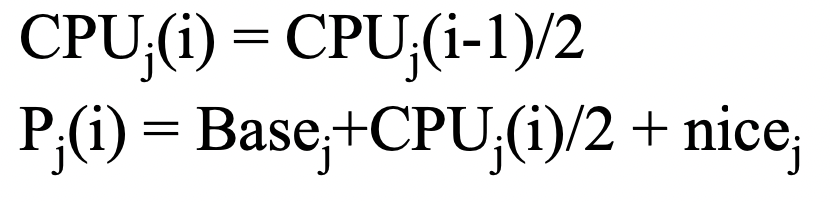운영체제 5장 CPU 스케줄링 - 연습문제 풀이
- 5.1 CPU 스케줄링 알고리즘은 스케줄 된 프로세스의 실행 순서를 결정한다. 하나의 프로세서에게 n개의 프로세스를 스케줄 하면 몇 개의 다른 스케줄이 가능한가? n에 대한 공식을 제시하라.**
- 5.2 선점 스케줄링과 비선점 스케줄링의 차의점을 설명하라.
- 5.3 표시된 시간에 다음 프로세스가 도착한다고 가정하자. 각 프로세스는 나열된 시간 동안 실행된다. 질문에 답할 때, 비선점 스케줄링을 사용하고 결정을 해야할 시점에 가지고 있는 정보를 기초로 결정을 내려야 한다.
- 1. FCFS 스케줄링 알고리즘을 사용할 경우 프로세스의 평균 총처리 시간은 얼마인가?
- 2. SJF 스케줄링 알고리즘을 사용할 경우 프로세스의 평균 총처리 시간은 얼마인가?
- 3. SJF 알고리즘은 성능을 향상해야 하지만 두 개의 더 짧은 프로세스가 곧 도착할 것임을 알지 못했기 때문에 시간 0에서 프로세스 P1을 실행하기로 선택했다. CPU가 첫 1 단위 동안에 유휴상태로 유지된 후 SJF 스케줄링이 사용되는 경우 평균 총처리 시간을 계산하라. 이 유휴시간 동안 프로세스 P1 및 P2가 대기중이므로 대기 시간이 증가할 수 있다. 이 알고리즘은 미래-지식 스케줄링으로 알려져 있다.
- 5.4 CPU 버스트 시간의 길이가 밀리초 단위로 다음과 같은 프로세스 집합을 고려하시오.
- 5.5 다음 프로세스는 선점형 라운드-로빈 스케줄링 알고리즘을 사용하여 스케줄링 된다.
- 5.6 다단계 큐 시스템에서 단계마다 다른 시간 할당량을 지정하는 것은 어떤 이점이 있는가?
- 5.7 많은 CPU 스케줄링 알고리즘이 매개변수화 된다. 예를 들어, RR 알고리즘에는 타임 슬라이스를 나타내는 매개변수가 필요하다.
- 5.8 CPU 스케줄링 알고리즘이 최근 과거에 가장 적은 프로세서 시간을 사용한 프로세스를 선호한다고 가정한다. 이 알고리즘이 I/O 중심 프로그램을 선호하지만 CPU 중심 프로그램을 영구적인 기아 상태로 만들지 않는 이유는 무엇인가?
- 5.9 PCS와 SCS 스케줄링을 구별하라.
- 5.10 전통적인 UNIX 스케줄러는 우선순위 번호와 우선순위 사이에 반비례 관계를 강제한다. 숫자가 높을수록 우선순위가 낮다. 스케줄러는 일 초마다 다음 수식을 사용하여 프로세스 우선순위를 다시 계산한다.
공룡책 (Operating System Concepts) 10th
개인적인 생각이므로 틀린 답변일 수 있습니다.
5.1 CPU 스케줄링 알고리즘은 스케줄 된 프로세스의 실행 순서를 결정한다. 하나의 프로세서에게 n개의 프로세스를 스케줄 하면 몇 개의 다른 스케줄이 가능한가? n에 대한 공식을 제시하라.**
n! = n x (n-1) x (n-2) x … x 2 x 1
첫 프로세스를 선택하는 경우의 수 : n
두번째 프로세스를 선택하는 경우의 수 : n - 1
세번째 프로세스를 선택하는 경우의 수 : n - 2…
이런식으로 쭉 이어나가면 위에 공식에 적은 것 처럼 n! (팩토리얼) 이 된다.
5.2 선점 스케줄링과 비선점 스케줄링의 차의점을 설명하라.
선점 스케줄링 : 현재 실행 중인 프로세스를 상황에 따라 인터럽트를 통해 다른 프로세스가 CPU를 사용할 수 있도록 스위칭 하는 방식
비선점 스케줄링 : 현재 실행 중인 프로세스가 완료되거나 대기 상태에 빠질 때까지 CPU를 계속 사용하는 방식
5.3 표시된 시간에 다음 프로세스가 도착한다고 가정하자. 각 프로세스는 나열된 시간 동안 실행된다. 질문에 답할 때, 비선점 스케줄링을 사용하고 결정을 해야할 시점에 가지고 있는 정보를 기초로 결정을 내려야 한다.
| 프로세스 | 도착시간 | 버스트 시간 |
|---|---|---|
| P1 | 0.0 | 8 |
| P2 | 0.4 | 4 |
| P3 | 1.0 | 1 |
1. FCFS 스케줄링 알고리즘을 사용할 경우 프로세스의 평균 총처리 시간은 얼마인가?
총처리 시간 : 준비 큐에서 대기한 시간 + CPU에서 실행하는 시간 + I/O 시간을 합한 시간
여기서 I/O 시간에 대해서는 고려하지 않으므로
P1 : 0 + 8 = 8
P2 : 7.6(: 8 - 0.4) + 4 = 11.6
P3 : 11(: 12 - 1) + 1 = 12
(P1 + P2 + P3) / 3 = (8 + 11.6 + 12) / 3 = 10.533333…
2. SJF 스케줄링 알고리즘을 사용할 경우 프로세스의 평균 총처리 시간은 얼마인가?
SJF : Shortest Job First Scheduling
P1이 제일 먼저 도착하므로 P1을 먼저 처리한다.
이후 P2 P3 가 도착하는데 여기서 버스트 타임이 P3가 더 짧으므로 처리 순서는 P1 - P3 - P2 가 된다.이를 고려하여 총처리 시간을 계산해보면 다음과 같다.
P1 : 0 + 8 = 8
P3 : 7(8 - 1) + 1 = 8
P2 : 8.6(9 - 0.4) + 4 = 12.6
(P1 + P2 + P3) / 3 = (8 + 8 + 12.6) / 3 = 9.53333333
3. SJF 알고리즘은 성능을 향상해야 하지만 두 개의 더 짧은 프로세스가 곧 도착할 것임을 알지 못했기 때문에 시간 0에서 프로세스 P1을 실행하기로 선택했다. CPU가 첫 1 단위 동안에 유휴상태로 유지된 후 SJF 스케줄링이 사용되는 경우 평균 총처리 시간을 계산하라. 이 유휴시간 동안 프로세스 P1 및 P2가 대기중이므로 대기 시간이 증가할 수 있다. 이 알고리즘은 미래-지식 스케줄링으로 알려져 있다.
P1 이 먼저 선택된 후
CPU가 첫 1 단위 동안에 유휴상태로 유지된 후 SJF 스케줄링이 사용된다고 하였다.
P2, P3 가 모두 도착 한 후 스케줄링이 진행되게 된다.
그러면 실행 순서는 유휴 - P3 - P2 - P1 이 될 것이며
이 때 대기 시간을 고려하라고 하였기 때문에 총처리 시간은 다음과 같다.P3 : 1 + 1 = 2
P2 : 1.6(2 - 0.4) + 4 = 5.6
P1 : 5(6 - 1(유휴시간)) + 8 = 13(P1 + P2 + P3) / 3 = (2 + 5.6 + 13) / 3 = 6.86666….
5.4 CPU 버스트 시간의 길이가 밀리초 단위로 다음과 같은 프로세스 집합을 고려하시오.
| 프로세스 | 버스트 시간 | 우선순위 |
|---|---|---|
| P1 | 2 | 2 |
| P2 | 1 | 1 |
| P3 | 8 | 4 |
| P4 | 4 | 2 |
| P5 | 5 | 3 |
프로세스는 모두 시간 0에서 P1,P2,P3,P4,P5 순서로 도착한 것으로 가정한다.
1. PCFS, SJF, 비 선점 우선순위(높은 우선순위가 높을수록 우선순위가 높음) 및 RR(양자 = 2)을 사용하여 이러한 프로세스의 실행을 설명하는 4개의 Gantt 차트를 그려라.
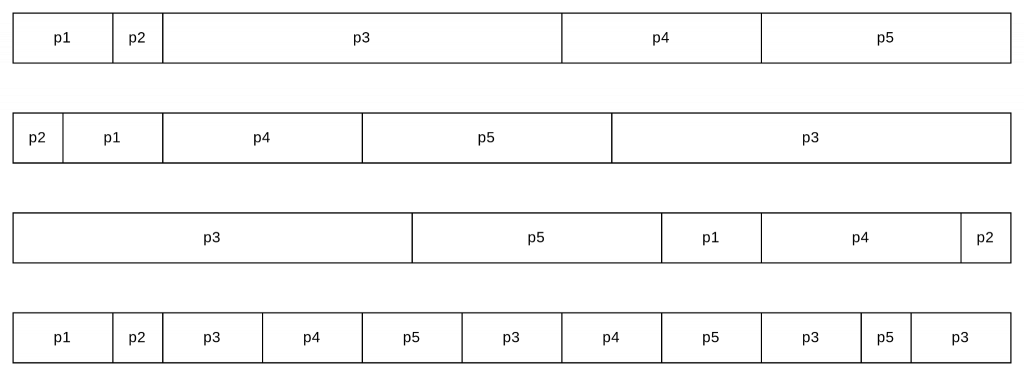
2. a 부분에서 각 스케줄링 알고리즘에 대한 각 프로세스의 처리 시간은 얼마인가?
| FCFS | SJF | Priority | RR | |
|---|---|---|---|---|
| P1 | 2 | 3 | 15 | 2 |
| P2 | 3 | 1 | 20 | 3 |
| P3 | 11 | 20 | 8 | 20 |
| P4 | 15 | 7 | 19 | 13 |
| P5 | 20 | 12 | 13 | 18 |
3. 이러한 각 스케줄링 알고리즘에 대한 각 프로세스의 대기 시간은 얼마인가?
| FCFS | SJF | Priority | RR | |
|---|---|---|---|---|
| P1 | 0 | 1 | 13 | 0 |
| P2 | 2 | 0 | 19 | 2 |
| P3 | 3 | 12 | 0 | 12 |
| P4 | 11 | 3 | 15 | 9 |
| P5 | 15 | 7 | 8 | 13 |
4. 어떤 알고리즘이 최소 평균대기 시간을 보이는가(모든 프로세스에서)?
SJF
5.5 다음 프로세스는 선점형 라운드-로빈 스케줄링 알고리즘을 사용하여 스케줄링 된다.
| 프로세스 | 우선순위 | 버스트 | 시간 |
|---|---|---|---|
| P1 | 40 | 20 | 0 |
| P2 | 30 | 25 | 25 |
| P3 | 30 | 25 | 30 |
| P4 | 35 | 15 | 60 |
| P5 | 5 | 10 | 100 |
| P6 | 10 | 10 | 105 |
각 프로세스에는 숫자 우선순위가 할당되며 숫자가 높을수록 상대적 우선순위가 더 높다. 아래에 나열된 프로세스 외에도 시스템에는 유휴 작업(CPU 자원을 소비하지 않으면 P**idle**로 식별됨)이 있다. 이 작업의 우선순위는 0이며 시스템의 실행 가능한 다른 프로세스가 없을 때마다 스케줄 된다. 시간 할당량의 길이는 10단위이다. 프로세스가 우선순위가 높은 프로세스에 의해 선점되면 선점된 프로세스는 큐의 끝에 배치된다.
1. Gantt 차트를 사용하여 프로세스의 스케줄 순서를 보여라.

2. 각 프로세스에 소요되는 총처리 시간은 얼마인가?
P1: 20 = 20
P2: 80 - 25 = 55
P3: 90 - 30 = 60
P4: 75 - 60 = 15
P5: 120 - 100 = 20
P6 : 115 - 105 = 10
3. 각 프로세스의 대기 시간은 얼마인가?
P1: 0
P2: 80 - 25 - 25 = 30
P3: 90 - 30 - 25 = 35
P4: 75 - 60 - 15 = 0
P5: 120 - 100 - 10 = 10
P6: 115 - 105 - 10 = 0
4. CPU 이용률은 얼마인가?
105 / 120 = 87.5%
5.6 다단계 큐 시스템에서 단계마다 다른 시간 할당량을 지정하는 것은 어떤 이점이 있는가?
우선순위에 따라 큐가 생성이 되기 때문에 대기시간을 조절할 수 있음. 빠르게 처리해야 하는 것들은 최대한 적게 대기하도록, 천천히 처리해도 되는 것들은 대기시간을 크게 잡아 여유롭게 처리할 수 있게 할 수 있음.
5.7 많은 CPU 스케줄링 알고리즘이 매개변수화 된다. 예를 들어, RR 알고리즘에는 타임 슬라이스를 나타내는 매개변수가 필요하다.
다단계 피드백 큐에는 큐의 수, 각 큐의 스케줄링 알고리즘, 큐 간 프로세스 이주에 사용되는 기준 등을 정의하는 매개변수가 필요하다. 따라서 이러한 알고리즘은 실제로는 알고리즘 집합이다(예, 모든 타임 슬라이스에 대한 RR 알고리즘 집합 등).
한 알고리즘 집합은 다른 집합을 포함할 수 있다(예를 들어, FCFS은 무한 시간 할당량을 갖는 RR 알고리즘이다). 다음 알고리즘 집합 쌍 사이에는 어떤 관계가 있는가?
1. 우선순위 및 SJF
Shortest Job 이 가장 큰 우선순위를 가진다.
2. 다단계 피드백 큐 및 FCFS
다단계 피드백 큐에서 새로 진입하는 프로세스는 큐 0에 넣어져 FCFS 처럼 공작된다.
3. 우선순위 및 FCFS
빨리 도착한 프로세스가 가장 큰 우선순위를 가진다.
4. RR과 SJF
없음
5.8 CPU 스케줄링 알고리즘이 최근 과거에 가장 적은 프로세서 시간을 사용한 프로세스를 선호한다고 가정한다. 이 알고리즘이 I/O 중심 프로그램을 선호하지만 CPU 중심 프로그램을 영구적인 기아 상태로 만들지 않는 이유는 무엇인가?
이 질문은 CFS 스케줄러에 대한 내용으로 보이며 다음과 같이 나와있다. (p261)
입출력 중심 태스크는 추가의 입출력을 위하여 짧은 시간 실행되고 봉쇄되며 CPU 중심 태스크는 처리기 위에서 실행될 기회를 얻을 때마다 시간 주기를 전부 소진하려고 한다. 따라서 입출력 중심 태스크의 vruntime 값은 CPU 중심 태스크의 vruntime 값보다 작아지게 되어, 입출력 중심 태스크가 CPU 중심 태스크보다 우선순위가 높아지게 된다. 이 상황에서 입출력 중심 태스크가 실행 가능해지면(예를 들어, 태스크가 기다리던 입출력이 완료되면) 현재 실행 중인 CPU 중심 태스크를 선점하게 된다.
[용어 정리]
CFS 스케줄러 : 완전 공평 스케줄러
vruntime : 가상 실행 시간(프로세스가 그동안 실행한 시간을 정규화한 시간 정보)
CFS 스케줄러는 런큐에 등록된 프로세스 중 vruntime 이 가장 적은 프로세스를 다음에 실행할 프로세스로 선택한다.
5.9 PCS와 SCS 스케줄링을 구별하라.
• PCS : 같은 프로세스에 속한 스레드들 사이에서 CPU 경쟁
• SCS : 시스템상의 모든 스레드 사이에서 CPU 경쟁
5.10 전통적인 UNIX 스케줄러는 우선순위 번호와 우선순위 사이에 반비례 관계를 강제한다. 숫자가 높을수록 우선순위가 낮다. 스케줄러는 일 초마다 다음 수식을 사용하여 프로세스 우선순위를 다시 계산한다.
Priority = (recent CPU usage / 2) + base
여기서 base = 60이고 recent CPU usage는 우선순위가 마지막으로 다시 계산된 이후 프로세서가 CPU를 사용한 빈도를 나타내는 값이다.
프로세스 P1의 최근 CPU 사용량이 40이고 프로세스 P2의 경우 18, 프로세스 P3의 경우 10이라고 가정한다. 우선순위를 다시 계산할 때 이 세 프로세스의 새로운 우선순위는 무엇인가? 이 정보를 기반으로 판단했을 때 전통적인 UNIX 스케줄러가 CPU 중심 프로세스의 상대적 우선순위를 올리는가 아니면 내리는가?
책을 봐도 인터넷을 뒤져봐도 자료가 없어서 이 문제를 푸는데 가장 많은 시간이 걸렸다.
그냥 생략할까 하다가 계속 머리속에 걸려서 다시 보게 되었다.
P1 : 40 / 2 + 60 = 80
P2 : 18 / 2 + 60 = 69
P3 : 10 / 2 + 60 = 65
계속 찾다 아래의 글을 찾게 되었다.
문제에서는 여기서 base 라고만 나오긴 했지만 여기서 base는 base priority 이다. 따라서 Base Priority 보다 값이 커졌기 때문에 우선순위가 낮아지게 된다.