API 제한 설정하기 - 처리율 제한 장치의 설계
가상 면접 사례로 배우는 대규모 시스템 설계 기초 – System Design Interview
4장 처리율 제한 장치의 설계
개요
처리율 제한 장치
클라이언트 또는 서비스가 보내는 트래픽의 처리율을 제어하기 위한 장치다.
특정 기간 내에 전송되는 클라이언트의 요청 횟수를 제한한다.
임계치를 넘어서면 추가로 도달한 모든 호출은 처리가 중단된다.
영어로는 Rate Limit.
처리율 제한 장치를 두면 좋은 점
- DOS 공격에 의한 자원 고갈을 방지할 수 있다.
- 비용을 절감한다. 서버를 많이 두지 않아도 되고, 우선순위가 높은 다른 API에 더 많은 자원을 할당할 수 있다.
- 서버 과부하를 막는다. 봇이나 사용자의 잘못된 이용 패턴으로 유발된 트래픽을 걸러낼 수도 있다.
1단계 문제 이해 및 설계 범위 확정
질문 할만한 요소들
- 처리율 제한의 주체는 어디인가? : 클라이언트인가 서버인가
- 어떠한 것을 기준으로 제한을 할 것인가? : IP 주소? 사용자 ID? 등등
- 시스템 규모는? : 스타트업 정도 회사를 위한 시스템인지 대규모 시스템인지
- 분산 환경에서도 동작해야 하는지
- 독립된 환경에서 동작해야하는지, 기존 애플리케이션 코드에 포함되야 하는지
이 글에서의 요구사항
- 설정된 처리율을 초과하는 요청은 정확하게 제한한다.
- 낮은 응답시간
- 가능한 한 적은 메모리를 써야 한다.
- 분산 처리율 제한 : 하나의 처리율 제한 장치를 여러 서버나 프로세스에서 공유할 수 있어야 한다.
- 예외 처리: 요청이 제한되었을 때는 그 사실을 사용자에게 분명하게 보여주어야 한다.
- 높은 결함 감내성(fault tolerance) : 제한 장치에 장애가 생기더라도 전체 시스템에 영향을 주어서는 안 된다.
2단계 개략적 설계안 제시 및 동의 구하기
처리율 제한 장치는 어디에 둘 것인가?
클라이언트 측에 둘 것인가? 서버 측에 둘 것인가?
클라이언트 쪽에 둔다면?
클라이언트 측에 두면 쉽게 위변조가 가능하다.
모든 클라이언트에 맞게 구현해야하는 것도 어려울 수 있다.
→ 가능하다면 서버측에 두는 것이 좋음
서버 측에 둔다면?
방법 1. 서버 측에서 구현

방법2. 미들웨어를 통한 구현
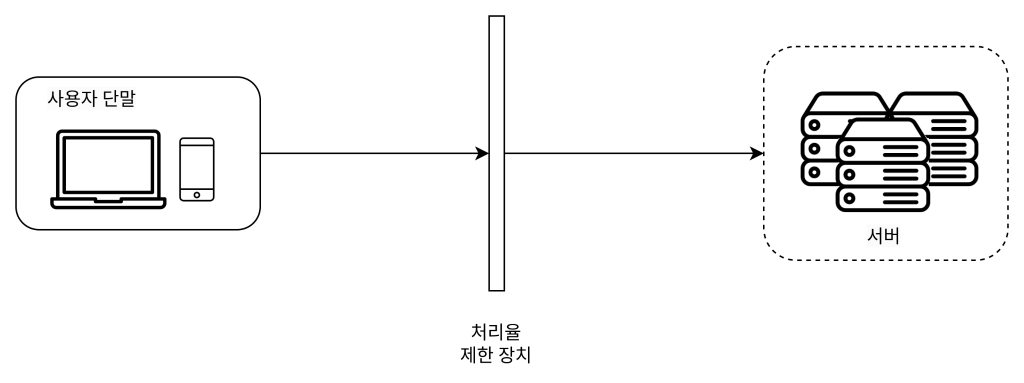
처리 임계치를 초과할경우 미들웨어에 의해 가로막히고 클라이언트로는 HTTP status code 429 가 반환된다.
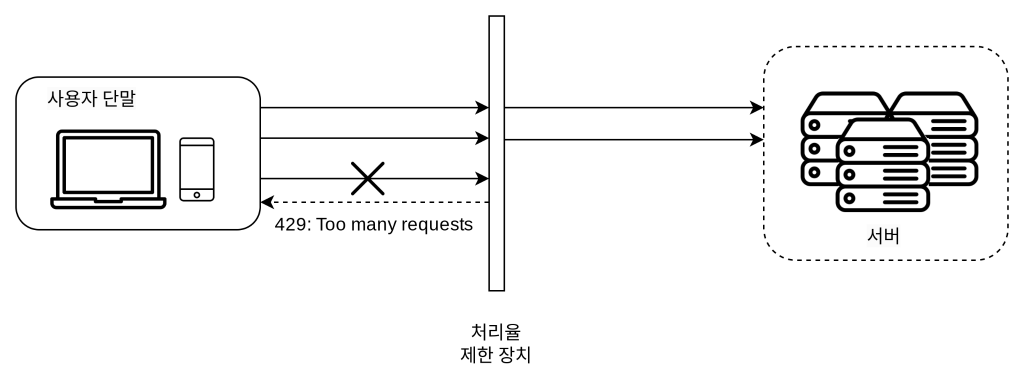
방법3. API 게이트웨이를 통한 구현
마이크로서비스를 사용할 경우 일반적으로 API 게이트웨이(gateway)에서 구현된다.
* API 게이트웨이는 처리율 제한 뿐 아니라 SSL 종단(termination), 사용자 인증(authentication), IP 허용 목록(whitelist) 관리 등을 지원하는 완전 위탁관리형 서비스(fully managed, 즉 클라우드 업체가 유지 보수를 담당)다
미들웨어와 API 게이트웨이 의 차이는 무엇일까?
An API gateway is middleware that sits between an API endpoint and backend services, transmitting client requests to an appropriate service of an application.
API 게이트웨이는 미들웨어의 한 유형이며, API 관리와 라우팅에 중점을 두고 동작한다.
어떤 것을 선택해야 하는가
정답은 없다. 회사의 기술 스택, 엔지니어링 인력, 우선순위, 목표에 따라 정하면 된다.
아래는 일반적으로 적용될 수 있는 지침들이다.
- 프로그래밍 언어, 캐시 서비스 등 현재 사용하고 있는 기술 스택을 점검하라. 현재 사용하는 프로그래밍 언어가 서버 측 구현을 지원하기 충분할 정도로 효율이 높은지 확인하라
- 사업 필요에 맞는 처리율 제한 알고리즘을 찾아라.
- 마이크로서비스에 기반하고 있고, 사용자 인증이나 IP 허용목록 관리 등을 처리하기 위해 API 게이트웨이를 이미 설계에 포함시켰다면 처리율 제한 기능 또한 게이트웨이에 포함시켜야 할 수 있다.
- 처리율 제한 서비스를 직접 만드는 데는 시간이 든다. 처리율 제한 장치를 구현하기에 충분한 인력이 없다면 상용 API 게이트웨이를 쓰는 것이 바람직한 방법일 것이다.
처리율 제한 알고리즘
널리 알려진 인기 알고리즘은 다음과 같은 것들이 있다.
- 토큰 버킷 (token bucket)
- 누출 버킷 (leaky bucket)
- 고정 윈도 카운터 (fixed window counter)
- 이동 윈도 로그 (sliding window log)
- 이동 윈도 카운터 (sliding window counter)
각 알고리즘에 대한 설명은 아래에서 이어서 진행한다.
개략적인 아키텍처
얼마나 많은 요청이 접수되었는지를 추적할 수 있는 카운터를 추적 대상별로 두고(사용자 별로 추적할 것인가? 아니면 주소별로? 아니면 API 엔드포인트나 서비스 단위로?) 카운터의 값이 어떤 한도를 넘어서면 한도를 넘어 도착한 요청은 거부한다.
여기서 카운터는 어디서 보관할 것인가? 데이터베이스는 디스크 접근때문에 느리므로 부적합하다. 메모리상에서 동작하는 캐시가 바람직하며, 시간에 기반한 만료 정책을 지원하면 좋다.
Redis는 이에 부합하여 처리율 제한에 자주 사용된다.
Redis는 INCR과 EXPIRE의 두 가지 명령어를 지원한다.
INCR: 메모리에 저장된 카운터의 값을 1만큼 증가시킨다.
EXPIRE: 카운터에 타임아웃 값을 설정한다. 설정된 시간이 지나면 카운터는 자동으로 삭제된다.
처리율 제한 장치의 개략적 구조를 그리면 다음과 같다.

개략적인 동작원리
- 클라이언트가 처리율 제한 미들웨어(rate limiting middleware)에게 요청을 보낸다.
- 처리율 제한 미들웨어는 레디스의 지정 버킷에서 카운터를 가져와서 한도에 도달했는지 아닌지를 검사한다.
- 한도에 도달했다면 요청은 거부된다.
- 한도에 도달하지 않았다면 요청은 API 서버로 전달된다. 이 때 미들웨어는 카운터의 값을 증가시킨 후 다시 레디스에 저장한다.
처리율 제한 알고리즘
토큰 버킷 알고리즘
보편적으로 사용되는 알고리즘
아마존과 스트라이프가 API 요청을 통제(throttle)하기 위해 사용
동작 원리
토큰 버킷은 지정된 용량을 갖는 컨테이너이다.
이 버킷에는 사전 설정된 양의 토큰이 주기적으로 채워진다.
토큰이 꽉 찬 버킷에는 더 이상의 토큰은 추가되지 않는다.
버킷이 가득 차면 추가로 공급된 토큰은 버려진다.
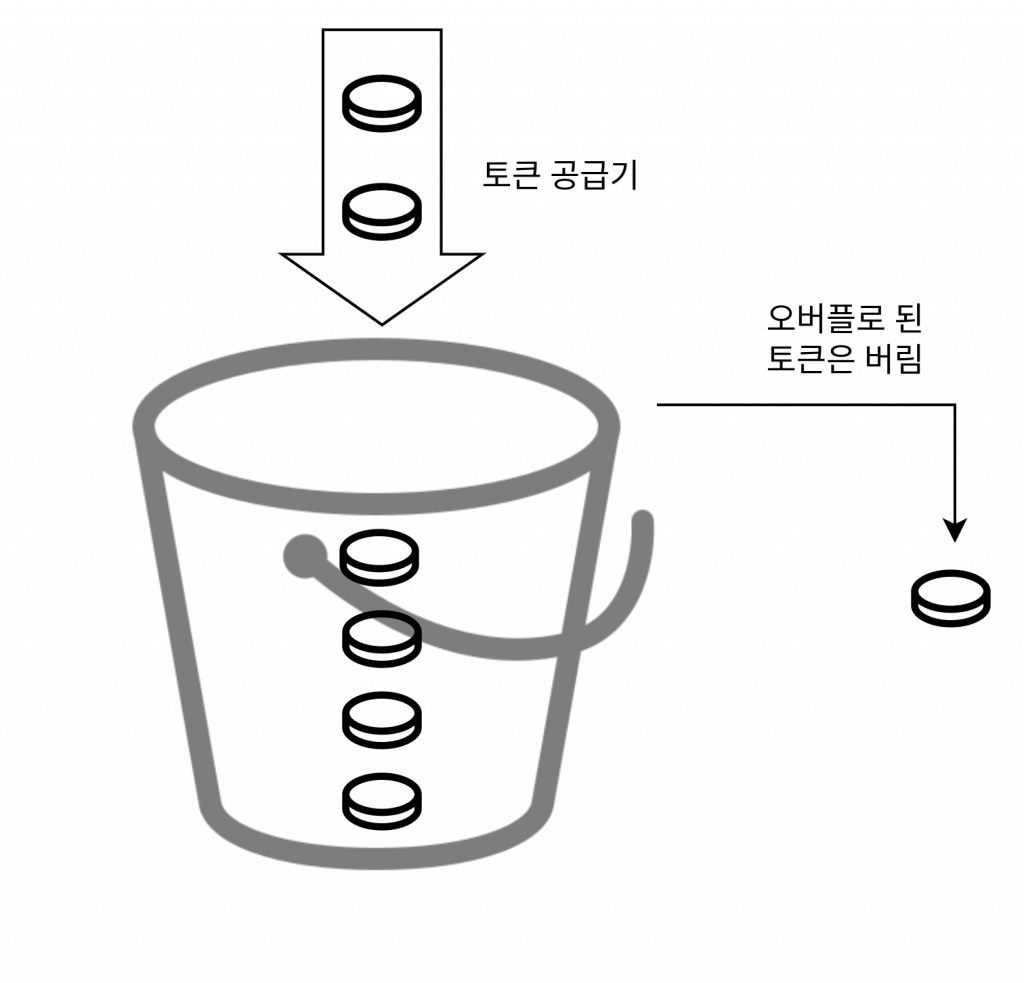
각 요청은 처리될 때마다 하나의 토큰을 사용한다.
요청이 도착하면 버킷에 충분한 토큰이 있는지 검사하게 된다.
충분한 토큰이 있는 경우, 버킷에서 토큰 하나를 꺼낸 후 요청을 시스템에 전달한다.
충분한 토큰이 없는 경우, 해당 요청은 버려진다(dropped)
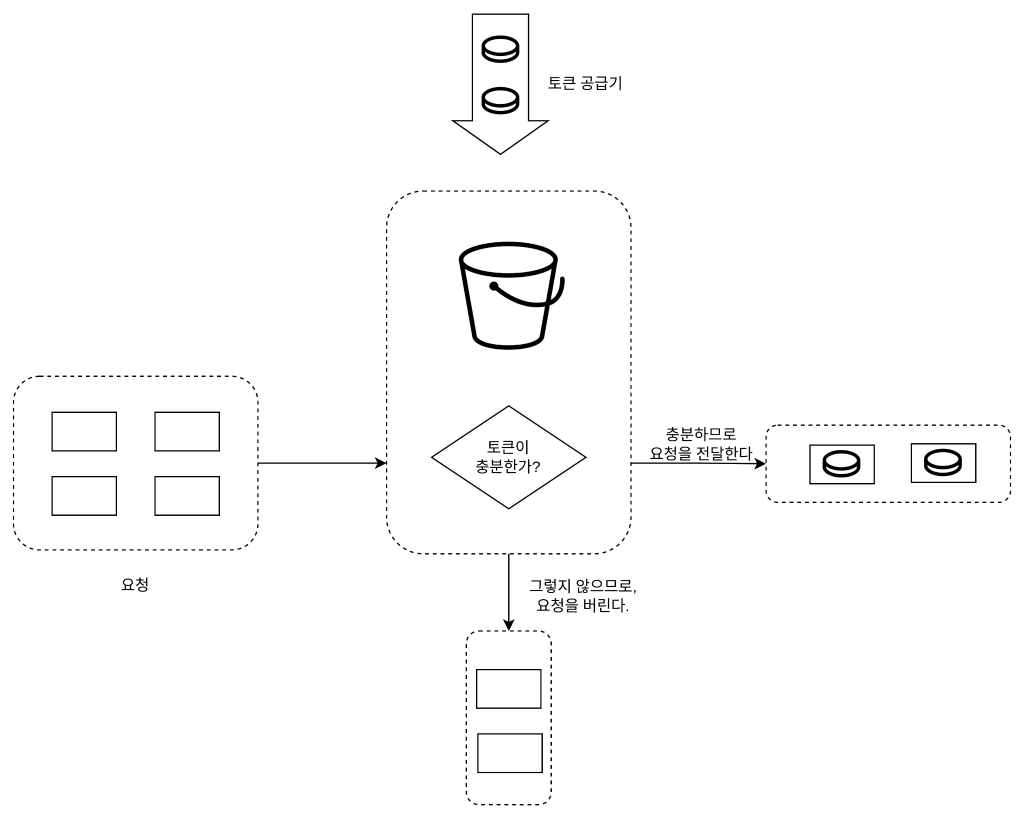
노큰 버킷 알고리즘은 2개 인자(parameter)를 받는다
버킷 크기: 버킷에 담을 수 있는 토큰의 최대 개수
토큰 공급률(refill rate): 초당 몇 개의 토큰이 버킷에 공급되는가
통상적으로, API 엔드포인트(endpoint)마다 별도의 버킷을 둔다.
IP 주소별로 처리율 제한을 적용해야 한다면 IP 주소마다 버킷을 하나씩 할당해야 한다.
시스템의 처리율을 초당 10,000개 요청으로 제한하고 싶다면, 모든 요청이 하나의 버킷을 공유하도록 해야 할 것이다.
장점
- 구현이 쉽다.
- 메모리 사용 측면에서도 효율적이다
- 짧은 시간에 집중되는 트래픽(burst of traffic)도 처리 가능하다. 버킷에 남은 토큰이 있기만 하면 요청은 시스템에 전달 될 것이다.
단점
- 인자 값을 튜닝하는 것이 까다로울 수 있다.
토큰 버킷 알고리즘에서 버킷을 다시 채워주는 과정이 있는데 주기적으로 모든 유저의 버킷을 다 확인해서 다시 채워주는건 코스트가 크지 않을까?
버킷이 꽉차있지 않은 사람들만 따로 목록으로 관리할까?https://www.linkedin.com/pulse/api-rate-limiting-using-token-bucket-algorithm-siddharth-patnaik/
consume을 시도할 때 refill을 함. 이 때 마지막 충전시간을 기준으로 현재 기준의 토큰 양을 재 계산함.
누출 버킷 알고리즘
누출 버킷(leaky bucket) 알고리즘은 토큰 버킷 알고리즘과 비슷하지만 요청 처리율이 고정되어 있다는 점이 다르다.
누출 버킷 알고리즘은 보통 FIFO(First In First Out) 큐로 구현한다.
Shopify가 이 알고리즘을 사용
동작원리
요청이 도착하면 큐가 가득 차 있는지 본다. 빈자리가 있는 경우에는 큐에 요청을 추가한다.
큐가 가득 차 있는 경우에는 새 요청은 버린다.
지정된 시간마다 큐에서 요청을 꺼내어 처리한다.
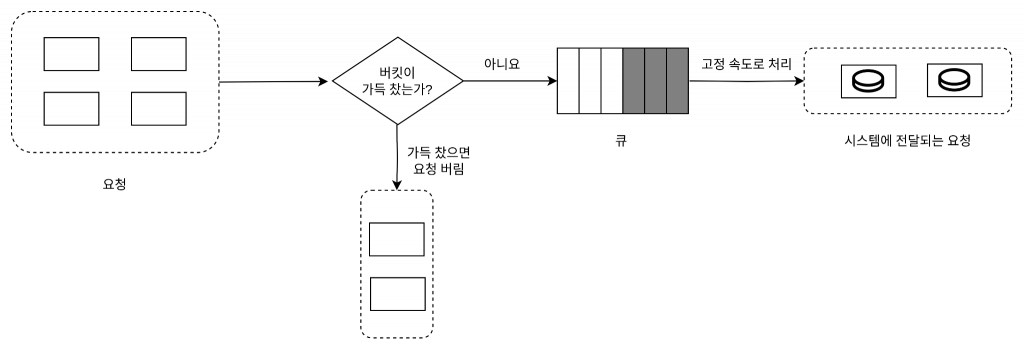
누출 버킷 알고리즘 에서 큐는 사용자마다 생성해주는 것인가?
누출 버킷 알고리즘에서 큐는 단일 시스템 또는 서비스 수준에서 사용되는 것이 일반적입니다. 각 사용자에 대한 개별 큐를 생성하는 것은 일반적으로 구현에 따라 다를 수 있지만, 일반적인 누출 버킷 알고리즘에서는 모든 사용자에 대해 개별 큐를 생성하지 않습니다. (GPT 답변)
누출 버킷 알고리즘은 2개 인자(parameter)를 받는다
버킷 크기: 큐 사이즈와 같은 값이다.
처리율(outflow rate): 지정된 시간당 몇 개의 항목을 처리할 지 지정하는 값이다. 보통 초 단위로 표현된다.
장점
- 큐의 크기가 제한되어 있어 메모리 사용량 측면에서 효율적이다.
- 고정된 처리율을 갖고 있기 때문에 안정적 출력(stable outflow rate)이 필요한 경우에 적합하다.
단점
- 단시간에 많은 트래픽이 몰리는 경우 큐에는 오래된 요청들이 쌓이게 되고, 그 요청들을 제때 처리 못하면 최신 요청들은 버려지게 된다.
- 인자 값을 튜닝하는 것이 까다로울 수 있다.
고정 윈도 카운터 알고리즘
고정 윈도 카운터(fixed window counter) 알고리즘은 다음과 같이 동작한다.
- 타임라인(timeline)을 고정된 간격의 윈도(window)로 나누고, 각 윈도마다 카운터(counter)를 붙인다.
- 요청이 접수될 때마다 이 카운터의 값은 1씩 증가한다.
- 이 카운터의 값이 사전에 설정된 임계치(threshold)에 도달하면 새로운 요청은 새 윈도가 열릴 때까지 버려진다.

장점
- 메모리 효율이 좋다.
- 이해하기 쉽다.
- 윈도가 닫히는 시점에 카운터를 초기화하는 방식은 특정한 트래픽 패턴을 처리하기에 적합하다.
단점
- 윈도 경계 부근에 순간적으로 많은 트래픽이 집중될 경우 윈도에 할당된 양보다 더 많은 요청이 처리될 수 있다 (최대 기대치의 2배 : 경계를 기준으로 이전에 할당된 양 + 이후에 할당된 양)
이동 윈도 로깅 알고리즘
고정 윈도 카운터 알고리즘의 단점을 개선
동작 과정
- 요청의 타임스탬프(timestamp)를 추적한다. 타임스탬프 데이터는 보통 레디스(Redis)의 정렬 집합(sorted set) 같은 캐시에 보관한다.
- 새 요청이 오면 만료된 타임스탬프는 제거한다. 만료된 타임스탬프는 그 값이 현재 윈도의 시작 시점보다 오래된 타임스탬프를 말한다.
- 새 요청의 타임스탬프를 로그(log)에 추가한다.
- 로그의 크기가 허용치보다 같거나 작으면 요청을 시스템에 전달한다. 그렇지 않은 경우에는 처리를 거부한다.
동작 예시
로그 허용 사이즈를 2로 가정한다.

① 1:00:01 에 도착한 요청은 로그가 비워있기 때문에 허용된다.
② 1:00:30 에 도착한 요청은 [0:59:30, 1:00:30) 범위 안에 있는 요청이 2개(로그 허용 사이즈) 보다 적기 때문에 허용된다.
③ 1:00:50 에 도착한 요청은 [0:59:50, 1:00:50) 범위 안에 있는 요청이 2개보다 많으므로 거부한다. (로그에는 남긴다.)
④ 1:01:40 에 도착한 요청은 [1:00:40, 1:01:40) 범위 안에 있는 요청이 2개보다 적으므로 허용한다. (만료된 요청의 타임스탬프(1:00:40 이전의 타임스탬프)로그는 지운다.)
1:00:50 의 경우 로그에는 남겨졌지만 시스템에는 전달되지 못한 요청이다.
거부된 요청은 해당 계산에 포함되지 않는다면 (개인적으로 포함되지 않는게 맞다고 생각되는데) 해당 부분에 대한 표시가 그림에 있었다면 더 좋았을 것 같다.
장점
- 이 알고리즘이 구현하는 처리율 제한 메커니즘은 아주 정교하다. 어느 순간의 윈도를 보더라도, 허용되는 요청의 개수는 시스템의 처리율 한도를 넘지 않는다.
단점
- 이 알고리즘은 다량의 메모리를 사용하는데, 거부된 요청의 타임스탬프도 보관하기 때문이다.
이동 윈도 카운터 알고리즘
이동 윈도 카운터(sliding window counter) 알고리즘은 고정 윈도 카운터 알고리즘과 이동 윈도 로깅 알고리즘을 결합한 것이다.
cloudflare가 이 알고리즘을 사용한다고 한다.
(출처 : https://medium.com/@avocadi/rate-limiter-sliding-window-counter-7ec08dbe21d6)
이동 윈도우 인 이유는 말그대로 윈도가 이동해서 이다.
예시를 통한 동작 과정 설명
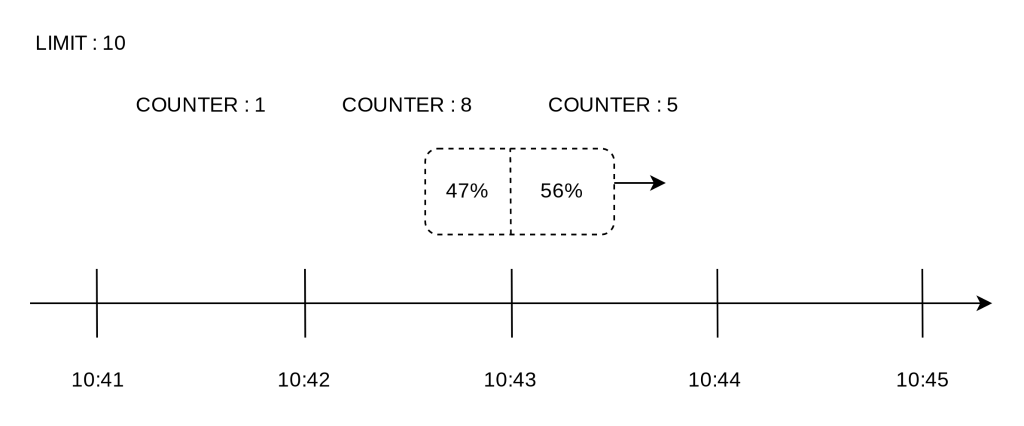
LIMIT은 10으로 잡는다.
현재 윈도 기준의 처리수를 계산하는 방법은 다음과 같다.
현재 1분간의 요청 수 + 직전 1분간의 요청 수 x 이동 윈도와 직전 1분이 겹치는 비율
위 이미지를 기준으로는 5 + 8 * 0.47 = 8.76 이다.
이동 윈도우 내의 처리수가 LIMIT인 10보다 적을경우 허용된다.
장점
- 이전 시간대의 평균 처리율에 따라 현재 윈도의 상태를 계산하므로 짧은 시간에 몰리는 트래픽에도 잘 대응한다.
- 메모리 효율이 좋다.
단점
- 직전 시간대에 도착한 요청이 균등하게 분포되어 있다고 가정한 상태에서 추정치를 계산하기 때문에 다소 느슨할 수 있다.
3단계 상세 설계
더 생각 해봐야 할 부분들
- 처리율 제한 규칙은 어떻게 만들어지고 어디에 저장되는가?
- 처리가 된 요청들은 어떻게 처리되는가?
- 분산 환경에서는 어떻게 처리할 것인가?
처리율 제한 규칙
처리율 제한 규칙은 보통 설정 파일 형태로 디스크에 저장된다.
리프트(Lyft, 미국의 승차 공유 서비스기업이다.)는 처리율 제한에 오픈 소스를 사용하고 있다.
https://github.com/envoyproxy/ratelimit
(Lyft 의 repository 였는데 envoyproxy로 옮겨졌다. envoy proxy에 대한 소개는 https://arisu1000.tistory.com/27864 여기에서 확인할 수 있다.)
아래는 규칙의 예시이다.
domain: auth
descriptors:
- key: auth_type
Value: login
rate_limit:
unit: minute
requests_per_unit: 5
처리율 한도 초과 트래픽의 처리
요청이 한도 제한에 걸리면 API는 HTTP 429 응답 (too many request)을 클라이언트에게 보낸다.
여기서 그냥 마무리 지을 수 있지만 나중에 처리하기 위해 큐에 보관할 수도 있다.
클라이언트는
처리율 제한에 걸리고 있는지를 어떻게 감지할 수 있나?
처리율 제한에 걸리기 까지 얼마나 요청을 보낼 수 있는지 어떻게 알 수 있나?
이러한 것들을 알 수 있도록 HTTP 응답 헤더 (response header)에 정보를 담아주면 좋다.
- X-Ratelimit-Remaining: 윈도 내에 남은 처리 가능 요청의 수
- X-Ratelimit-Limit: 매 윈도마다 클라이언트가 전송할 수 있는 요청의 수
- X-Ratelimit-Retry-After: 한도 제한에 걸리지 않으려면 몇 초 뒤에 요청을 다시 보내야 하는지 알림.
사용자가 너무 많은 요청을 보내면 429 오류를 X-Ratelimit-Retry-After 헤더와 함께 반환하자.
상세설계
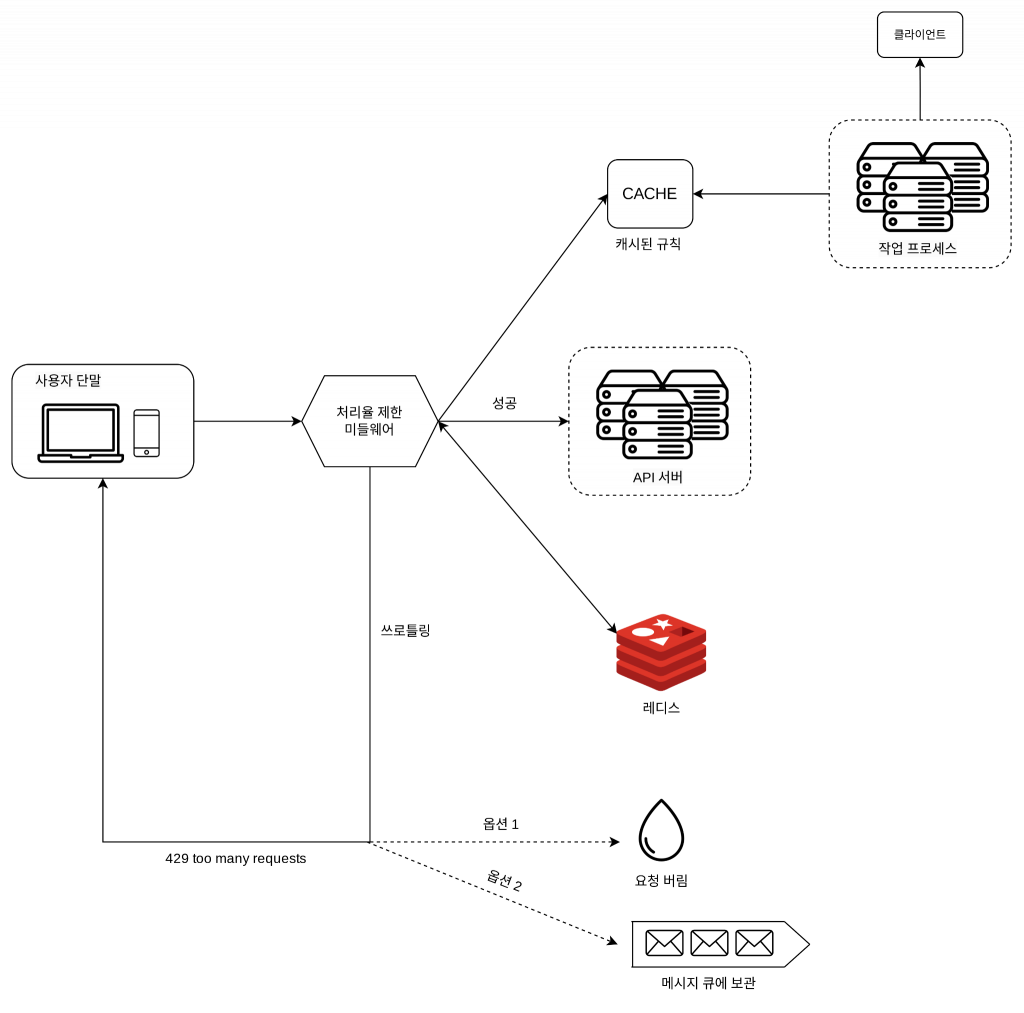
처리율 제한 규칙은 디스크에 보관한다. 작업 프로세스(workers)는 수시로 규칙을 디스크에서 읽어 캐시에 저장한다.
클라이언트가 요청을 서버에 보내면 요청은 먼저 처리율 제한 미들웨어에 도달한다.
처리율 제한 미들웨어는 제한 규칙을 캐시에서 가져온다. 아울러 카운터 및 마지막 요청의 타임스탬프(timestamp)를 레디스 캐시에서 가져온다. 가져온 값들에 근거하여 해당 미들웨어는 다음과 같은 결정을 내린다.
해당 요청이 처리율 제한에 걸리지 않은 경우에는 API 서버로 보낸다.
해당 요청이 처리율 제한에 걸렸다면 429 too many requests 에러를 클라이언트에 보낸다. 한편 해당 요청은 그대로 버릴 수도 있고 메시지 큐에 보관할 수도 있다.
분산 환경에서의 처리율 제한 장치의 구현
경쟁 조건
락을 하면 해결될 수 있으나, 시스템 성능을 상당히 떨어트림
루아 스크립트나 정렬 집합이라 불리는 레디스 자료구조를 써서 해결할 수 있다.
* 루아 스크립트는 레디스 서버 내에서 실행 가능한다.
관련 포스트 : Atomic 처리와 cache stampede 대책을 위해 Redis Lua script를 활용한 이야기
동기화
고정 세션을 활용하여 해결할 수 있으나 확장에 유연하지 않으므로 추천하지 않음.
레디스와 같은 중앙 집중형 데이터 저장소를 사용하는걸 추천
성능 최적화
- 에지 서버
- 최종 일관성 모델 사용 (6장에서 나올 예정)
모니터링
모니터링을 통해 확인하려는 것은 다음 두 가지이다.
- 채택된 처리율 제한 알고리즘이 효과적이다.
- 정의한 처리율 제한 규칙이 효과적이다.
4단계 마무리
시간이 허락된다면 다음과 같은 부부을 언급해보면 도움이 될 것이다.
경성(soft) 또는 연성(hard) 처리율 제한
경성 처리율 제한: 요청의 개수는 임계치를 절대 넘어설 수 없다.
연성 처리율 제한: 요청의 개수는 잠시 동안은 임계치를 넘어설 수 있다.
다양한 계층에서의 처리율 제한
지금까지의 설명은 OSI 7계층의 애플리케이션 계층을 기준으로 설명한 것이다.
다른 계층에서도 처리율 제한이 가능하다.
(ex. OSI 3번 계층, iptables를 사용하여 IP주소에 처리율 제한을 적용할 수 있음.)
[참고] OSI 계층
- 1 물리
- 2 데이터 링크
- 3 네트워크
- 4 전송
- 5 세션
- 6 표현(presentation)
- 7 애플리케이션
처리율 제한을 회피하는 방법. 클라이언트를 어떻게 설계하는 것이 최선인가.
- 클라이언트 측 캐시를 사용하여 API 호출 횟수를 줄인다.
- 처리율 제한의 임계치를 이해하고, 짧은 시간 동안 너무 많은 메시지를 보내지 않도록 한다.
- 예외나 에러를 처리하는 코드를 도입하여 클라이언트가 예외적 상황으로부터 우아하게(gracefully) 복구될 수 있도록 한다.
- 재시도(retry) 로직을 구현할 때는 충분한 백오프(back-off, 지연) 시간을 둔다.