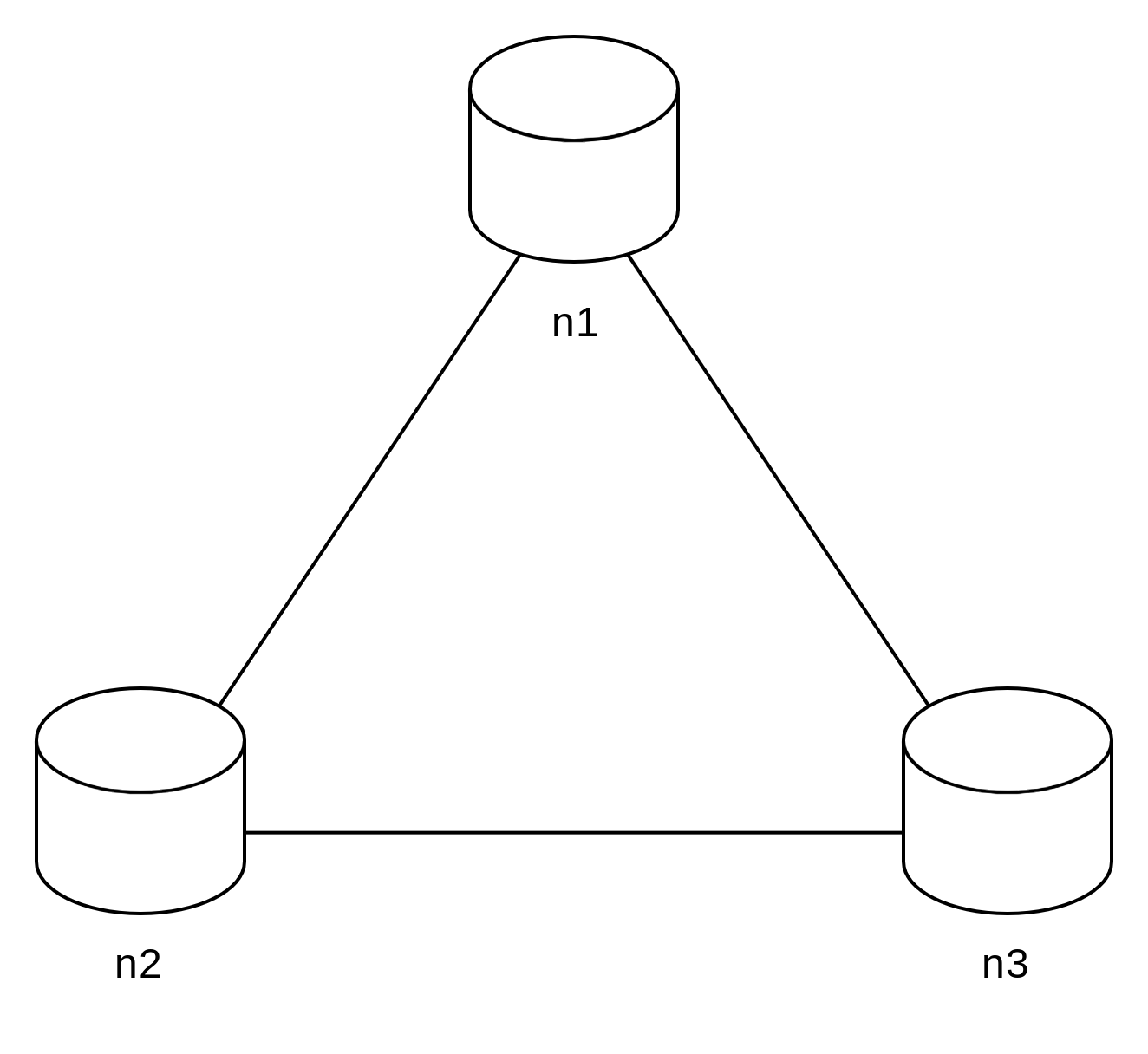
세 대의 복제(replica) 노드 n1, n2, n3에 데이터를 복제하여 보관하는 상황을 그림 6-2와 같이 가정해 보자.
이상적 상태
이상적 환경이라면 네트워크가 파티션되는 상황은 절대로 일어나지 않을 것이다.
n1에 기록된 데이터는 자동적으로 n2와 n3에 복제된다. 데이터 일관성과 가용성도 만족된다.
실세계의 분산 시스템
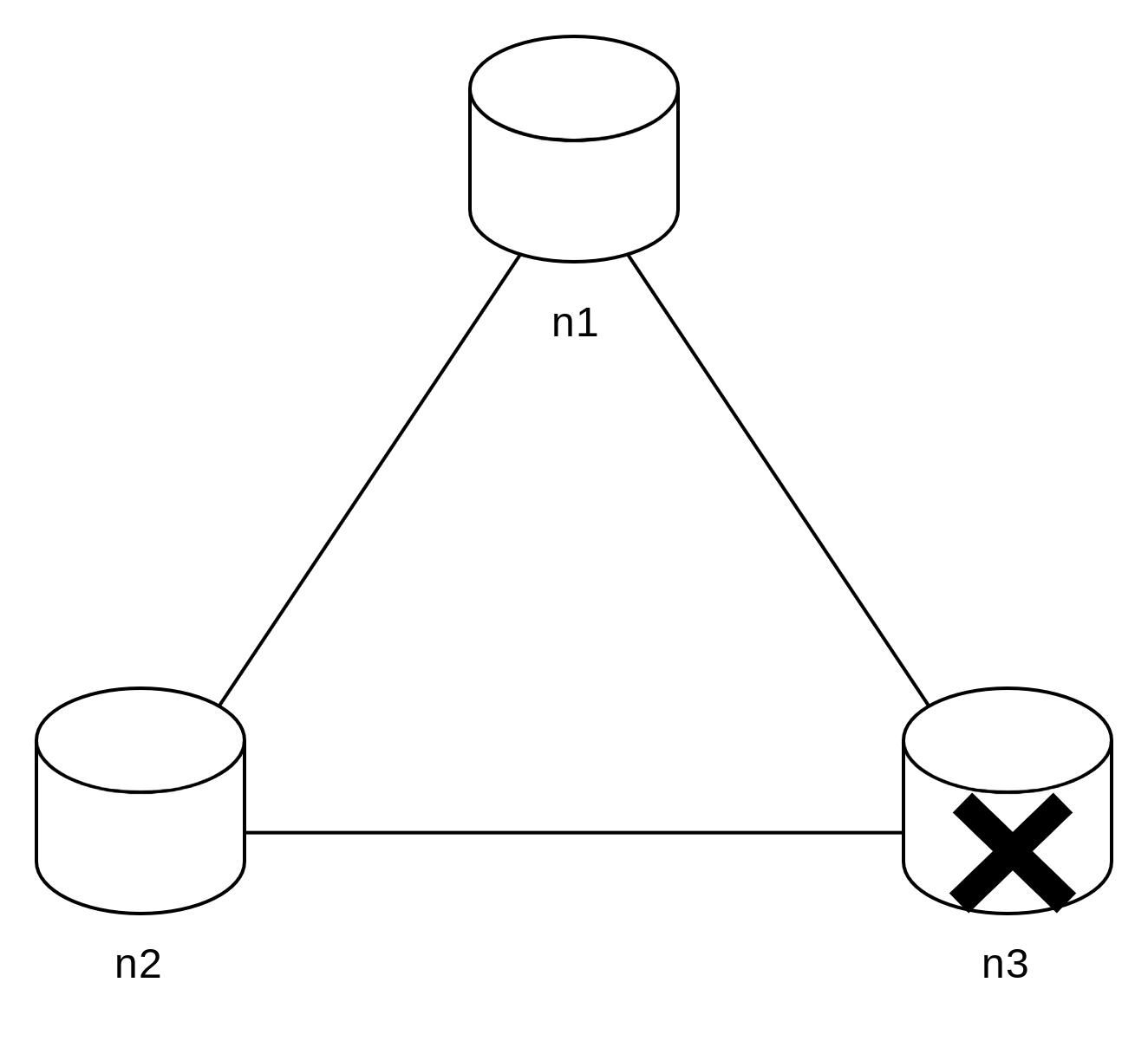
분산 시스템은 파티션 문제를 피할 수 없다. 그리고 파티션 문제가 발생하면 일관성과 가용성 사이에서 하나를 선택해야 한다.
클라이언트 n1 또는 n2에 기록된 데이터는 n3에 전달되지 않는다. n3 기록되었으나 아직 n1 및 n2로 전달되지 않은 데이터가 있다면 n1과 n2는 오래된 사본을 갖고 있을 것이다.
- 일관성을 선택할 경우 (CP 시스템)
세 서버 사이에 생길 수 있는 데이터 불일치 문제를 피하기 위해 n1과 n2에 대해 쓰기 연산을 중단시켜야 한다. 그렇게 하면 가용성이 깨진다.
은행권 시스템과 같이 일관성을 유지해야 할 때 사용한다. 상황이 해결될 때까지는 오류를 반환해야 한다.
- 가용성을 선택할 경우 (AP 시스템)
낡은 데이터를 반환할 위험이 있더라도 계속 읽기 연산을 허용해야 한다. n1과 n2는 계속 쓰기 연산을 허용할 것이고, 파티션 문제가 해결된 뒤에 새 데이터를 n3에 전송할 것이다.
분산 키-값 저장소를 만들 때는 그 요구사항에 맞도록 CAP 정리를 적용해야 한다.
시스템 컴포넌트
이번 절에 다루는 내용은 널리 사용되고 있는 세 가지 키-값 저장소, 즉 다이나모(Dynamo), 카산드라(Cassandra), 빅테이블(BigTable)의 사례를 참고한다.
데이터 파티션
대규모 애플리케이션의 경우 전체 데이터를 한 대 서버에 욱여넣는 것은 불가능하다. 가장 단순한 해결책은 데이터를 작은 파티션들로 분할한 다음 여러 대 서버에 저장하는 것이다.
데이터를 파티션 단위로 나눌 때는 다음 두 가지 문제를 중요하게 따져봐야 한다.
- 데이터를 여러 서버에 고르게 분산할 수 있는가
- 노드가 추가되거나 삭제될 때 데이터의 이동을 최소화 할 수 있는가.
안정 해시(consistent hash)는 이런 문제를 푸는 데 적합한 기술이다.
안정 해시를 사용하여 데이터를 파티션하면 좋은 점은 다음과 같다.
- 규모 확장 자동화(automation scaling): 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제되도록 만들 수 있다.
- 다양성(heterogeneity): 각 서버의 용량에 맞게 가상 노드의 수를 조정할 수 있다. 고성능 서버는 더 많은 가상 노드를 갖도록 설정할 수 있다.
데이터 다중화
높은 가용성과 안정성을 확보하기 위해 데이터를 N개 서버에 비동기적으로 다중화(replication)한다.
여기서 N은 튜닝 가능한 값이다.

가상 노드를 사용할 경우 N개의 노드가 대응될 실제 물리 서버의 개수가 N보다 작아질 수 있다. 이 문제를 피하려면 노드를 선택할 때 같은 물리 서버를 중복 선택하지 않도록 해야 한다.
같은 데이터 센터에 속한 노드는 문제를 동시에 겪을 가능성이 있다. 따라서 안정성을 담보하기 위해 데이터의 사본은 다른 센터의 서버에 보관하고, 센터들은 고속 네트워크로 처리한다.
데이터 일관성
- 일관성 모델
- 비 일관성 해소 기법: 데이터 버저닝
- 장애 처리
- 장애 감지
- 일시적 장애 처리
- 영구 장애 처리
- 데이터 센터 장애 처리
이 부분은 내용이 길어지므로 별도의 포스트로 정리한다.
시스템 아키텍처 다이어그램
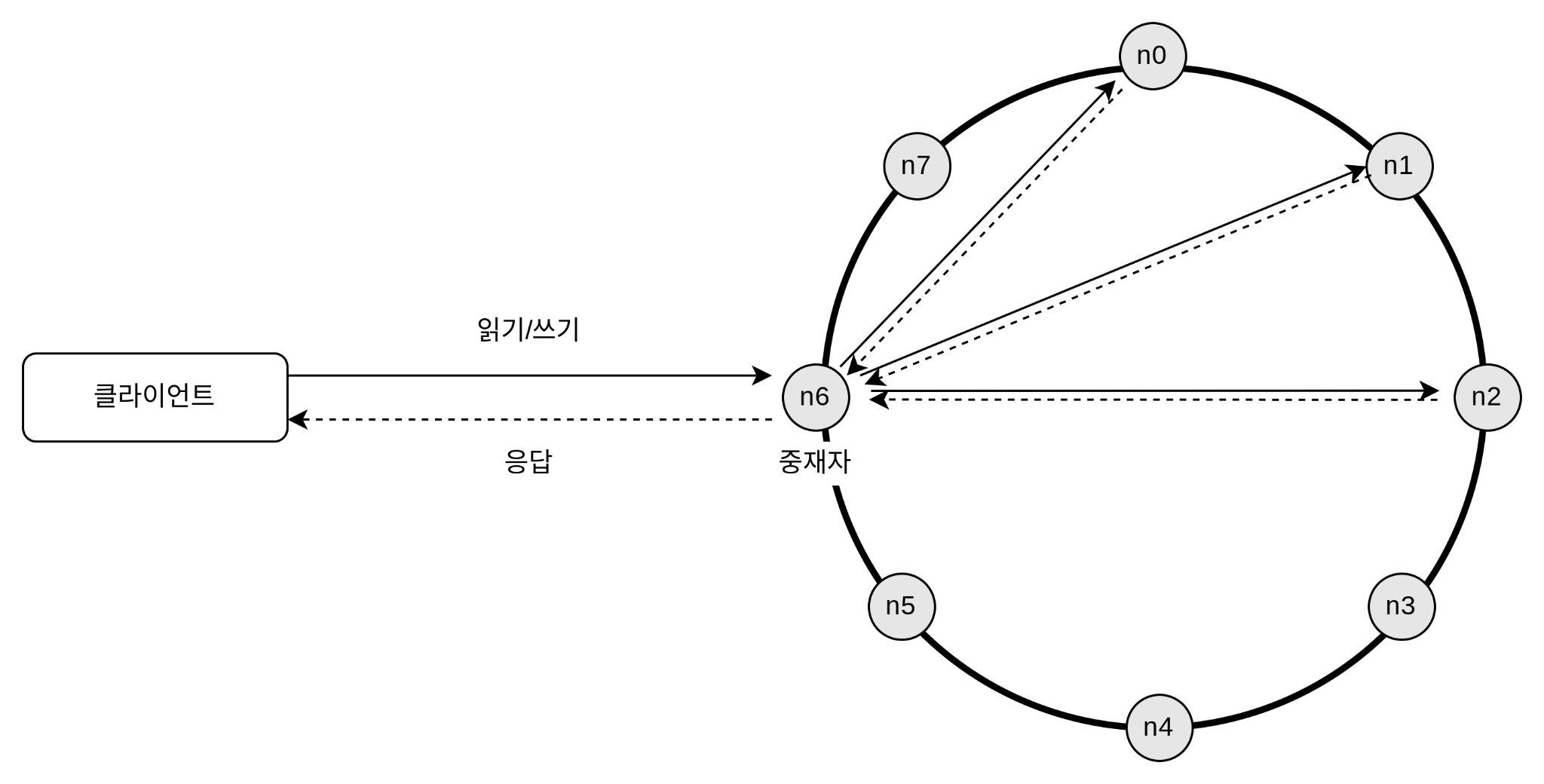
이 아키텍처의 주된 기능은 다음과 같다.
- 클라이언트는 키-값 저장소가 제공하는 두 가지 단순한 API, 즉 get(key) 및 put(key, value)와 통신한다.
- 중재자(coordinator)는 클라이언트에게 키-값 저장소에 대한 프락시(proxy) 역할을 하는 노드다.
- 노드는 안정 해시(consistent hash)의 해시 링(hash ring) 위에 분포한다.
- 노드를 자동으로 추가 또는 삭제할 수 있도록, 시스템은 완전히 분산된다(decentralized).
- 데이터는 여러 노드에 다중화된다.
- 모든 노드가 같은 책임을 지므로, SPOF(Single Point of Failure)는 존재하지 않는다.
쓰기 경로
쓰기 요청이 특정 노드에 전달되면 무슨일이 일어날까 (카산드라 기준)
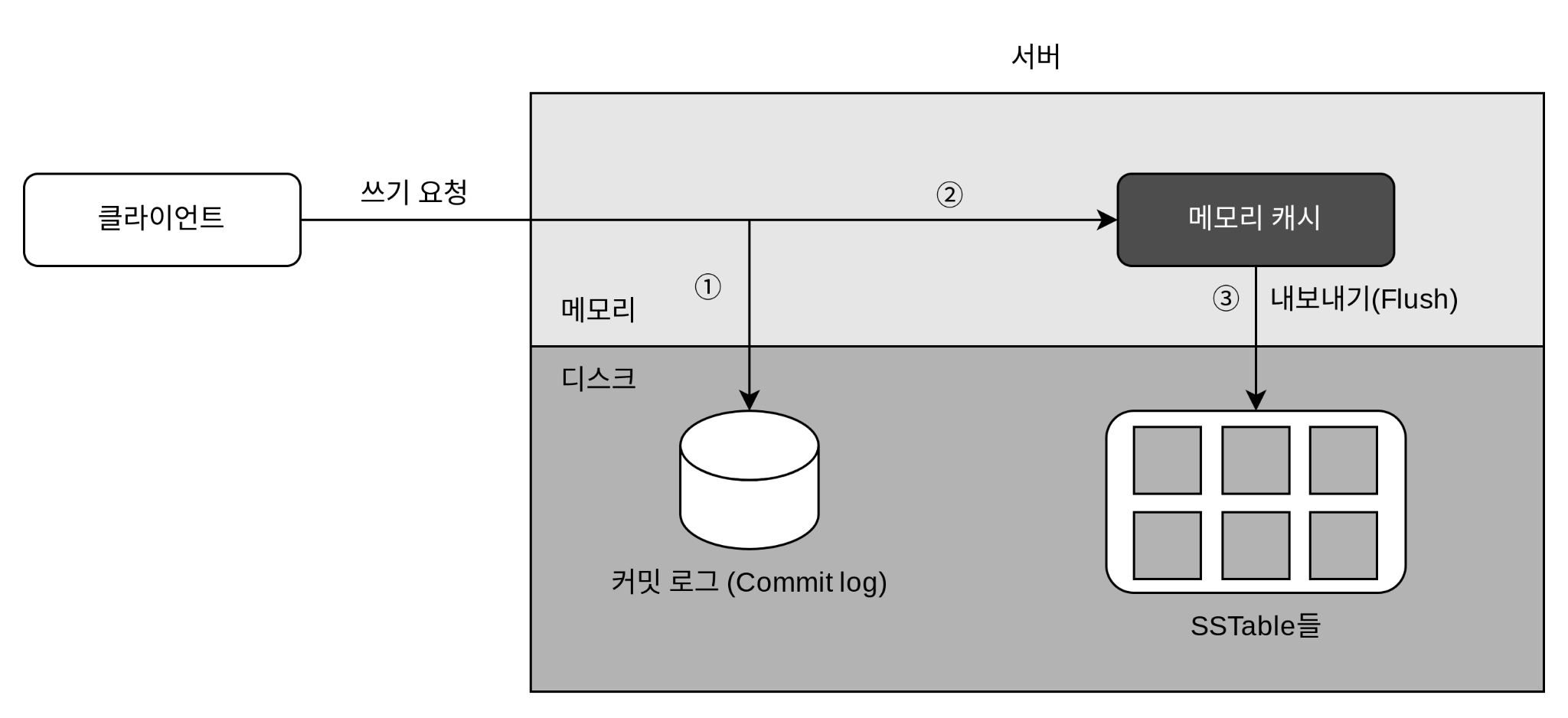
① 쓰기 요청이 커밋 로그(commit log) 파일에 기록된다.
② 데이터가 메모리 캐시에 기록된다.
③ 메모리 캐시가 가득차거나 사전에 정의된 어떤 임계치에 도달하면 데이터는 디스크에 있는 SSTable에 기록된다.
SSTable은 Sorted-String Table의 약어로, <키, 값>의 순서쌍을 정렬된 리스트 형태로 관리하는 테이블이다.
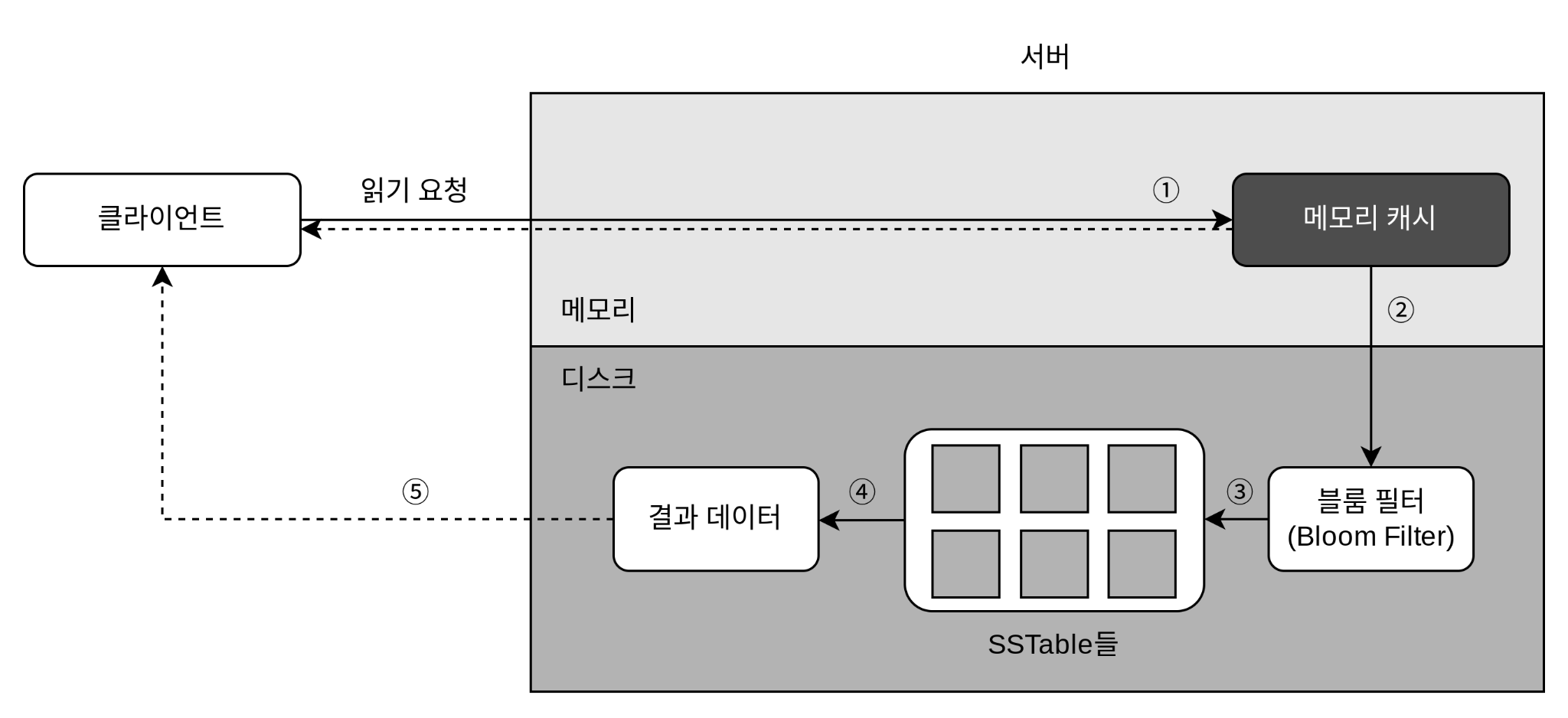
읽기 경로
읽기 요청이 특정 노드에 전달되면 무슨일이 일어날까 (카산드라 기준)
데이터가 메모리에 있는 경우
① 데이터가 메모리에 있는지 검사한다. 있으면 클라이언트에게 바로 반환한다.
데이터가 메모리에 없을 경우
① 데이터가 메모리에 있는지 검사한다. 없으면 ②로 간다.
② 데이터가 메모리에 없으므로 블룸 필터를 검사한다.
③ 블룸 필터를 통해 어떤 SSTable에 키가 보관되어 있는지 알아낸다.
④ SSTable에서 데이터를 가져온다.
⑤ 해당 데이터를 클라이언트에게 반환한다.
어느 SSTable에 찾는 키가 있는지 찾아내기 위해 Bloom filter가 흔히 사용된다.
요약
분산 키-값 저장소가 가져야 하는 기능과 그 기능 구현에 이용되는 기술
| 목표/문제 | 기술 |
|---|---|
| 대규모 데이터 저장 | 안정 해시를 사용해 서버들에 부하 분산 |
| 읽기 연산에 대한 높은 가용성 보장 | 데이터를 여러 데이터센터에 다중화 |
| 쓰기 연산에 대한 높은 가용성 보장 | 버저닝 및 벡터 시계를 사용한 충돌 해소 |
| 데이터 파티션 | 안정 해시 |
| 점진적 규모 확장성 | 안정 해시 |
| 다양성(heterogeneity) | 안정 해시 |
| 조절 가능한 데이터 일관성 | 정족수 합의(quorum consenus) |
| 일시적 장애 처리 | 느슨한 정족수 프로토콜(sloppy quorum)과 단서 후 임시 위탁(hinted handdoff) |
| 영구적 장애 처리 | 머클 트리(Merkle tree) |
| 데이터 센터 장애 대응 | 여러 데이터 센터에 걸친 데이터 다중화 |
fin.