사용자 수에 따른 규모 확장성 (4) – 무상태 웹 계층, 데이터 센터
가상 면접 사례로 배우는 대규모 시스템 설계 기초 - System Design Interview
1장 사용자 수에 따른 규모 확장성 : 어떻게 수백만 사용자를 지원하는 시스템을 설계할 것인가.
무상태(stateless) 웹 계층
Q : 어떻게 웹 계층을 수평적으로 확장할 것인가
A : 바람직한 전략 : 상태 정보를 관계형 데이터베이스나 NoSQL 같은 지속성 저장소에 보관하고, 필요할 때 가져오도록 한다.
→ 이렇게 구성된 웹 계층을 무상태 웹 계층 이라 부른다.
상태 의존적인 아키텍처
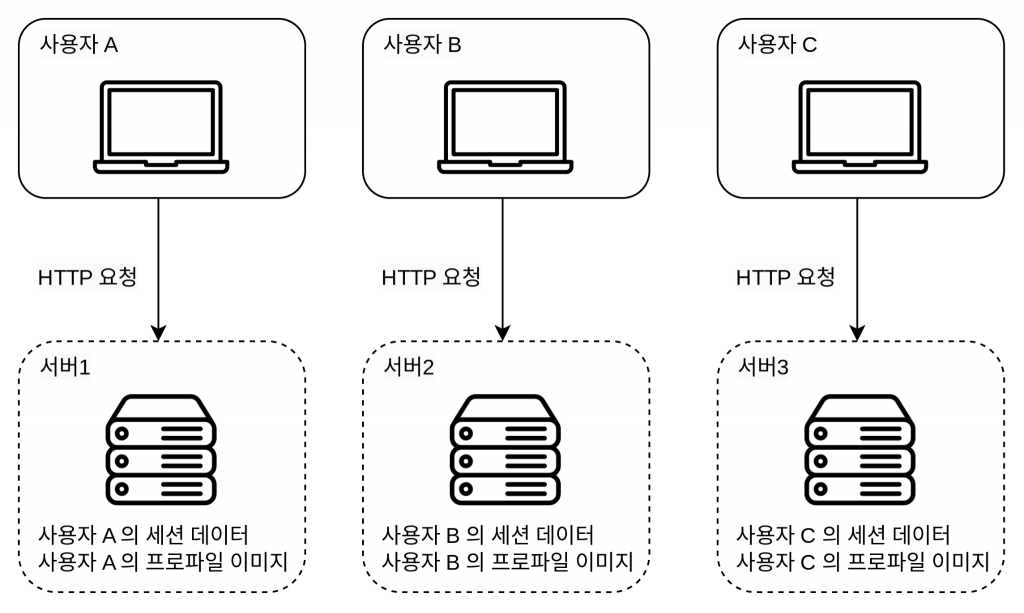
상태 의존적인 아키텍처에서는 클라이언트의 요청이 항상 같은 서버로 전송되어야 한다. 로드밸런서에서는 이를 지원하기 위해 고정 세션(sticky session)이라는 기능을 제공하는데 이는 로드밸런서에 부담을 준다. 게다가 서버를 추가하거나 제거하기도 까다로워지기 때문에 서버의 장애를 처리하기도 복잡해진다.
무상태 아키텍처
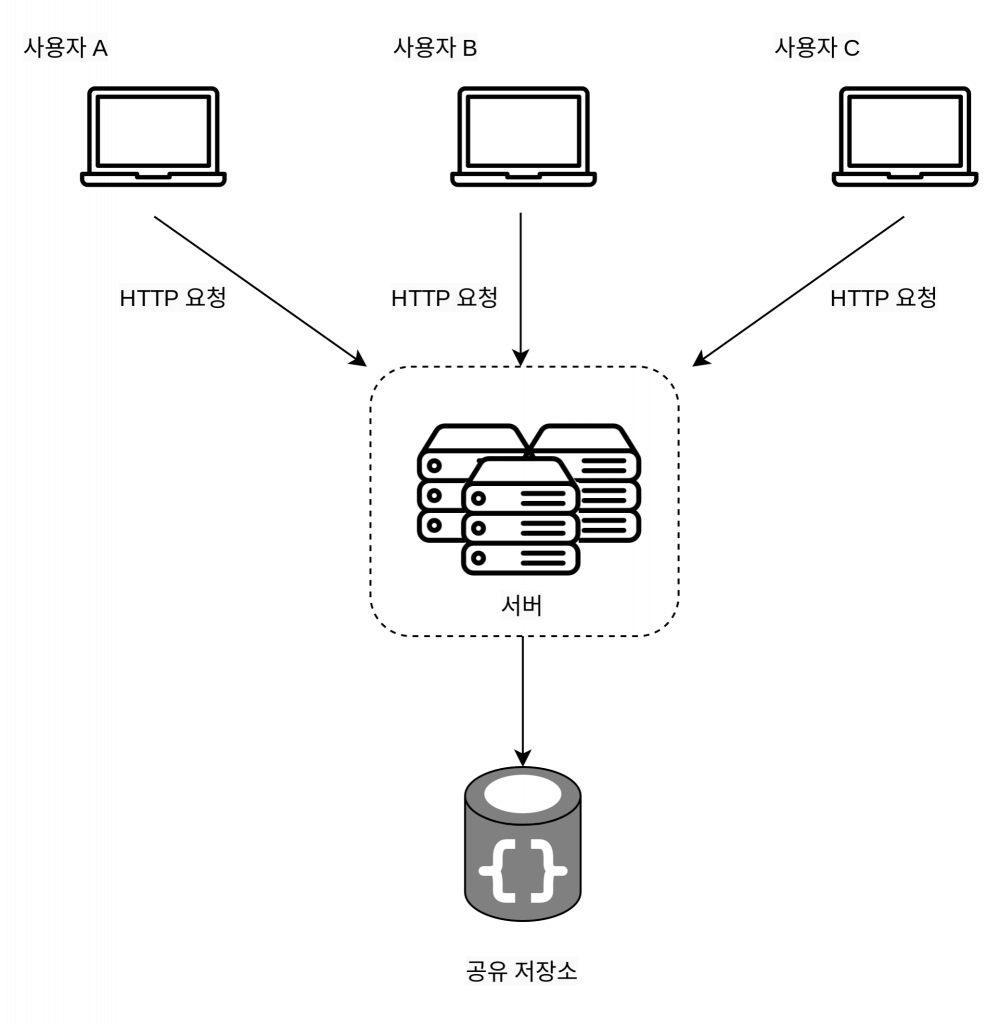
이 구조에서는 사용자로부터의 HTTP 요청이 어떤 웹 서버로도 전달될 수 있다.
단순하고, 안정적이며, 규모 확장이 쉽다.
* JWT도 무상태 아키텍처로 볼 수 있다.
여기까지의 시스템 구성도
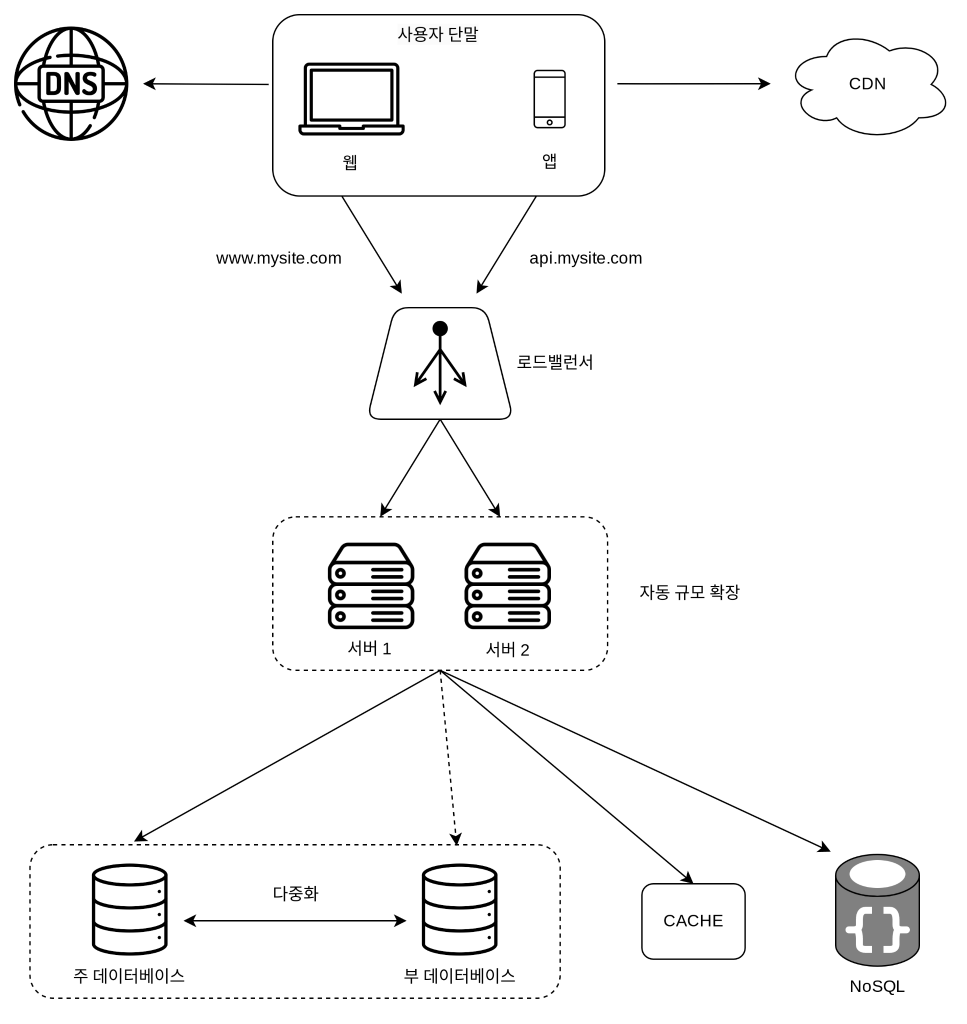
공유 저장소는 Memcached/Redis 같은 캐시 시스템일 수도 있으며, NoSQL일 수도 있으나 여기서는 규모 확장의 편의성을 위해 NoSQL을 선택하였다.
이제는 트래픽 양에 따라 웹 서버를 넣거나 빼기만 하면 자동으로 규모를 확장할 수 있는 구조가 되었다.
여기서는 별도의 저장소로 표현을 하였는데 JWT (JSON Web Tokens) 를 이용하는 것도 무상태 웹 계층을 구성하는데 사용할 수 있을 것이다.
데이터 센터
전 세계에서 쾌적하게 접근할 수 있는 서비스를 만들어보자.
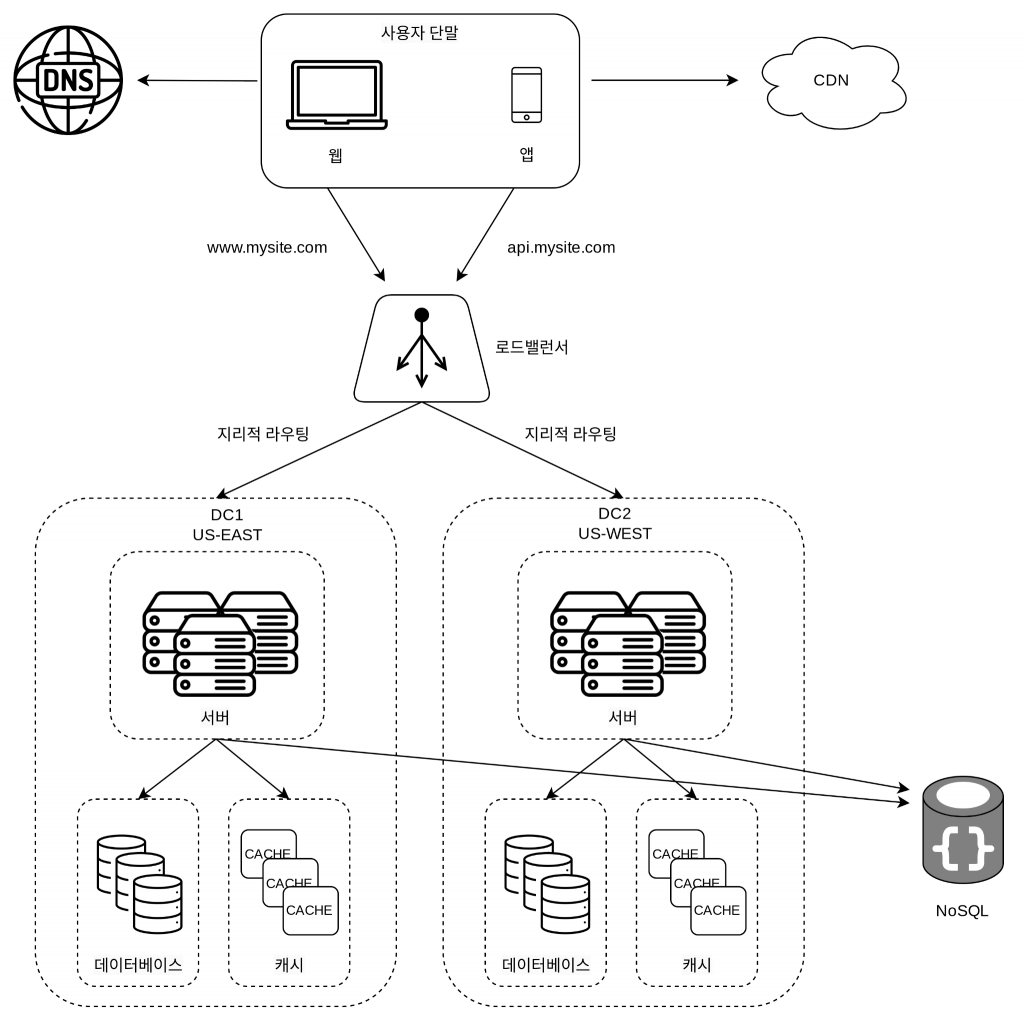
장애가 없는 상황에서는 가장 가까운 데이터 센터로 안내된다.
이를 지리적 라우팅 (geoDNS-routing 또는 geo-routing) 이라고 부른다.
사용자의 위치에 따라 도메인 이름을 어떤 IP로 반환할지 결정할 수 있도록 해 주는 DNS 서비스다.
데이터 센터 중 하나에 심각한 장애가 발생하면 모든 트래픽은 장애가 없는 데이터 센터로 전송된다.
다중 데이터센터 아키텍처를 만들기 위한 기술적 난제들
트래픽 우회
올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야 한다.데이터 동기화
센터마다 별도의 데이터베이스를 사용하고 있다면 트래픽이 다른 데이터베이스로 우회된다고 해도 해당 데이터센터에는 찾는 데이터가 없을 수 있음.
이를 방지하기 위해 데이터를 여러 데이터센터에 걸쳐 다중화 함.테스트와 배포
테스트는 여러 위치에서 해봐야 함.
배포는 자동화된 배포 도구로 모든 데이터 센터에 동일한 서비스가 설치되도록 해야 함.